语音信号处理第二章
语音信号处理第三章
语音信号处理第四章
语音信号处理第五章
语音信号处理第七章
语音信号处理第九章
语音信号处理第十章
语音信号处理第十二章
注:本博客讲的是考试内容,也涉及到部分实际应用内容。算法部分在考试时着重了解前后向算法和维特比算法的计算过程
隐马尔科夫模型:只能观察到输出符号序列,而不能观测到状态之间如何转移和状态的分布
基于HMM的孤立词识别
基本元素
HMM的基本元素:hmm={A,B,pi}
N:状态数
M:每个状态的观察符号数,基于VQ+HMM时也就是码本数
A:状态转移概率分布矩阵。N×N。aij表示处于i状态时,切换至j状态的概率。i=1,2,…,N,j=1,2,…,N。
B:观察符号概率分布矩阵。N×M。bkj表示处于k状态时输出符号j的概率,k=1,2,…,N,j=1,2,…,M。
pi:初始状态分布矩阵。1×N
HMM用于语音识别要解决三个基本问题
(1)给定观察序列O和HMM模型hmm={A,B,pi},我们怎样有效地计算出给定HMM下出现O的概率P(O|hmm)?
——第一个问题属于评价类问题。从另一个角度来看,这个问题相当于评价给定HMM模型与给定观察序列O的匹配程度。问题1的解决方法能让我们选出最匹配O的HMM模型。
解决方法:Forward-backward算法
(2)给定观察序列O和HMM模型hmm={A,B,pi},我们怎样选择一个与O相应的、能最好地“解释”O的状态序列Q?
——第二个问题主要用于理解模型的物理意义。
解决方法:Viterbi算法
(3)给定观察序列O和初始HMM模型hmm={A,B,pi},我们怎样调整hmm的参数(即A和B)来最大化P(O|hmm)?
——第三个问题相当于使用观察序列O“训练”HMM模型。这个问题是最为重要的,因为问题3的解决方法能让我们根据观测序列O最优地调整HMM参数。
解决方法:Baum-Welch算法
——考虑一个简单的W个词的孤立词识别器。对于字典中每个词,我们想要为其设计一个独立的N状态HMM模型。我们将给定词的语音信号表示为时域编码向量。我们假设使用有M个码字的码本进行编码,因此每个观测序列实际上都是与原始语音信号最接近的码字序号序列。因此,对于字典中每个词,因此,我们拥有由观测序列(即词的码本索引序列)的多次重复组成的训练序列。
——第一个任务是建立词模型。这个任务通过使用问题3的解决方法,即优化模型参数来实现。
——为了能够理解模型状态的物理意义,我们使用问题2的解决方法来将训练序列分段成不同状态,然后研究矢量的属性,这个属性影响了每个状态中观察符号的出现。此处的目标是精炼模型来提升其对序列建模的能力。
——最后,一旦HMM模型设计并优化完毕,可以使用问题1的解决方案对未知词进行识别,与每个词的HMM模型进行评分,然后选择评分最高的作为识别词。
HMM参数初始化
注:本次实验使用离散HMM模型,因此只列出离散HMM模型参数初始化时的步骤。
(1)状态转移概率分布矩阵A的初始化:
——由于本次HMM模型用于语音识别,需要识别出序列随时间的变化,因此使用从左往右的HMM模型,其中aij=0,i>j。aij的初值设置对训练效果影响不大。
(2)初始状态分布矩阵Pi的初始化:
——孤立词识别时,默认从状态1开始。Pi的初始设置同样对训练效果影响不大
(3)观察符号概率分布矩阵B的初始化:
步骤:
1)在计算开始时先设置一套模型参数均值。这套初值可以通过将语音进行等间隔划分状态来获得,也可以由过去的一些实验结果得到。
2)根据此初值构成的HMM,用Viterbi算法将输入的训练语音数据对应于状态进行分割。
3)对于离散型系统,只需将任一状态Sk中标号为j的语音帧出现的次数除以该状态下的全部语音帧的个数,即可得到bkj。
对于连续型HMM,则需要K-均值聚类算法得到M个正态分布的参数,即M个均值和方差。
4)采用Baum-Welch算法对HMM系统参数重新估计。
5)将4)得到的结果同初值进行比较,如果差值小于预设置的阈值,则说明模型参数已经收敛,此时即可将计算结果作为模型参数输出。否则,将计算结果作为新的初值做新一轮计算。
识别步骤
现对于任一要识别的未知孤立字(词)语音,
(0)假设利用HMM进行孤立字(词)必须准备一个HMM,即每一个孤立字(词)有一个HMM加以描述。这可以通过上一步的模型学习或训练来得到训练完毕的HMM;
(1)首先通过分帧、参数分析和特征参数提取,可以得到一组系数随机向量序列X1,X2,……,XT(T为观察值时间长度,即帧数);
(2)再通过矢量量化,就可以把系数随机向量序列X1,X2,……,XT转化为一组符号序列O=o1,o2,……,oT(这个符号序列是由码本的码字组成,而这个码本是一个对于所有类别的模型的一个共同的码本,它由所有类别的数据,通过矢量量化的LBG方法聚类得到);
(3)计算这组符号序列在每个HMM上的输出概率,输出概率最大的HMM对应的孤立字(词),就是识别结果。
前向后向算法
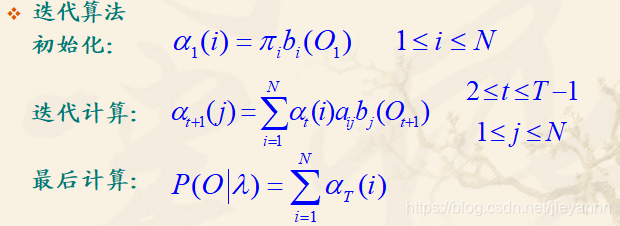
αt(j):在t时刻处于状态j的概率
bj(Ot):状态j输出t时刻的给定观察符号Ot的概率
αij:从状态i切换到状态j的概率
前向算法就是计算**【上一时刻的每一个状态跳转到当前时刻的目标状态的概率之和】× 目标状态输出当前时刻的观测符号的概率**
维特比算法

φt(j):t时刻当前状态为j时,使δt-1(i)aij取最大值的上一状态序号i
argmax[f(x)]:取令f(x)有最大值的自变量x