Dive into DL 阅读笔记 1
线性回归
https://zh.d2l.ai/chapter_deep-learning-basics/linear-regression.html#
-
Linear Regression解决回归问题,Softmax Regression解决分类问题
-
线性回归模型:\(\hat{y} = x_1 w_1 + x_2 w_2 + b\)
-
线性回归损失函数(单样本误差):\(\ell^{(i)}(w_1, w_2, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2\)
- 常数1/2使对平方项求导后的常数系数为1,这样在形式上稍微简单一些
-
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用
-
参数迭代公式:
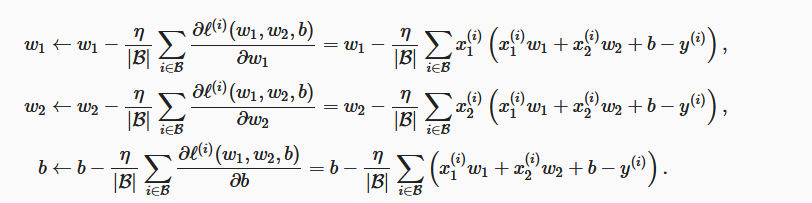
- 这里大Beta代表batch size
-
pytorch中的广播机制:当对两个形状不同的Tensor按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个Tensor形状相同后再按元素运算
- 例如:
x = torch.arange(1, 3).view(1, 2) print(x) y = torch.arange(1, 4).view(3, 1) print(y) print(x + y)- 输出:
tensor([[1, 2]]) tensor([[1], [2], [3]]) tensor([[2, 3], [3, 4], [4, 5]]) -
注意在使用批梯度下降更新参数时,要把梯度除以batch_size:
param.data -= lr * param.grad / batch_size -
使用pytorch提供的data包来读取数据:
import torch.utils.data as Data # 由于data常用作变量名,因此这里将导入的data模块用Data代替
batch_size = 10
# 将训练数据的特征和标签组合
dataset = Data.TensorDataset(features, labels)
# 随机读取小批量
data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)
- 利用pytorch简洁地定义模型:
- 完整定义:
class LinearNet(nn.Module): def __init__(self, n_feature): super(LinearNet, self).__init__() self.linear = nn.Linear(n_feature, 1) # forward 定义前向传播 def forward(self, x): y = self.linear(x) return y net = LinearNet(num_inputs) print(net) # 使用print可以打印出网络的结构- 利用
nn.Sequential快速定义:
# 写法一 net = nn.Sequential( nn.Linear(num_inputs, 1) # 此处还可以传入其他层 ) # 写法二 net = nn.Sequential() net.add_module('linear', nn.Linear(num_inputs, 1)) # net.add_module ...... # 写法三 from collections import OrderedDict net = nn.Sequential(OrderedDict([ ('linear', nn.Linear(num_inputs, 1)) # ...... ])) torch.utils.data模块提供了有关数据处理的工具,torch.nn模块定义了大量神经网络的层,torch.nn.init模块定义了各种初始化方法,torch.optim模块提供了很多常用的优化算法
softmax回归
- softmax回归同线性回归一样,也是一个单层神经网络。由于每个输出o1,o2,o3o1,o2,o3的计算都要依赖于所有的输入x1,x2,x3,x4x1,x2,x3,x4,softmax回归的输出层也是一个全连接层:

- 最后通过softmax运算符(softmax operator)来把节点的值转换成值大等于0且和为1的概率分布:\(\hat{y}_1, \hat{y}_2, \hat{y}_3 = \text{softmax}(o_1, o_2, o_3)\)
- 其中:\(\hat{y}_1 = \frac{ \exp(o_1)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_2 = \frac{ \exp(o_2)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_3 = \frac{ \exp(o_3)}{\sum_{i=1}^3 \exp(o_i)}\)
- 由于softmax的输出只需要比较大小即可获得类别预测结果,因此平方损失函数对它来说太严格了。在分类问题下,通常使用交叉熵作为损失函数。如果每个样本只有一个标签,那么交叉熵损失可以简写成:\(\ell(\boldsymbol{\Theta}) = -(1/n) \sum_{i=1}^n \log \hat y_{y^{(i)}}^{(i)}\)
- 从另一个角度来看,我们知道最小化\(\ell(\boldsymbol{\Theta})\)等价于最大化\(\exp(-n\ell(\boldsymbol{\Theta}))=\prod_{i=1}^n \hat y_{y^{(i)}}^{(i)}\),即最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率
torchvision包服务于pytorch框架,主要用来构建计算机视觉模型。torchvision主要由以下几部分构成:torchvision.datasets: 一些加载数据的函数及常用的数据集接口;torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;torchvision.utils: 其他的一些有用的方法。
- Softmax数值不稳定问题:
- 计算机通过有限数量的位模式来表示无限多的实数,总会引入一些近似误差。如果涉及时没有考虑最小化舍入误差的累积,在实践时可能会导致算法实效:
- 当接近零的数被四舍五入为零时发生下溢
- 大量级的数被近似为无穷时发生上溢

- 计算机通过有限数量的位模式来表示无限多的实数,总会引入一些近似误差。如果涉及时没有考虑最小化舍入误差的累积,在实践时可能会导致算法实效:
深度学习训练技巧
应对过拟合问题的常用方法:权重衰减(weight decay)
- 权重衰减等价于 \(L_2\) 范数正则化(regularization)
- L2范数正则化在模型原损失函数基础上添加L2范数惩罚项,从而得到训练所需要最小化的函数。L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积
- 有了L2范数惩罚项后,在小批量随机梯度下降中,我们将线性回归一节中权重w1和w2的迭代方式更改为:
\begin{aligned}
w_1 &\leftarrow \left(1- \eta\lambda \right)w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_1^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\
w_2 &\leftarrow \left(1- \eta\lambda \right)w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_2^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right).
\end{aligned}
-
可见,L2范数正则化令权重w1和w2先自乘小于1的数,再减去不含惩罚项的梯度。因此,L2范数正则化又叫权重衰减
-
权重衰减在pytorch中的使用方式:
# 直接在构造优化器实例时通过weight_decay参数来指定权重衰减超参数
def fit_and_plot_pytorch(wd):
# 对权重参数衰减。权重名称一般是以weight结尾
net = nn.Linear(num_inputs, 1)
nn.init.normal_(net.weight, mean=0, std=1)
nn.init.normal_(net.bias, mean=0, std=1)
optimizer_w = torch.optim.SGD(params=[net.weight], lr=lr, weight_decay=wd) # 对权重参数衰减
optimizer_b = torch.optim.SGD(params=[net.bias], lr=lr) # 不对偏差参数衰减
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y).mean()
optimizer_w.zero_grad()
optimizer_b.zero_grad()
l.backward()
# 对两个optimizer实例分别调用step函数,从而分别更新权重和偏差
optimizer_w.step()
optimizer_b.step()
train_ls.append(loss(net(train_features), train_labels).mean().item())
test_ls.append(loss(net(test_features), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', net.weight.data.norm().item())