数据结构及算法基础
索引的本质
Mysql官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。句子主干就是索引是数据结构。
数据库查询是数据库的主要功能,我们都希望查询数据的速度尽可能快,因此数据库系统设计会从查询的优化的角度进行优化。最基本的查询算法就是顺序查找,但这种复杂度为O(n)查找在数据量大的时候是糟糕的。当然还有很多好的查找算法,如:二分查找(binary search)、二叉树查找(binary tree search)等,但这些算法只能应用于特定的数据结构中,例如二分查找要求数据有序,二叉树查找只能应用于二叉查找树上;而正常的数据是不能够完全满足数据结构,所以将这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级的查找算法。这种数据结构就是索引。
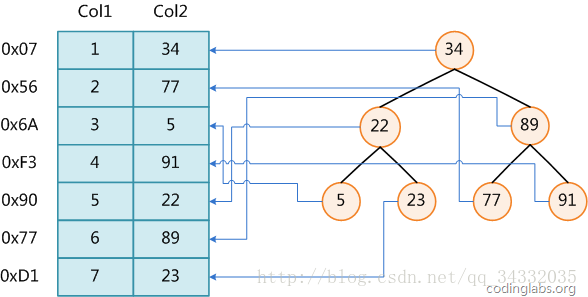
虽然上图展示的是一个正确的索引,但是在实际应用中,没有一个数据库是依赖二叉查找树或红黑树来作为索引的数据结构。原因在后续介绍。
B-Tree与 B+Tree
B-Tree
B-Tree:多路查找树,一种适合磁盘或其他存储设备的数据结构
B-Tree特性
(ceil(x)为去上限的函数)
1、数种每个节点最多有m个孩子;
2、除了根节点和叶子节点外,其他每个节点至少有ceil(m/2)个孩子
3、若根节点不是叶子节点,则至少有2个孩子
4、所有叶子节点都出现在同一层,叶子节点不包含任何关键字信息
5、每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,……,Kn,Pn)。其中:
a) Ki (i=1…n)为关键字,且关键字按顺序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1
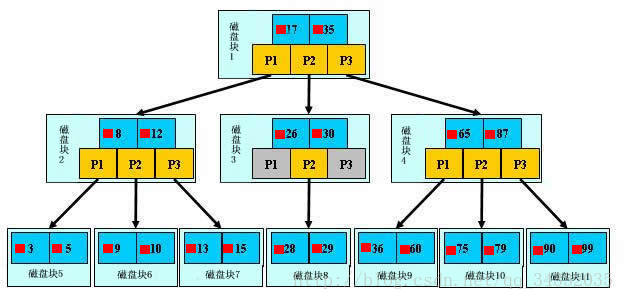
insert
插入一个元素时,首先在B-tree中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素,注意:如果叶子结点空间足够,这里需要向右移动该叶子结点中大于新插入关键字的元素,如果空间满了以致没有足够的空间去添加新的元素,则将该结点进行“分裂”,将一半数量的关键字元素分裂到新的其相邻右结点中,中间关键字元素上移到父结点中(当然,如果父结点空间满了,也同样需要“分裂”操作),而且当结点中关键元素向右移动了,相关的指针也需要向右移。如果在根结点插入新元素,空间满了,则进行分裂操作,这样原来的根结点中的中间关键字元素向上移动到新的根结点中,因此导致树的高度增加一层。
delete
首先查找B-tree中需删除的元素,如果该元素在B-tree中存在,则将该元素在其结点中进行删除,如果删除该元素后,首先判断该元素是否有左右孩子结点,如果有,则上移孩子结点中的某相近元素到父节点中,然后是移动之后的情况;如果没有,直接删除后,移动之后的情况.。
删除元素,移动相应元素之后,如果某结点中元素数目小于ceil(m/2)-1,则需要看其某相邻兄弟结点是否丰满(结点中元素个数大于ceil(m/2)-1),如果丰满,则向父节点借一个元素来满足条件;如果其相邻兄弟都刚脱贫,即借了之后其结点数目小于ceil(m/2)-1,则该结点与其相邻的某一兄弟结点进行“合并”成一个结点,以此来满足条件
#### B+Tree
B+Tree 是B-Tree的增强版,它将所有的数据都存储在了叶子节点中,非叶子节点值存放关键字和孩子指针,因此最大化了内部节点的分支因子,所以B+Tree的遍历更加高效
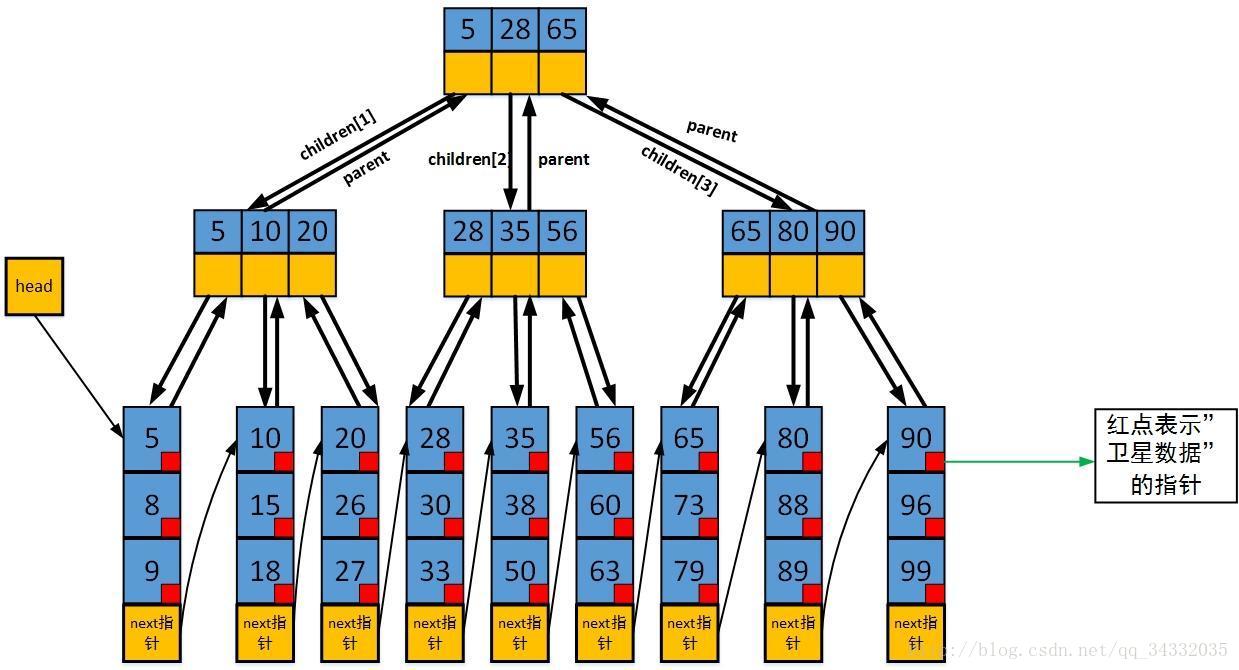
为什么使用B-Tree/B+Tree
磁盘存取原理
索引一般以文件形式存储在磁盘上,索引检索需要I/O操作,而磁盘I/O存在机械运动的耗费,时间消耗是极大的。
磁盘结构
盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁盘的最小存储单元
磁盘预读
为了提高效率,尽量减少磁盘I/O,磁盘每次会进行预读,预读的单位是页(page),当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
使用B-Tree/B+Tree
因为磁盘预读大单位为页(page),所以索引中B-Tree/B+Tree度的设置一般为度的大小。
B-Tree中一次检索最多需要h-1次I/O,相对于红黑树的高度要少很多,也就更加的节省资源。