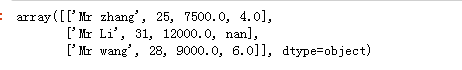
一 Pandas简介

二 开发环境准备

三 Pandas 快速入门
Pandas 基本数据结构-Series
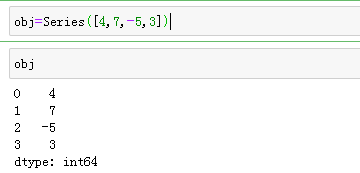
Series是一种类似于一维数组的对象,它由一组数据(各种 Numpy数据类型)以及 一组与之相关的数据标签(即索引1)组成。仅由一组数据即可产生最简单的 Series
from pandas import Series,DataFrame
import pandas as pd
#获取索引(行号)
obj.index
#获取值
obj.values
#通过索引获取value
obj[3]
#指定索引(默认索引是从0开始的数字)
obj1=Series([4,7,-5,3],index=["d","b","c","a"])
obj1


Pandas 基本数据结构-DataFrame
DataFrame 是一个 表格型 的数据结构,它含有一组 有序的列 ,每列可以 是 不同的值类型 (数值、字符串、布尔值等)。 Dataframe既有行索引也有 列索引,它可以被看做由 Series组成的字典(共用同一个索引)。跟其他类似的 数据结构相比(如R的dataframe), Data frame中 面向行 和 面向列 的操作 基本上是平衡的。其实, Dataframe中的数据是以一个或多个二维块存放的 (而不是列表、字典或别的一维数据结构)。
# 指定列名的顺序
frame=DataFrame(information,columns=["name","age","salary"])
frame
#获取列数据
frame.salary

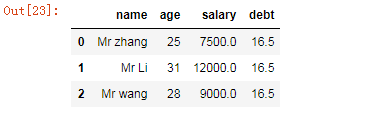
#新增一列
frame["debt"]=16.5
frame

#统计大于30岁的人数
frame.greater_than_30.value_counts()

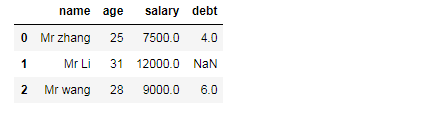
# 使用Series新增数据列
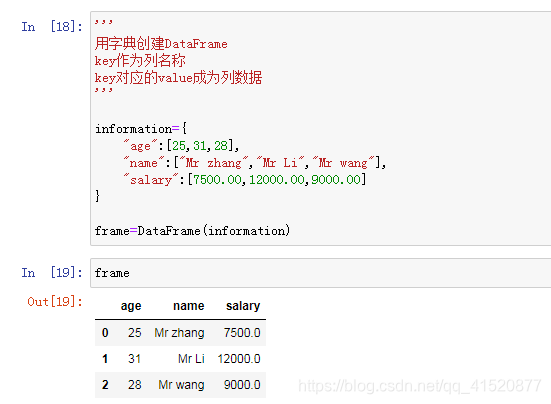
information={
"name":["Mr zhang","Mr Li","Mr wang"],
"age":[25,31,28],
"salary":[7500.00,12000.00,9000.00]
}
df=DataFrame(information)
val=Series([4,6],index=[0,2])
df["debt"]=val
df
# DataFrame的索引和数据
list(df.index) #行索引

df.columns #列索引,即列名称

df.values