欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~
本系列笔记对胡航老师的现代语音信号处理这本书的语音处理部分进行总结,包含语音信号处理基础、语音信号分析、语音编码三部分。一开始以为三部分总结到一篇文章里就可以了,但写着写着发现事情并没有那么简单。。。因此还是老老实实的总结吧,扎实的基础最重要。
语音信号处理基础
语音信号的处理简称语音处理,是用数字信号处理技术对语音信号进行处理的一门学科。语音信号均采用数字方式进行处理,语音信号的数字表示可分为两类:波形表示和参数表示。波形表示仅通过采样和量化保存模拟信号的波形;而参数表示将语音信号表示为某种语音产生模型的输出,是对数字化语音进行分析和处理后得到的。
语音的产生过程
语音由发声器官在大脑的控制下的生理运动产生,发音器官包括肺、气管、喉(包括声带)、咽、鼻和口等,这些器官共同形成一条形状复杂的管道,其中喉以上的部分为声道,它随发出声音的不同形状而变化;喉的部分称为声门。发声器官中,肺和器官是整个系统的能源,喉是主要的声音产生机构,而声道则对生成的声音进行调制。

产生语音的能量,来源于正常呼吸时肺部呼出的稳定气流,喉部的声带既是阀门又是震动部件。二两声带间的部位为声门。说话时,声门处气流冲击声带产生震动,然后通过声道响应变成语音。发不同音时声道形状不同,所以能听到不同的声音。喉部的声带对发音影响很大,其为语音提供主要的激励源:声带震动产生声音。声带开启和闭合使得气流形成一系列脉冲。没开启和闭合一次的时间即震动周期,称为基音周期,其倒数为基因频率,简称基频。
语音由声带振动或不经声带振动而产生,其中由声带振动产生的称为浊音,二不由声带振动产生的称为清音。浊音包括所有原因和一些辅音,清音包括另一部分辅音。对于浊音、清音和爆破音,其激励源不同。浊音是位于声门处的准周期麦种序列,清音是位于声道的某个收缩区的空气湍流(类似于噪声),爆破音是位于声道闭合点处建立的起亚及突然地释放。
当激励频率等于震动物体固有的频率时,便以最大振幅来震荡,在该频率上,传递函数有极大值,这种现象称为共振,一个共震体可能存在多个相应强度不同的共振频率。声道是分布参数系统,可以看做是谐振腔,有很多谐振频率。谐振频率由每一瞬间的声道外形决定。这些谐振频率称为共振峰频率,简称共振峰,是声道的重要声学特性。这个线性系统的特征频率特性称为共振峰特性,决定了信号的频谱的总轮廓即包络。 为了得到高质量的语音或准确的描述语音,须采用尽可能多的共振峰。在实际应用中,声学语音学中通常考虑前两个峰,语音合成考虑五个共振峰是最现实的。
语音信号的特性
汉语的特点是音素少,音节少,大约有64个音素,但只有400个左右的音节,即400个左右的基本发音,假如要考虑每个音节有5种音调,也不过有1200多个有掉音节即不同的发音。
元音属于浊音,其声门波形如下图所示,脉冲间隔为基音周期,用g(t)表示。其作用于声道,得到的语音信号是g(t)与声道冲激响应h(t)的卷积。g(t)的频谱是间隔为基频的脉冲序列的频谱与声门波频谱的乘积。
语音信号可看做便利性随机过程,其统计特性可用信号幅度的概率密度及一些统计量(主要为均值和自相关函数)来描述。对语音的研究表明,其幅度分布有两种近似的形式,较好的为修正Gamma分布:
精度稍差的为Laplacian分布:
语音产生的线性模型
人们希望模型既是线性的又是时不变的,这是最理想的模型,但根据语音的产生机理,语音信号是一连串的时变过程,不能满足这两种性质。因此我们需要做出一些合理的假设,使得在较短的时间间隔内表示语音信号时,可采用线性时不变模型。在一般的语音信号经典模型中,语音信号被看做线性时不变系统(声道)在随机噪声或准周期脉冲序列下的输出。这一模型用数字滤波器原理进行公式化以后,将称为语音处理技术的基础。
研究表明语音的产生就是声道中的激励,语音传播就是声波在声道中的传播。假若采用流体力学等建立复杂方程的方法进行研究十分复杂。为了简化,通常对声道形状和发音系统进行某些假设,如假设声道是时变的且有不均匀截面的声管,空气流动或声管壁不存在热传导或粘滞消耗,波长大于声道尺寸的声波是沿声管管轴传播的平面波;更进一步简化,进一步假设声道是由半径不同的无损声管级联得到的。在上述这些假设下,得到级联无损声管模型的传输函数,可以证明对大多数语音,该传输函数为全几点函数,只是对鼻音和摩擦音需加入一些零点。但由于任何零点可用多极点逼近,因此可用全极点模型模拟声道。另一方面,级联无损声管与全极点数字滤波器有很多相同的性质,因而用数字滤波器模拟声道特性是一种常用的方法。
语音信号的产生模型如下图所示:

下面讨论模型中的各个部分。
激励模型
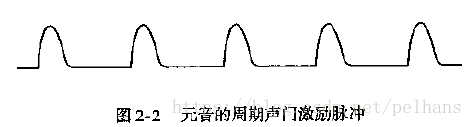
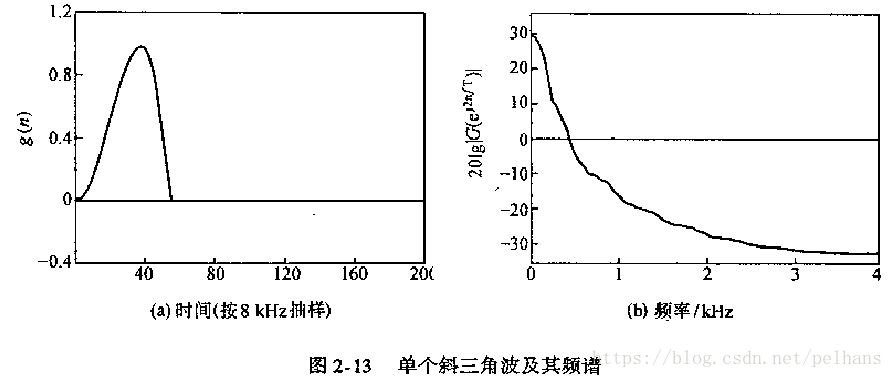
发浊音时,根据测量结果,声门脉冲波类似于斜三角形脉冲,因而激励信号为以基音周期为周期的斜三角脉冲串。单个斜三角波的频谱
如图所示,可见为低通滤波器:
声道模型
声道模型有两种:一个是将其视为有多个不同截面积的管子级联而成,即声管模型;二是将其视为一个谐振腔,即共振峰模型。
声管模型
最简单的声道模型为声管模型,在语音持续的短时间内,声道可表示为形状稳定的管道,如图所示:

声管模型中,每个管子可看做一个四端网络,其具有反射系数,这些系数与LPC参数间有唯一的对应关系。声道可由一组截面积或一组反射系数表示。
共振峰模型
将声道视为谐振腔时,共振峰即为腔体的共振频率。研究表明,用前三个共振峰代表一个元音就可以,而对较复杂的辅音或鼻音,需要用五个以上的共振峰。基于共振峰理论,有三种实用的模型:级联型、并联型和混合型。
级联型认为声道为一组串联的二阶谐振器。根据共振峰理论,整个声道有多个谐振频率和多个反谐振频率(对应声道频率特性的零点),因而可以被模拟为零极点模型,但对一般元音可用全极点模型,将声道看做一个变截面声管,根据流体力学可得在大多数情况下其为全极点函数,此时共振峰用自回归(AR)模型近似。由于采用LPC技术可以高效的求解AR模型系数,因此该模型应用十分普遍。
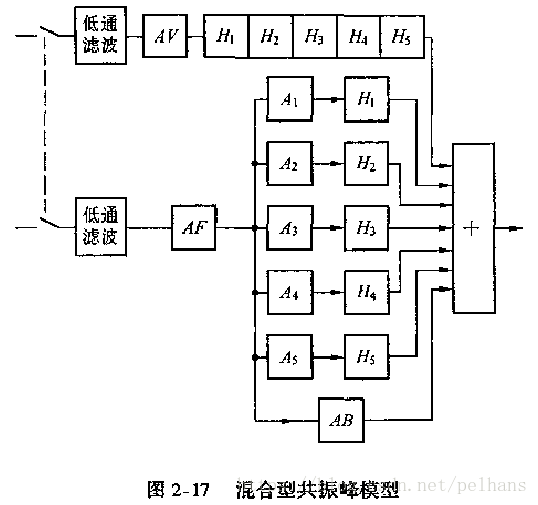
对于比较复杂的元音和大部分的辅音,需要采用零极点模型,可用并联型模型表示。但在实际应用中,上述两种模型都较为简单,可用于描述一般的元音,但当鼻化元音或鼻腔参与共振等情况级联模型就不适用了,此时腔体有反谐振特性,需要加入零点,称为极零点模型,此时称为并联型结构。将级联模型和并联模型结合的混合型是较为完备的共振峰模型,其可根据不同性质的语音进行切换。如下图所示:
辐射模型
声道终端为口和唇。声道输出为速度波,二语音信号为声压波,二者纸币称为辐射阻抗 ,用来表征口和唇的辐射效应,也包括圆形的头部的绕射效应等。口唇辐射在高频端较显著,在低频段影响较小,因而辐射模型R(z)应为一阶高通滤波器形式,公式为:
语音信号模型中,如不考虑周期冲击脉冲串模型E(z),则斜三角波模型为二阶低通,辐射模型为一阶高通,因而实际信号分析中常采用预加重技术,即对信号取样喉插入一阶高通滤波器,从而只剩下声道部分,便于对声道参数进行分析。常用的预加重因子为: ,其中R(n)为语音信号的自相关函数。
完整语音信号数字模型
完整的语音信号模型用三个子模型:激励模型、声道模型和辐射模型的级联表示,其对应的语音信号数字模型如下图所示:

图中,线性时变系统主要用于模拟声道特性,发浊音时的声门脉冲与声波辐射效应这两种影响通常与声道特性合并进行考虑,反应在时变系统中。可以看出,整体模型的基本思想是将模型张总的激励与系统进行分离,是语音信号解体以对二者分别描述,而不是只着眼于信号波形,这是导致语音处理技术飞速发展的关键。
语音信号的非线性模型
非线性模型原因
语音信号的 线性模型假设来自肺部的气流在声道中以平面波形式传播,但20世纪80年代Teager等人的研究表明,声道中传播的气流不总是平面波,有时分离,有时附着在声道壁上。气流通过真正的声带和伪声带间的腔体时会存在涡流,经过伪声带喉的气流又重新以平面波形式传播。因而伪声带处的涡流区域也会产生语音,且对语音信号有调制作用。这样语音信号由平面波的线性部分和涡流区域的非线性部分组成。
FM-AM模型
基于上述非线性现象,并考虑语音由声道共振产生,可得到语音产生的调频-调幅(FM-AM)模型。在该模型中,语音中单个共振峰的输出是以该共振峰频率为载频进行FM和AM的结果,因而语音信号由若干共振峰经这样的调制再叠加,从而用能量分离算法将与每个共振峰对应的瞬时频率从语音中分离出来,由该瞬时频率可得到语音信号的一些特征。公式表述为:
其中,fc为载频,FM信号为q(t),由a(t)控制幅值。载频与每个共振峰对应,瞬时频率为瞬时相位的变化率,即f(t) = fc + q(t),表明载频附近的频率随着调制信号而变化,因而r(t)可看做语音信号中单个共振峰的输出,从而将信号看做若干共振峰调制信号的叠加。
单个共振峰的调制信号r可用ESA(能量分离算法)将AM的幅值包络|a(t)|和FM后的瞬时频率f(t)从语音信号中分离出来。
Teager能量算子
Teager能量算子在连续域和离散域形式不同,在连续域中,可表示为信号s(t)的一阶和二阶导数的函数:
其中, 表示连续的Teager能量算子。它在一定程度上对语音信号的能量提供一种测度,表示单个共振峰能量的调制状态。岂可用于表示两个时间函数间的相关性。将上述公式离散化,用差分代替微分运算,则上式变为:
其中, 表示离散的能量算子。由上式可知,能量算子的输出信号的局部特性只依赖于原始信号及其差分,即为计算能量算子在某时刻的输出,只需要知道该时刻和它前后个一个延迟时刻的信号。对多分量信号用Teager算子将产生交叉干扰,因此一般只用于但共振峰调制信号。
FM-AM模型的应用
该模型在语音分析中被广泛应用,包括共振峰轨迹追踪、基音检测及端点检测等,其中主要是共振峰估计和语音端点检测。
Ref
现代语音信号处理[胡航 电子工业出版社] 第1~2章