MySQL存储引擎 及 索引数据结构
存储引擎
根据全球数据库排行榜最新排名,我们可以发现MySQL在全球数据库排行榜中稳居第二,此网站为技术开发者技术选型提供了很好的参考资料。下面我们只对MySQL数据库中的存储引擎进行学习。我们知道,存储引擎负责数据的存储和提取,提供了读写接口。在MySQL5.5.5之前版本,默认的存储引擎为MyISAM;从MySQL5.5.5开始,默认的存储引擎是InnoDB。
在Navicat中查看MySQL支持的存储引擎有哪些:
show ENGINES
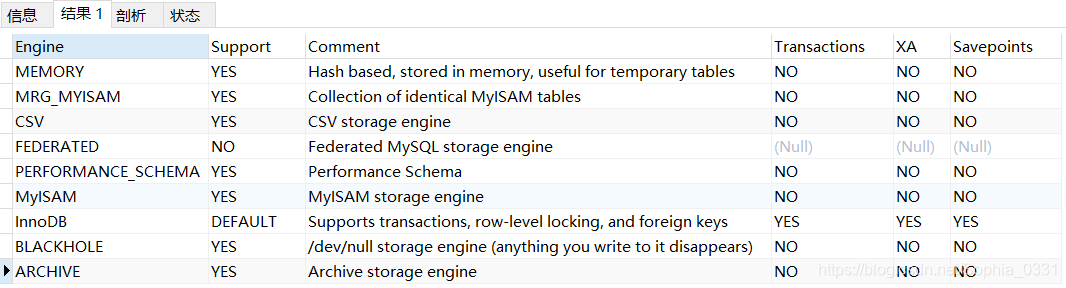 从图中可以看出,MySQL默认支持的存储引擎有InnoDB ,MyIsam,Memory等 9种 存储引擎。
从图中可以看出,MySQL默认支持的存储引擎有InnoDB ,MyIsam,Memory等 9种 存储引擎。
MySQL中常用存储引擎的对比
InnoDB中建立索引使用 B+ 树 数据结构
在InnoDB中默认使用B+树索引,每一个索引在InnoDB里对应一棵B+ 树。来看一下B+树的数据结构:
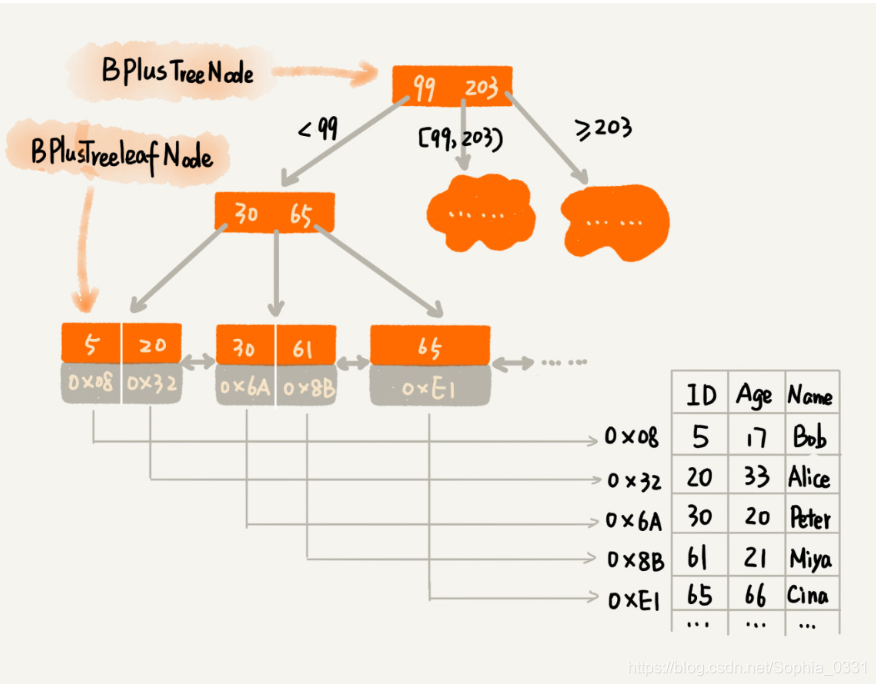
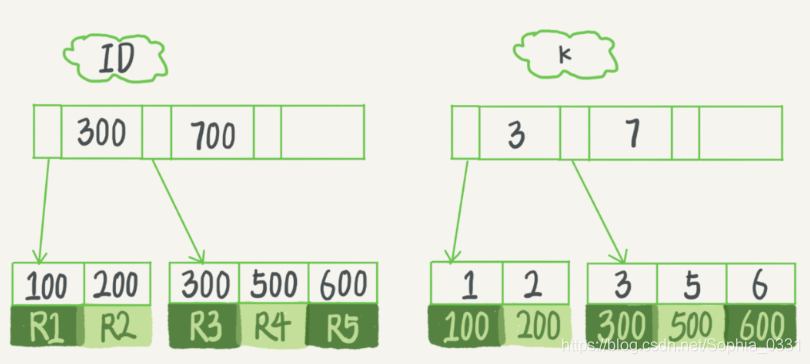
举个例子说明以B + 树结构建立索引时的查找过程:
创建表T,主键列为id ,在字段k上建立索引。
create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中R-R5的(id,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6)。两棵索引树的结构分别如下:
根据叶子节点内容划分,索引类型分为主键索引和非主键索引。
1、主键索引的叶子节点存的是整行数据,主键索引也叫聚簇索引。
2、非主键索引的叶子节点内容是主键的值。非主键索引页叫二级索引。
下面看两条SQL语句,来说明基于主键索引和普通索引的查询有什么区别:
(1)根据主键ID去查询,即主键查询方式,只需要搜索ID这棵B+ 树。
select * from T where ID=500
(2)根据 k 字段去查询,即普通索引查询方式,需要先搜索 k 索引树,得到ID的值为500,再到ID索引树搜索一次,这个过程叫回表(回到主键索引树搜索的过程称为回表)。
覆盖索引
select id,k,name from T where k=5
那什么时候不需要回表?如果执行的语句是select id from T where k between 3 and 5,这时只需要查ID的值,而Id 的值已经在k 索引树上了,所以可以直接提供查询结果,不需要回表。即这个查询语句里,索引k 已经“覆盖了”我们的查询需求,所以称为覆盖索引。
索引下推
我们知道,在一个SQL语句中如果使用联合索引的话,出现覆盖索引的几率比较大,提到联合索引不得不提的就是最左前缀原则,所以SQL语句中的查询条件尽量按照联合索引中的建立顺序来查询。
提到联合索引你应该会想到索引下推,在MySQL5.6版本上加入了索引下推(ICP index condition pushdown)优化,可以在索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的纪律,减少回表的次数。
举个例子:
创建表 tuser, 向表中插入测试数据,我现在要查询表中 名字第一个字是张,而且年龄是10岁的所有男孩。
select name,age from tuser where name like '张%' and age=10 and ismale=1;
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB;
INSERT INTO `practice`.`tuser`(`id`, `id_card`, `name`, `age`, `ismale`) VALUES (1, '1', '张三', 10, 1);
INSERT INTO `practice`.`tuser`(`id`, `id_card`, `name`, `age`, `ismale`) VALUES (2, '2', '张三', 20, 1);
INSERT INTO `practice`.`tuser`(`id`, `id_card`, `name`, `age`, `ismale`) VALUES (3, '3', '张六', 30, 0);
INSERT INTO `practice`.`tuser`(`id`, `id_card`, `name`, `age`, `ismale`) VALUES (4, '4', '张三', 10, 1);
INSERT INTO `practice`.`tuser`(`id`, `id_card`, `name`, `age`, `ismale`) VALUES (5, '5', '张三', 40, 1);
(1)无索引下推执行流程:
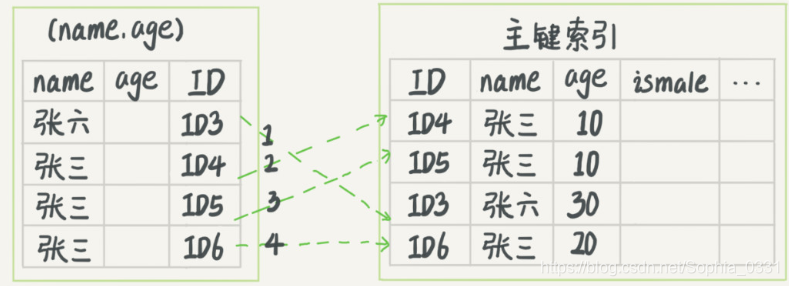
在这个过程中InnoDB并不会去看age的值,只是按顺序把 name第一个字是张 的记录一条一条取出来回表,所以需要回表四次。
(2)索引下推执行流程
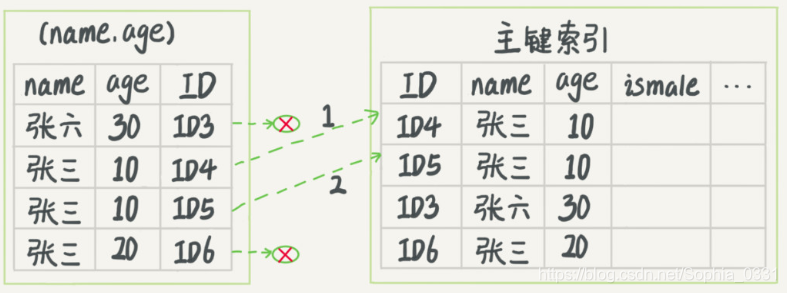
在这个过程中,InnoDB在(name,age)索引内部就判断了age是否等于10,对于不等于10的记录,直接过滤掉。只需要对ID4和ID5这两条记录回表取数据判断,就只需要回表2次。从而可以看出,有了索引下推减少了回表的次数,提升了查询效率。
Memory存储引擎建立索引使用 Hash 数据结构
哈希表是一种以key-value形式存储数据的结构,它的结构借助数组加链表来实现。通过key查找对应的value 过程是这样的:首先key经过hash函数运算得到hashCode值,通过hashCode值 映射 到数组中桶的位置。如果有多个key经过hash函数计算得到的hashCode值相同,那就产生了hash冲突,可以通过链表法来解决hash冲突。
举个例子:
假设现在有一张存储着身份证号和姓名的表,需要根据身份证号查找对应的名字,这时对应的hash索引的示意图如下:
n2 和 n4 根据身份证号通过 hash 函数计算得出的值都是 N,产生了哈希冲突,那这时如果要查找n2对应的名字是什么,就需要顺序遍历链表找到 User2。
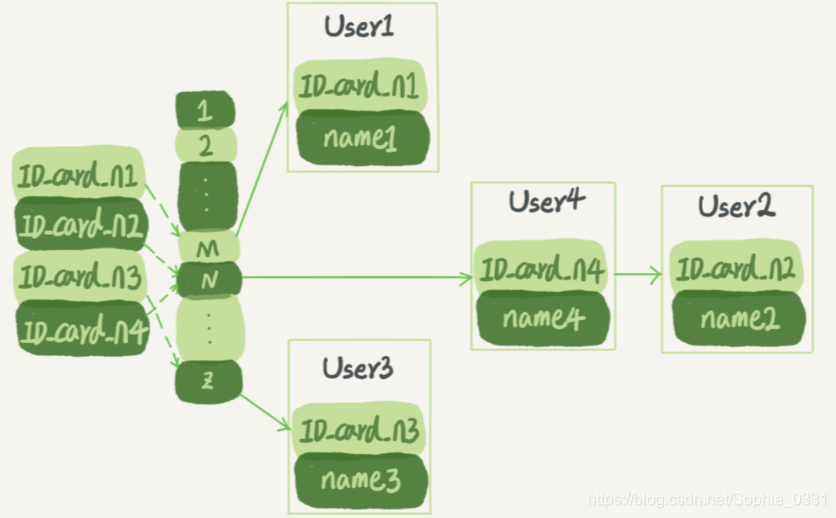
注意:哈希表的结构适用于只有等值查询的场景。如果要找身份账号在一个区间范围内的所有用户,就必须全部扫描一遍。