我们所知的大部分编程语言中,数组都是从0开始的,但你是否思考过,为什么数组从0开始编号,而不是1开始呢?从1开始不是更符合我们的日常习惯吗?
- 什么是数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
线性表(Linear List),见名知意,线性表就是数组排成一条线一样的结构。每个线性表上的数据只有前和后两个方向,其实除了数组,链表、队列、栈等也是线性表结构。
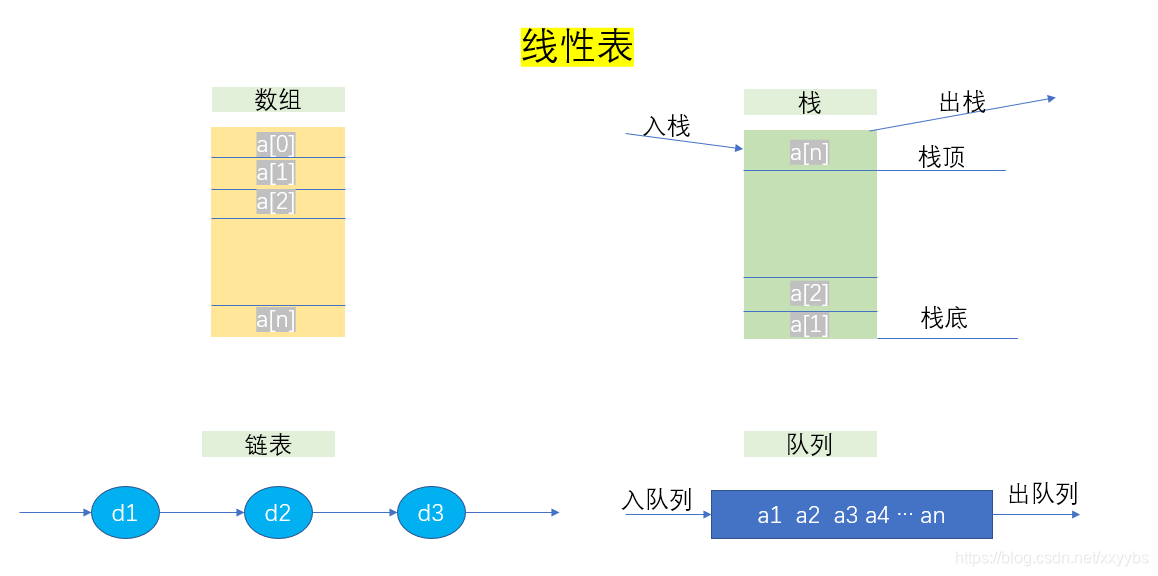
而与之对立的概念就是非线性表,非线性表中有我们熟知的二叉树、图、堆等。
连续的内存空间和相同的数据类型。 线性表+连续的内存空间(相同数据类型),造就了数组的快速访问特性,当按照下标查找指定位置的数据时,时间复杂度达到了最优的 O(1),当访问不确定的数组时时间复杂度为 O(n)。
有了上面的基本介绍,接下来我们拿一个长度为 10 的 int 类型的数组 int[] a = new int[10] 来举例。分配了一块连续内存空间 100~139,其中,内存块的首地址为 first_address = 100。
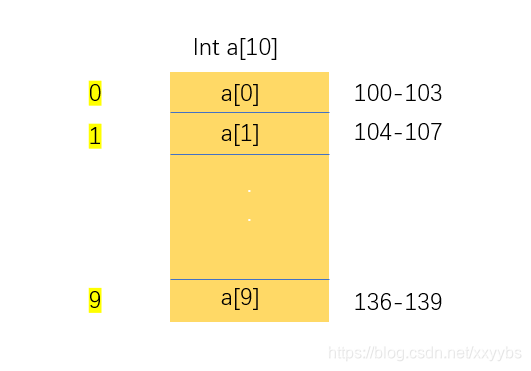
计算机会给每个内存成员分配一个地址,通过指定的地址来访问内存中的数据,当计算机随机访问数组中的某个元素时会进行西面的方式来进行寻址:
a[i]_address = first_address + i * data_size
data_size 表示元素大小。
为什么大多数编程语言中,数组要从 0 开始编号,而不是从 1 开始呢?
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 a 来表示数组的首地址,a[0] 就是偏移为 0 的位置,也就是首地址,a[i] 就表示偏移 i 个 data_size 的位置,所以计算 a[i] 的内存地址只需要用这个公式:
a[i]_address = first_address + i * data_size
但是,如果数组从 1 开始计数,那我们计算数组元素 a[i] 的内存地址就会变为:
a[i]_address = first_address + (i-1) * data_size
从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。
数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。