神经网络学习小记录49——Pytorch当中Tensorboard的使用
学习前言
很多人问Pytorch要怎么可视化,于是决定搞一篇。

所需库的安装
tensorboardX==2.0
tensorflow==1.13.2
由于tensorboard原本是在tensorflow里面用的,所以需要装一个tensorflow。会自带一个tensorboard。
也可以不装tensorboardX,直接使用pytorch当中的自带的Tensorboard。
导入方式如下:
from torch.utils.tensorboard import SummaryWriter
不过由于我使用pytorch当中的自带的Tensorboard的时候有一些bug。所以还是使用tensorboardX来写这篇博客。
常用函数功能
1、SummaryWriter()
这个函数用于创建一个tensorboard文件,其中常用参数有:
- log_dir:tensorboard文件的存放路径
- flush_secs:表示写入tensorboard文件的时间间隔
调用方式如下:
writer = SummaryWriter(log_dir='logs',flush_secs=60)
2、writer.add_graph()
这个函数用于在tensorboard中创建Graphs,Graphs中存放了网络结构,其中常用参数有:
- model:pytorch模型
- input_to_model:pytorch模型的输入
如下所示为graphs:

调用方式如下:
if Cuda:
graph_inputs = torch.from_numpy(np.random.rand(1,3,input_shape[0],input_shape[1])).type(torch.FloatTensor).cuda()
else:
graph_inputs = torch.from_numpy(np.random.rand(1,3,input_shape[0],input_shape[1])).type(torch.FloatTensor)
writer.add_graph(model, (graph_inputs,))
3、writer.add_scalar()
这个函数用于在tensorboard中加入loss,其中常用参数有:
- tag:标签,如下图所示的Train_loss
- scalar_value:标签的值
- global_step:标签的x轴坐标
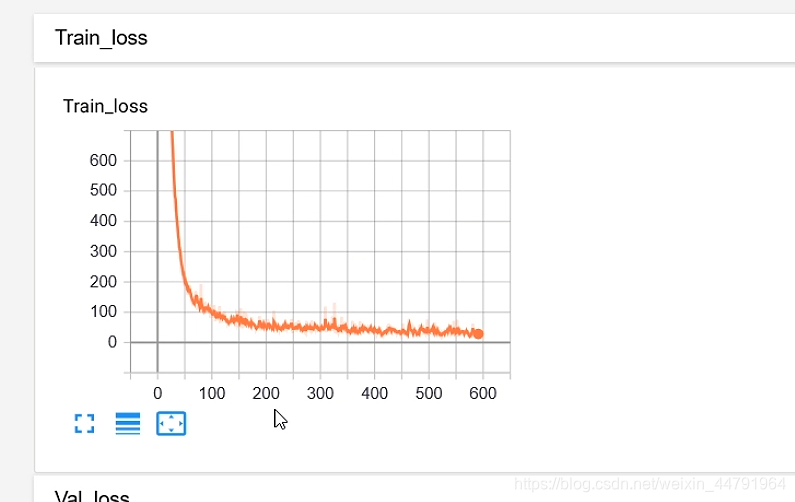
调用方式如下:
writer.add_scalar('Train_loss', loss, (epoch*epoch_size + iteration))
4、tensorboard --logdir=
在完成tensorboard文件的生成后,可在命令行调用该文件,tensorboard网址。
具体代码如下:
tensorboard --logdir=D:\Study\Collection\Tensorboard-pytorch\logs

示例代码
import torch
from torch.autograd import Variable
import torch.nn.functional as functional
from tensorboardX import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
# x的shape为(100,1)
x = torch.from_numpy(np.linspace(-1,1,100).reshape([100,1])).type(torch.FloatTensor)
# y的shape为(100,1)
y = torch.sin(x) + 0.2*torch.rand(x.size())
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
# Applies a linear transformation to the incoming data: :math:y = xA^T + b
# 全连接层,公式为y = xA^T + b
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
# 隐含层的输出
hidden_layer = functional.relu(self.hidden(x))
output_layer = self.predict(hidden_layer)
return output_layer
# 类的建立
net = Net(n_feature=1, n_hidden=10, n_output=1)
writer = SummaryWriter('logs')
graph_inputs = torch.from_numpy(np.random.rand(2,1)).type(torch.FloatTensor)
writer.add_graph(net, (graph_inputs,))
# torch.optim是优化器模块
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
# 均方差loss
loss_func = torch.nn.MSELoss()
for t in range(1000):
prediction = net(x)
loss = loss_func(prediction, y)
# 反向传递步骤
# 1、初始化梯度
optimizer.zero_grad()
# 2、计算梯度
loss.backward()
# 3、进行optimizer优化
optimizer.step()
writer.add_scalar('loss',loss, t)
writer.close()
效果如下:
