一元线性回归
变量之间的关系大致可分为两大类:
- 确定性的关系:可以用精确的函数关系来表达。例如矩形面积S与边长a,b的关系。
- 非确定性的关系:变量之间既互相联系但又不是完全确定的关系,称为相关关系。例如人的身高与体重、农作物产量与降雨量等的关系。
从数量的角度去研究这种非确定性的关系,是数理统计的一个任务. 包括通过观察和试验数据去判断变量之间有无关系,对其关系大小作数量上的估计、推断和预测,等等.
回归分析就是研究相关关系的一种重要的数理统计方法.
一元正态线性回归模型
只有两个变量的回归分析, 称为一元回归分析;
超过两个变量时称为多元回归分析
变量之间成线性关系时, 称为线性回归;
变量间不具有线性关系时, 称为非线性回归.
若y和x之间大体上呈现线性关系, 可假定
其中a 和 b是未知常数, ε表示其它随机因素的影响.通常假定ε服从正态分布
即
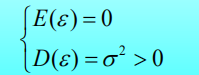
其中
为未知参数.称
为一元线性回归模型. 由(1)得 E(y)=a+bx用E(y)作为y 的估计
得
称(2)为 y 关于 x 的一元线性回归方程 .
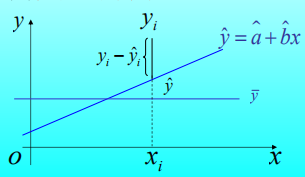
回归分析的任务是利用n组独立观察数据 来估计a和b, 以估计值 和 分别代替(2)式中的a和b, 得回归方程
由于该方程的建立依赖于通过观察或试验取得的数据, 故又称其为经验回归方程或经验公式.
称为未知参数 a,b 的回归系数
最小二乘法估计
估计原则:
寻找一个使上述平方和达到最小的,作为这个物体重量的估计值, 这种方法称为最小二乘法
我们可以用真实值减去预测值的平方的和来检验回归的好坏,即
该值越小说明回归得到的效果越好。
依照最小二乘法的思想,提出目标量Q(a,b)
因此我们需要设法求出a 、b的估计值
,使偏差平方和Q(a,b)达到最小.

由此得到的回归直线
是在所有直线中偏差平方和Q(a,b)最小的一条直线.
由于 是从观察值得到的回归方程,它会随观察结果的不同而改变,并且它只反映了由 x 的变化引起的 y 的变化,并没有包含误差项.另外,能否给出未知参数 的估计,由此引出以下问题:
- 的点估计是什么?
- 回归方程是否有意义? 即自变量 x 的变化是否真的对因变量 y 有影响? 因此有必要对回归效果作出检验.
- 如果方程真有意义,用它预测y时,预测值与真值的偏差能否估计?
的无偏估计
为残差平方和
反映了除 x 外其它因素对 y 的影响, 这些因素没有反映在自变量x中, 它们可作为随机因素看待
线性假设的显著性检验(T 检验法)

r检验法

线性回归的方差分析(F 检验法)

利用回归方程进行预报(预测)
例1 为研究某一化学反应过程温度对产品得率的影响,测得观测数据如下:
求Y关于x的回归方程u(x),并进行有关检验和预报
clc,clear;
x1=[100:10:190]';
y=[45 51 54 61 66 70 74 78 85 89]';
figure(1)
plot(x1,y,'*')%画数据散点图
hold on
x=[ones(10,1),x1];
[b,bint,r,rint,stats]=regress(y,x);
x2=[100:190];
plot(x2,b(1)+b(2)*x2)%画拟合图
figure(2)
rcoplot(r,rint)%画残差图
b,bint,stats
b =
-2.7394
0.4830
bint =
-6.3056 0.8268
0.4589 0.5072
stats =
1.0e+03 *
0.0010 2.1316 0.0000 0.0009
b - 多元线性回归的系数估计值
bint - 系数估计值的置信边界下限和置信边界上限
r - 残差
rint - 用于诊断离群值的区间
stats - 模型统计量,包括R^2 统计量、F 统计量及其 p 值,以及误差方差的估计值( 无偏估计)。

- R平方决定系数,反应因bai变量的全部变异能通过回归关系被自变量du解释的比例。介于0~1之间,越接近1,回归拟合效果越好,一般认为超过0.8的模型拟合优度比较高。
- F统计量是指在零假设成立的情况下,符合F分布的统计量。 所以
可以看到,线性回归方程y=a+bx的a=-2.7394,b= 0.4830
a的置信区间为 [-6.3056, 0.8268]
b的置信区间为[ 0.4589 , 0.5072]
,p=0,说明回归效果显著


多元多项回归
应用条件
- 线性趋势:Y与Xi间具有线性关系
- 独立性:应变量Y的取值相互独立
- 正态性:对任意一组自变量取值,因变量Y服从正态分布
- 方差齐性:对任意一组自变量取值,因变量y的方差相同
后两个条件等价于:残差ε服从均数为0、方差为σ2的正态分布
一元多项式回归


例2
观测物体降落的距离s与时间t的关系,得到数据如下表,求s关于t的回归方程

方法一:直接作二次多项式回归(相当于拟合):
t=1/30:1/30:14/30;
s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];
plot(t,s,'*')
hold on
[p,S]=polyfit(t,s,2)
plot(t,p(1)*t.^2+p(2)*t+p(3))

方法二:化为多元线性回归
clc,clear
t=1/30:1/30:14/30;
s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];
T=[ones(14,1) t' (t.^2)'];
[b,bint,r,rint,stats]=regress(s',T);
plot(t,s,'*')
hold on
plot(t,b(3)*t.^2+b(2)*t+b(1))
b,stats
figure(2)
rcoplot(r,rint)

逐步回归分析
“最优”的回归方程就是包含所有对Y有影响的变量, 而不包含对Y影响不显著的变量回归方程.
选择“最优”的回归方程有以下几种方法:
(1)从所有可能的因子(变量)组合的回归方程中选择最优者;
(2)从包含全部变量的回归方程中逐次剔除不显著因子;
(3)从一个变量开始,把变量逐个引入方程;
(4)“有进有出”的逐步回归分析.
以第四种方法,即逐步回归分析法在筛选变量方面较为理想.
逐步回归分析法的思想:
- 从一个自变量开始,视自变量Y对作用的显著程度,从大到小地依次逐个引入回归方程.
- 当引入的自变量由于后面变量的引入而变得不显著时,要将其剔除掉.
- 引入一个自变量或从回归方程中剔除一个自变量,为逐步回归的一步.
- 对于每一步都要进行Y值检验,以确保每次引入新的显著性变量前回归方程中只包含对Y作用显著的变量
- 这个过程反复进行,直至既无不显著的变量从回归方程中剔除,又无显著变量可引入回归方程时为止
MATLAB实现

运行stepwise命令时产生三个图形窗口:Stepwise Plot,Stepwise Table,Stepwise History.
在Stepwise Plot窗口,显示出各项的回归系数及其置信区间.
Stepwise Table 窗口中列出了一个统计表,包括回归系数及其置信区间,以及模型的统计量剩余标准差(RMSE)、相关系数(R-square)、F值、与F对应的概率P.
例题
水泥凝固时放出的热量y与水泥中4种化学成分x1、x2、x3、 x4有关,今测得一组数据如下,试用逐步回归法确定一个 线性模型.

x1=[7 1 11 11 7 11 3 1 2 21 1 11 10]';
x2=[26 29 56 31 52 55 71 31 54 47 40 66 68]';
x3=[6 15 8 8 6 9 17 22 18 4 23 9 8]';
x4=[60 52 20 47 33 22 6 44 22 26 34 12 12]';
y=[78.5 74.3 104.3 87.6 95.9 109.2 102.7 72.5 93.1 115.9 83.8 113.3 109.4]';
x=[x1 x2 x3 x4];
stepwise(x,y)
运行结果如图

红色表示变量移出回归方程,绿色表示变量移入回归方程。当我们想看某变量与回归方程的关系时时可以点击使其变绿,其他变红即可。我们现在的目标是找rmse最小时,R方接近1时应该含有的变量,直接点击全部步骤就可以出来.

可以看到变量x1和x2的显著性最好,
对变量y和x1、x2作线性回归:
X=[ones(13,1) x1 x2];
b=regress(y,X)
b =
52.5773
1.4683
0.6623
故最终模型为
多元线性回归的应用



提示可能存在多重共线性的情况:
- 整个模型的检验结果为P<α,但各自变量的偏回归系数的检验结果P>α。
- 专业上认为应该有统计学意义的自变量检验结果却无统计学意义。
- 自变量的偏回归系数取值大小甚至符号明显与实际情况相违背,难以解释。
- 增加或删除一个自变量或一条记录,自变量回归系数发生较大变化。
MATLAB实现

例3
设某商品的需求量与消费者的平均收入、商品价格的统计数据如下,建立回归模型,预测平均收入为1000、价格为6时 的商品需求量. 
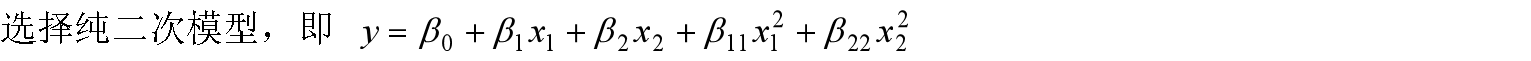
clc,clear
x1=[1000 600 1200 500 300 400 1300 1100 1300 300];
x2=[5 7 6 6 8 7 5 4 3 9];
y=[100 75 80 70 50 65 90 100 110 60]';
x=[x1' x2'];
rstool(x,y,'purequadratic')
方法一:直接用多元二项式回归
这里调用了多元线性回归的工具箱

代码中x1代表输入,x2代表输出,所以x1输入1000,x2输入6,得到需求量为
.
点击导出,可以将均方根误差也就是标准差rmse、残差residuals和beta导入到工作区查看
可以得到
beta =[110.5313, 0.1464, -26.5709, -0.0001, 1.8475]
rmse=4.5362

方法二: 化为多元线性回归
clc,clear
x1=[1000 600 1200 500 300 400 1300 1100 1300 300];
x2=[5 7 6 6 8 7 5 4 3 9];
y=[100 75 80 70 50 65 90 100 110 60]';
X=[ones(10,1) x1' x2' (x1.^2)' (x2.^2)'];
[b,bint,r,rint,stats]=regress(y,X);
b,stats
b =
110.5313
0.1464
-26.5709
-0.0001
1.8475
stats =
0.9702 40.6656 0.0005 20.5771
两个的结果相同,R方为0.97,说明置信度很高
非线性回归

通常选择的六类曲线如下:

观测物体降落的距离s与时间t的关系,得到数据如下表,求s关于t的回归方程
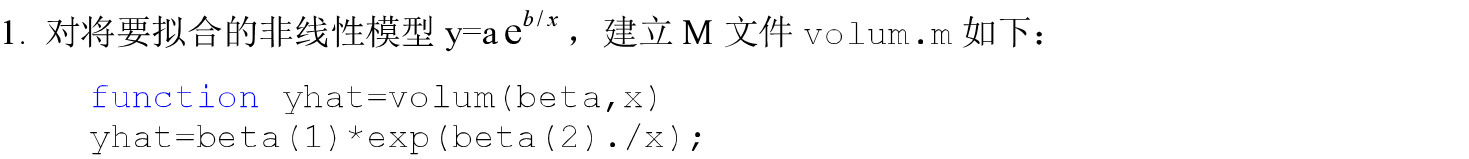
2.
x=2:16;
y=[6.42 8.20 9.58 9.5 9.7 10 9.93 9.99 10.49 10.59 10.60 10.80 10.60 10.90 10.76];
beta0=[8 2]';
[beta,r,J]=nlinfit(x',y','volum',beta0);
[YY,delta]=nlpredci('volum',x',beta,r ,J);
plot(x,y,'k+',x,YY,'r')
beta
beta =
11.6037
-1.0641

结果为
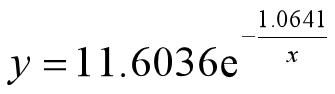
练习题

clc,clear
x0=[20:5:65]';
y=[13.2 15.1 16.4 17.1 17.9 18.7 19.6 21.2 22.5 24.3]';
x=[ones(10,1),x0];
[b,bint,r,rint,stats]=regress(y,x);
hold on
plot(x0,y,'*',x0,b(1)+b(2)*x0)
figure(2)
rcoplot(r,rint)
b,bint,stats


clc,clear
x=[0:2:20];
y=[0.6 2 4.4 7.5 11.8 17.1 23.3 31.2 39.6 49.7 61.7];
%拟合的方法
a=polyfit(x,y,2);
y1=a(3)+a(2)*x+a(1)*x.^2;
%回归的方法
T=[ones(11,1) x' (x.^2)'];
[b,bint,r,rint,stats]=regress(y',T);
y2=b(1)+b(2)*x+b(3)*x.^2;
plot(x,y,'*',x,y1,'-.',x,y2,'ro')


