抓紧时间,直接上码,没有什么难度
from sklearn.datasets import load_digits
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from sklearn.preprocessing import scale
digits = load_digits()
images=digits.images
plt.figure(figsize=(10,5))
plt.suptitle('handwritten_Image')
# 前十张图片
for i in range(10):
plt.subplot(2,5,i+1), plt.title('image%i'%(i+1))
plt.imshow(images[i]), plt.axis('off')
plt.show()
# 标准化和簇心
data = scale(digits.data)
n_digits = len(np.unique(digits.target))
# 降维和k均值聚类
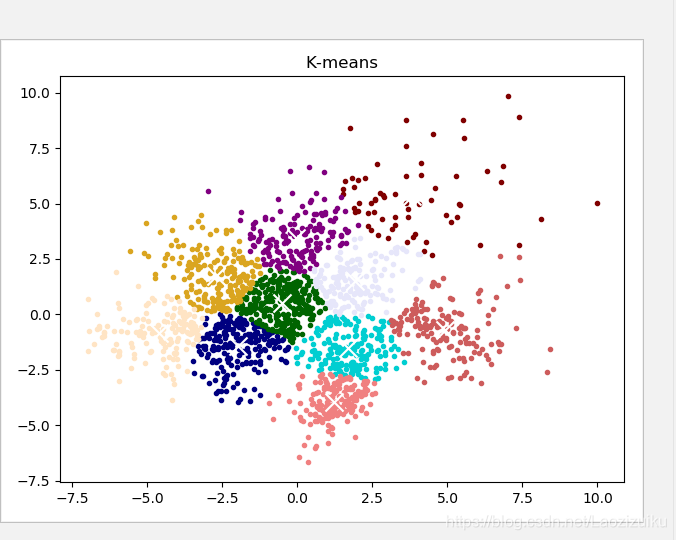
reduced_data = PCA(n_components=2).fit_transform(data)
kmeans = KMeans(init='k-means++', n_clusters=n_digits, n_init=10)
kmeans.fit(reduced_data)
label_pred = kmeans.labels_
plt.clf()
# 画簇心和点
centroids = kmeans.cluster_centers_
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='x', s=169, linewidths=3,
color='w', zorder=10)
color_list=[ '#000080', '#006400','#00CED1', '#800000', '#800080',
'#CD5C5C', '#DAA520', '#E6E6FA', '#F08080', '#FFE4C4']
for i in range(n_digits):
x = reduced_data[label_pred == i]
plt.scatter(x[:, 0], x[:, 1], c=color_list[i], marker='.', label='label%s'%i)
plt.title('K-means')
plt.axis('on')
plt.show()