- partition 分区做负载均衡(分布在多个broker上),配合消费者组中的多个消费者进行消费提高读写并发度。
- replication 副本做topic数据备份冗余。
分区内数据有序性,每个分区都有自己的顺序LEO(Log End Offset)
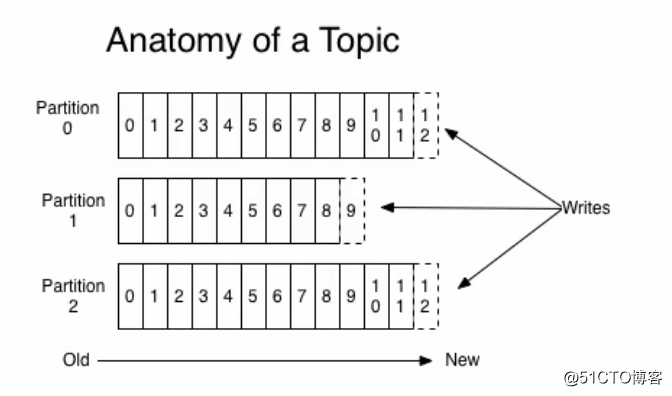
kafka中的消息是以topic作为区分的,生产者生产消息和消费者消费消息都是面向topic的。
- topic是逻辑上的概念
- partition是物理上的概念
如下图的目录:topic名称-分区/(主题名称test-topic-01,分区编号0)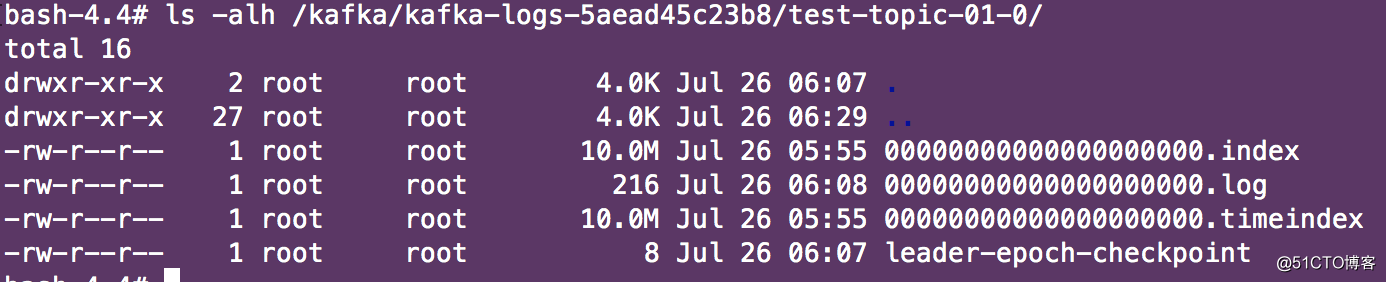
#日志片段文件最大为1G,超过将要创建新的文件
log.segment.bytes=1073741824生产者生产的消息都会存放在分区的物理文件目录(如test-topic-01-0)里面的log文件中,当log文件过大时会导致定位效率低。
- [x] kafka采取了 分片(segment)+索引(index) 的机制。
partition分区下面会分为多个segment片段(分片),每个分片对应着.log和.index文件。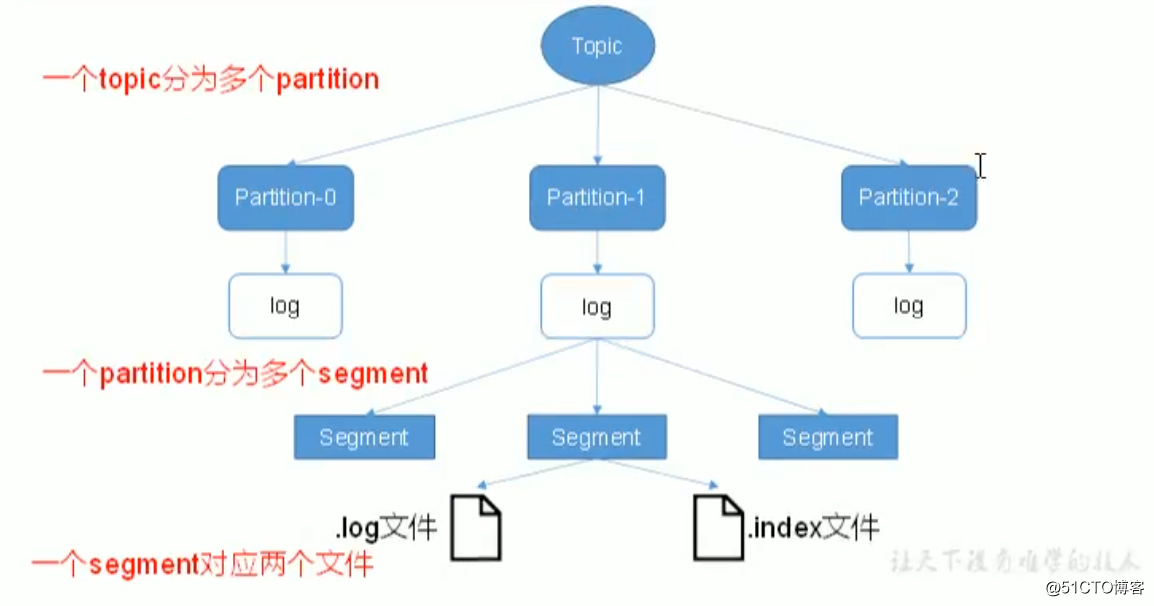
log文件超过1G的时候会新创建一个log文件。
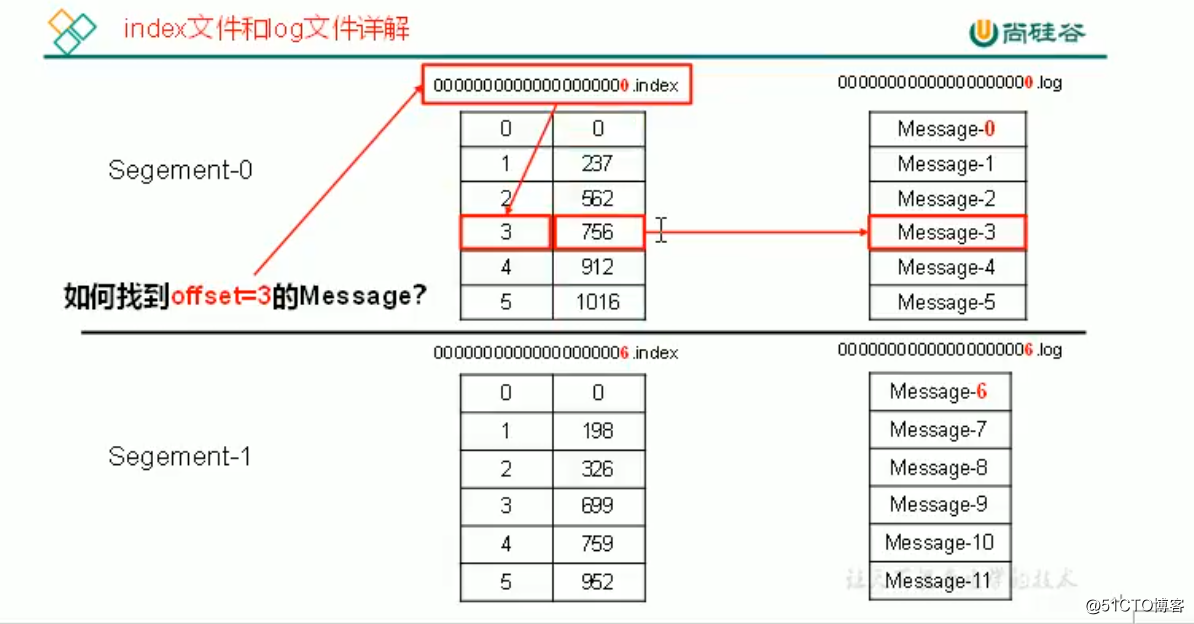
000000xxxxxx.log 的文件名表示片段中的消息的最大偏移量(LEO)
对应的索引文件也为000000xxxxxx.index
通过二分查找法能够迅速定位某条消息。
如上图所示
log文件中的消息message-3对应的索引文件中的3的位置,记录offset偏移量为756和消息的长度。假如messgae-3的长度为1000,那么只需要在log文件中找到756~1756间的内容就是message-3的消息。