摘自:https://spinningup.readthedocs.io/zh_CN/latest/user/algorithms.html
为什么介绍这些算法?
我们在这个项目中选取了能够呈现强化学习近些年发展历程的核心算法。目前,在 可靠性 (stability)和 采样效率 (sample efficiency)这两个因素上表现最优的策略学习算法是 PPO 和 SAC。从这些算法的设计和实际应用中,可以看出可靠性和采样效率两者的权衡。
同策略(On-Policy)算法
Vanilla Policy Gradient(VPG) 是深度强化学习领域最基础也是入门级的算法,发表时间远早于深度强化学习。VPG 算法的核心思想可以追溯到上世纪 80 年代末、90年代初。在那之后,TRPO(2015)和 PPO(2017) 等更好的算法才相继诞生。
上述系列工作都是基于不使用历史数据的同策略,因此在采样效率上表现相对较差。但这也是有原因的:它们直接优化我们关心的目标 —— 策略表现。这个系列的算法都是用采样效率换取可靠性,之后提出的算法,从 VPG 到TRPO 再到 PPO,都是在不断弥补采样效率方面的不足。
异策略(Off-Policy)算法
DDPG 是一个和 VPG 同样重要的算法,尽管它的提出时间较晚。确定策略梯度(Deterministic Policy Gradients,DPG)理论是在 2014 年提出的,是 DDPG 算法的基础。DDPG 算法和 Q-learning 算法很相似,都是同时学习 Q 函数和策略并通过更新相互提高。
DDPG 和 Q-Learning 属于 异策略 算法,他们通过对贝尔曼方程(Bellman’s equations,也称动态规划方程)的优化,实现对历史数据的有效利用。
但问题是,满足贝尔曼方程并不能保证一定有很好的策略性能。从经验上讲,满足贝尔曼方程可以有不错的性能、很好的采样效率,但也由于没有这种必然性的保证,这类算法没有那么稳定。基于 DDPG的后续工作 TD3 和 SAC 提出了很多新的方案来缓解这些问题。
强化学习算法的分类
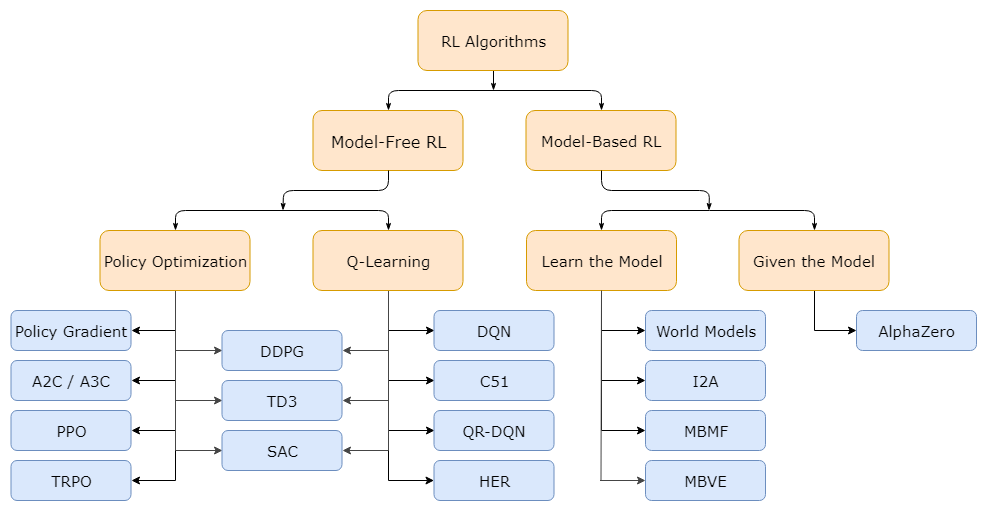
一个不是很详细但是十分有用的现代强化学习算法分类