HashMap
HashMap的底层实现
JDK1.7 由数组+链表 ,在JDK1.8由数组+链表+红黑树
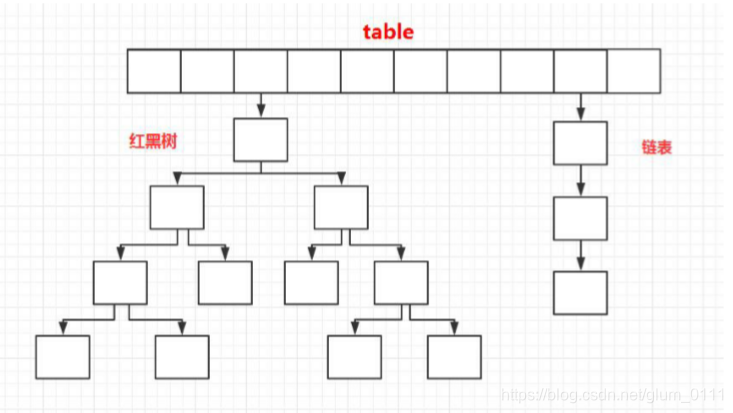
将entry<key,value>的键值对存储在table[]中,当key值相同时,用链表的形式存储。再JDK1.8里,当链表长度超过8时,会转化为红黑树存储,便于查找。
- 为什么JDK1.8要使用红黑树?为什么不一开始就使用红黑树?
链表中节点数到8的概率很低,此时用链表的查询效率已经很低了(线性),使用红黑树可以提高查询效率(Olgn)。树节点占用的内存是不同节点的两倍,在节点太多的时候才会因为效率使用红黑树。
HashMap的扩容
-
如何扩容?扩容成多少?HashMap扩容的时机?
HashMap默认的初始大小是16,之后每次扩容的大小是之前的两倍(newsize = oldsize*2)。在JDK1.8,当HashMap的元素个数超过了数组大小x负载因子(LoadFactor,默认0.75)就会对数组进行扩容。而在JDK1.7,还会看当前数组位置是否为空,如果数组为空,元素个数大于阈值也不会扩容。 -
HashMap的长度为什么要是2的幂次方?
便于计算。HashMap是将key的hash值%数组长度的结果作为数组下标存放键值对,在取余操作中,如果被除数是2的幂次方,等价其与除数-1做&运算。相当于hash%length = hash&(length-1),&计算更快。
-扩容重新计算位置时,JDK1.7和1.8的区别?
JDK1.7:计算Hash值,与数组长度确定下标
JDK1.8:原位置+原位置数组长度(要么在原位置,要么在原位置的二次幂位置) -
为什么JDK1.8扩容的时候不用Hash运算?
扩容的长度是2的倍数,&操作的时候-1,这样&操作影响结果的只有最高位。举个栗子:数据A的Hash值15(1111),扩容前数组长度8(1000),扩容后数组长度16 (10000),hash&(length-1)计算。
原位置:1111&0111=0111 扩容后位置:1111&1111= 1111 = 1000(原数组长度)+0111(原位置),此时hash&扩容前长度=1111&1000 != 0。也就是说,JDK1.8中,确定扩容的位置只需要用hash&原数组大小判断结果是否为0即可(为0,位置不变;不为0,原位置+原数组长度)。非常的巧妙、高效,可以自行去验证。 -
扩容产生的死锁
比较复杂,参考博客
参考博客链接.
HashMap的工作原理
HashMap基于hashing原理,我们使用put(key,value)存储对象到HashMap,使用get(key)来获取对象。当使用put()时,先对key调用hashCode()方法来找到位置存储entry<key,value>对象。如果两个对象hashcode相等,调用equal方法判断是否是同一个对象(当key是结构体的时候,hashcode相同,但不equals)。如果Hashcode相同,则会用链表的形式存储。
HashMap的提问
- 如果两个key的hashcode相同,如何获取值对象?
用get()获取对应的链表,遍历链表用equals找到值对象 - HashMap中能put两个相同的Key吗?
原理上来说是不能的,因为HashMap的key是不可重复的,后put的会将之前存在的覆盖掉 - 如何存入相同key的不同值?即不覆盖掉之前的value,一个key对应多个value
第一想法是用一个list来存value,让后加入的value值添加到之前添加的后面。
1.如果key是String类型,已经重写了HashCode()和equals(),创建一个自己的HashMap类,重写put()
public class MyHashMap<K> extends HashMap<K,String> {
/**
* 使用HashMap中containsKey判断key是否已经存在
* @param key
* @param value
* @return
*/
@Override
public String put(K key, String value) {
String newV = value;
if (containsKey(key)) {
String oldV = get(key);
newV = oldV + "---" + newV;
}
return super.put(key, newV);
}
}
2.如果key是自定义类,除了要自定义HashMap,还要重写equals和HashCode方法。
参考博客
- 为什么HashMap 的key可以为null?
从源码分析:


在put()中会调用hash()去计算key的hash值,当key为null时返回0.
都看到这里了,喜欢就点个赞吧