监控是整个运维乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供详实的数据用于追查定位问题。选择一款高效的监控系统,是一个省时省力、效率最高的方案。当然,对监控不是很明白的朋友们,看了以下文章可能会对监控整个体系有比较深刻的认识。
一、监控目标
每个人由于所在的行业、公司、业务、岗位不同,对监控的理解也不尽相同,但是我们需要注意,监控是需要站在公司的业务角度去考虑,而不是针对某个监控技术的使用:
对系统不间断的实时监控:实际上是对系统不间断的实时监控(这就是监控);
实时反馈系统当前状态:我们监控某个硬件、或者某个系统,都是需要能实时看到当前系统的状态,是正常、异常、或者故障。
保证服务可靠性安全性:我们监控的目的就是要保证系统、服务、业务正常运行
保证业务持续稳定运行:如果我们的监控做得很完善,即使出现故障,能第一时间接收到故障报警,在第一时间处理解决,从而保证业务持续性的稳定运行。
二、监控方法
1.了解监控对象:我们要监控的对象你是否了解呢?比如CPU到底是如何工作的?
2.性能基准指标:我们要监控这个东西的什么属性?比如CPU的使用率、负载、用户态、内核态、上下文切换。
3.报警阈值定义:怎么样才算是故障,要报警呢?比如CPU的负载到底多少算高,用户态、内核态分别跑多少算高?
4.故障处理流程:收到了故障报警,我们怎么处理呢?有什么更高效的处理流程吗?

三、监控核心
发现问题:当系统发生故障报警,我们会收到故障报警的信息。
定位问题:故障邮件一般都会写某某主机故障、具体故障的内容,我们需要对报警内容进行分析。比如一台服务器连不上,我们就需要考虑是网络问题、还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等,我们就需要去分析故障具体原因。
解决问题:当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障。
总结问题:当我们解决完重大故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现。
一个优秀的运维人员,应该学会合理利用工具。而个人对服务器进行有效的监控和管理,除了传统的脚本命令,通过集群式面板工具,效率将会大大提高。通过面板工具,我们可以添加多台服务器进行管理维护。什么CPU持续过高、内存占用太多、磁盘空间不足、日志报错等问题,在面板工具中,我们都可以直观明了地发现问题,从而用最快速度解决问题,不必再耗费过多的时间重复这些基础、繁琐的工作。
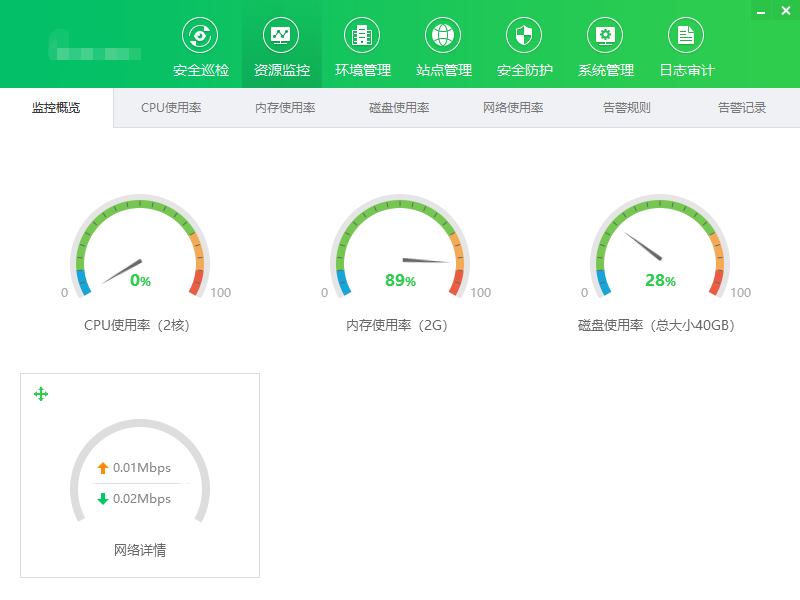
而像我们这种服务器数量多且繁杂的,对于面板工具的挑选,最重要的一点就是添加服务器的限制少。以我现在在用的云帮手(云帮手官网地址)为例,全面兼容所有云服务商,同时兼容Windows、CentOS、Ubuntu、Debian、OpenSUSE、Fedora等云服务器操作系统,对服务器、主机、站点的数量没有限制,哪怕我加了两百多台服务器,依旧运行得很流畅。
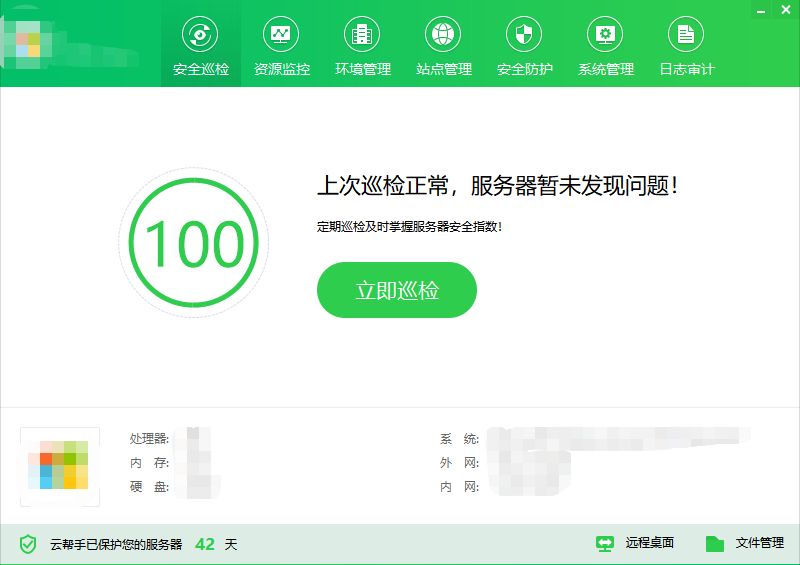
云帮手(云帮手官网地址)基础功能十分完善,资源监控/告警、安全防护、环境部署、站点管理、远程控制等功能在日常服务器的管理中帮助很大,集群化管理让我们不用再一台台服务器的去运行脚本修复问题,一键式的傻瓜操作也让新加入团队的运维新人能够快速上手。更值得一提的是一键安全巡检和一键修复功能,只需要对每台服务器定期进行检测和修复,就能让隐患在最快的时间内发现并解除,避免因服务器故障而导致业务无法开展,让公司业务开展得更加顺畅。
如果你想了解更多,可以去官网看看:点击了解更多
在工作中,找到一款合适的工具,不仅能提高自己的工作效率,也是对公司发展的一种帮助,不止是像我们这样的运维岗位,我觉得不同的岗位也会有相应的工具能给予帮助,也可以分享一下你们工作中常用的工具,大家一起学习一下~