MapReduce的工作机制
物理实体
参与MapReduce作业执行涉及4个独立的实体:
- 客户端(client):编写mapreduce程序,配置job,提交job,这就是程序员完成的工作;
- JobTracker:初始化job,分配job,与TaskTracker通信,协调整个作业的执行;
- TaskTracker:保持与JobTracker的通信(定时发送心跳),在分配的数据片段上执行Map或Reduce任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个
- Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
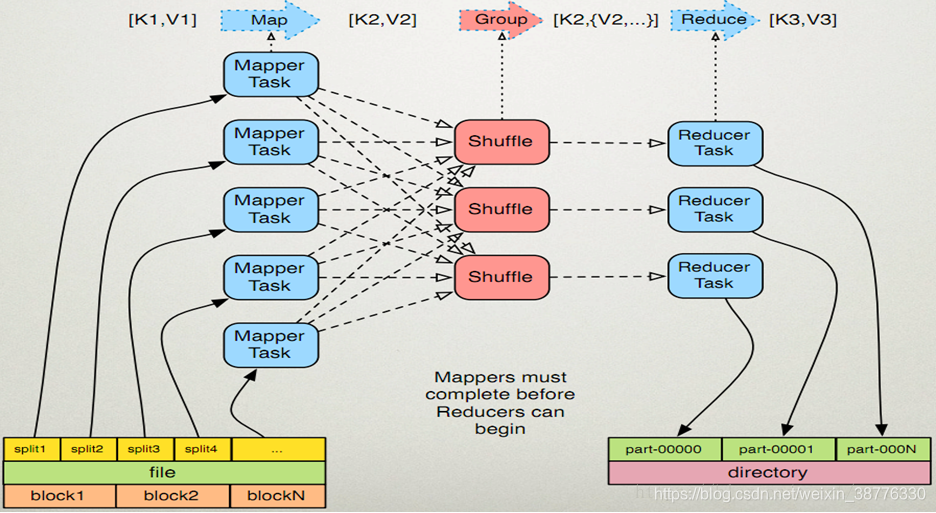
逻辑实体
- input split: 发生在map计算前,每个split对应一个map。split与hdfs的块大小有关
- map: 由程序员实现 ,一般map操作都是本地化操作也就是在数据存储节点上进行,输入键值对:(k1, v1),输出键值对:(k2, v2)。
- combiner: 可选,本地化reduce操作,让写入磁盘的数据尽可能少
- shuffle:map输出到reduce输入的过渡过程。输出放在环形缓冲区(内存),当达到环形缓冲区阈值时,写入溢出文件spill(磁盘),最后合并。接着进行Partitioner操作,一个Partition对应一个reduce
- reduce: 由程序员实现,最后结果存储在hdfs上。输入键值对:(k3, iterable-v3) ,输出键值对(k4, v4)
参考文章:https://blog.csdn.net/mucaoyx/article/details/82078226
《WordCount背后的MapReduce原理全面详解》