欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~
本节针对《现代语音信号处理》这本书的第三章,即时域分析部分。
时域分析
根据语音分析的参数的不同,语音信号分析分为时域、频域、倒谱域、时频域、小波域、高阶累积量域等方法。时域分析具有简单、运算量小、物理意义明确等有点;但更为有效的分析大多围绕频域进行,因为语音中最重要的感知特性反映在其功率谱中,而相位变化只起到很小作用。另一方面,按照语音学观点,可将语音特征的表示和提取分为模型分析和非模型分析两种。模型分析是一句语音产生的数学模型,分析和提取其模型的特征参数,包括共振峰模型法以及声管模型即LPC等。不进行模型分析的其他方法属于非模型法,时域、频域以及同态分析等。
贯穿语音分析全过程的是短时分析技术。因为语音信号特性随时间变化是非平稳随机过程,因此语音信号具有时变特性,但短时间内其特性却基本不变,具备短时平稳性。在此基础上,对语音信号流进行分段处理,即帧。语音通常在10~30 ms内保持相对平稳,因而帧长一般取10~30 ms。
数字化和预处理
为了将模拟语音信号转化为数字信号,需要经过取样和量化两个步骤,以得到时间和幅度均离散的信号。
取样是将时间上连续的信号离散化为样本序列,根据奈奎斯特采样定理,取样频率大于信号两倍宽度时,取样过程不会丢失信息,且取样信号可精确地重构原信号。若不满足取样定理,将产生频谱混叠,此时信号中的高频成分将产生失真。
取样后需要对信号进行量化,即将时间上离散而幅度仍然连续的波形再离散化。其过程是将整个幅度值分割为有限个区间,将落入同一区间的样本赋予相同的幅度值。若量化阶梯选择的足够小(如64),则信号幅度从一个取样值到相邻取样值的变化可能非常大,常跨越很多量化阶梯。这样产生的量化噪声接近平稳白噪声过程。一般而言,8bit时的噪声自相关函数几乎为冲激函数,与白噪声的过程相一致。
若用 表示语音信号方差, 表示信号峰值,B表示量化字长, 表示噪声方差,则可证明量化信噪比(信号与量化噪声的功率之比)为:
假设信号服从Laplacian分布,此时信号幅度超过 的概率很小,因此上式可简化为:
上式表明,量化器中每比特字长对SNR贡献为6dB,结合研究表明,语音信号的波形动态范围可达55dB,因此B应该取10以上。
更进一步分析前有时还需要进行其他的预处理,包括放大及增益控制、反混叠滤波(有良好截止特性的模拟低通滤波器对信号进行滤波)、预加重等,对有语音输出的场合还需要进行D/A 变换和起平滑作用的低通滤波。具体流程如下图所示:

短时能量分析
对语音信号短时分析,信号刘用分段或分帧实现。分帧可用移动的有限长窗口加权来实现。窗每次移动的距离如窗宽度相同,则各帧信号相互衔接,若移动距离比窗宽小,则邻帧间有部分重叠。
不同的窗口选择(形状、长度)将决定短时能量的特性。应选择合适的窗口,使得平均能量更好的反应语音信号的幅度变化。常用的窗口如直角窗、Hamming窗、Hanning窗、Blackman窗、Kaiser窗等均为对称形状的窗口。下面主要介绍一下最常用的直角窗和Hamming窗。
首先给出短时平均能量的定义:
E(n)为语音信号一个短时间段内的能量,且以n为标志。其中w(n)是窗函数,x(m)表示语音信号,N为窗口内采样的总数(不确定,书上公式各变量含义完全没给)。下图给出短时平均能量计算的说明:
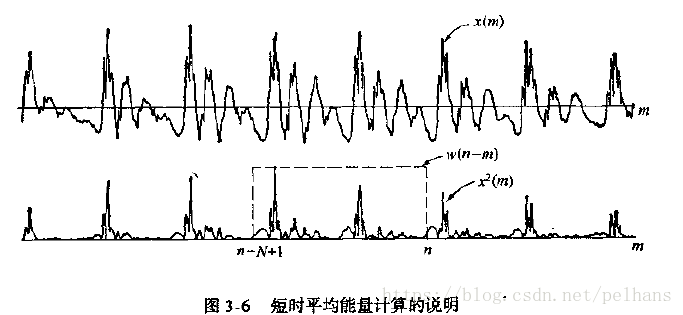
进一步整理,上式可改写为:
其中:
上式表明,短时平均能量相当于语音信号的平方通过单位函数响应为h(n)的线性滤波器的输出。
直角窗
相应数字滤波器的频率特性为:
具有线性相频特性。
Hamming 窗
下图给出直角窗和Hamming窗的对数幅频特性,可见Hamming窗的第一个零频率位置比直角窗大1倍左右,即带宽增加1倍。同时带外衰减也比直角窗大得多。直角窗谱平滑效果较好,但细节丢失,Hamming窗则相反。对于窗宽则是相对语音信号基音周期而言的。在10kHz采样率下,通常折中选取100~200,对应帧长10~20 ms。当N过小时,短时平均能量函数波形起伏较快,过大时波形变化缓慢,因此选择合适的N值很重要。

短时过零分析
过零分析是语音时域分析中最简单的一种,它是指信号通过零值。对连续语音信号,对应的是波形通过时间轴的情况。对离散时间信号,相邻取样值改变符号即过零。可以用平均过零数对频谱频率做估计。
语音信号x(n)的短时平均过零数为:
其中w(n)是窗口序列,sgn是符号函数。
利用短时过零数在语音分析中,由于它来粗略的描述了信号的频谱特性,因而可以用来区分清音/浊音(清音时能量集中在高频,浊音相反)。利用平均过零数还可以从背景噪声中找出语音信号,用于判断无语音和有语音的起点和终点位置。
短时相关分析
相关分析是常用的时域波形分析方法,分自相关和互相关两种,分别用自相关函数和互相关函数表示。相关函数用于测定两个信号的时域相似性,如用互相关函数可以测定两信号的时间滞后或从噪声中检测信号。如两个信号完全不同,则互相关函数接近于零,如良心好波形相同,则在超前、滞后处出现峰值,由此可以得到两个信号的相似度。而自相关函数用于研究信号自身,如波形的同步性、周期性等。本节主要介绍自相关函数。
短时自相关函数
对于确定性信号序列,自相关函数的定义为:
对于随机性或周期性信号序列,自相关函数定义为:
上式中,k表示计算k次自相关滞后。由上式可知:
- 若序列是周期性的,则自相关函数是同周期性的周期函数。
- 自相关函数为偶函数
- 在k=0时自相关函数具有极大值
- R(0)表示确定性信号的能量或随机性信号的平均功率。
由以上性质可以英语语音信号时域分析中,如性质1可以用自相关函数的第一个最大值的位置来估计周期。
短时自相关函数的定义为:
相当于在确定性信号序列上加了窗。若定义:
则:
因此,短时自相关函数可以看做x(n)x(n-k)通过单位函数响应为 的数字滤波器的输出。
下图给出三个自相关函数的例子,其中图a和b为做一年语音段,c为清音段。有图a和b可见,对应于浊音段的自相关函数有一定周期性,像个一定取样后达到最大值。而图c的自相关函数没有很强的周期峰值,表明信号中缺乏周期性。

修正的短时自相关函数
在语音处理中,计算自相关函数所用的窗口长度与平均能量等情况有所不同,其至少要大于二倍基因周期,否则找不到第二个最大值点。另一方面N要尽可能小来保证短时性。为了解决这一问题,可以用修正的短时自相关函数代替短时自相关函数,以便使用较窄的窗。修正的短时自相关函数定义为:
可以看出,相比于原公式,其w1和w2用了不同长度,这样可以消除可变上限引起的自相关函数的下降。选取w2使其包括w1的非零间隔外的取样。
语音端点检测
语音的端点检测即判断目标语音的开始或结束。在汉语中,音节末尾基本都是浊音,之简单地用短时能量就可以较好地判断一个词语的末点。一般只要短时平均幅度降低到该音节最大短时平均幅度的1/16时就可以认为该音节已经结束。相比之下,汉语的起始点检测则有难度,而且对语音识别的性能影响很大,这是因为音节起始处的大多数声母为清音母,还有送气与不送气的塞音和摩擦音,很难将他们汉语环境噪声相区别。下面简单介绍集中检测语音起点的方法,更详细的内容还请进一步查阅资料。
双门限前端检测
双门限法利用的参数为短时能量和短时过零率。双门限法时考虑到语音开始后总会出现能量较大的浊音,设置一个较高的门限Th已确定语音已经开始,在取一个比Th低的门限Tl来确定真正的起止点和结束点。该方法广泛应用于有/无声判别或语音前端检测。通常窗长取帧长。
多门限过零率前端检测
双门限法与单门限法相比可以明显的减少误判单有时存在较大的延迟。因为首次找到高门限越过点可能往前推很远才能找到起点,从而难以实现实时处理。多门限法通过使用多个门限,对每帧分别求出相应的T1,T2, T3三个门限的过零率Z1,Z2,Z3。再用加权和表示总过零率。当T和w选择合理时,那么语音开始后的Z值将明显大于无声时的Z。这种方法已经普遍用于语音室别中的实时特征提取。
基于FM-AM模型的端点检测
该方法是基于Teager能量算子的,因为Teager能量算子不仅反映幅度的变化,也反映频率的变化。幅值或频率变化的越快,能量算子输出越大。基于Teager能量算子的方法比基于短时能量的方法有更好的效果。
基于高阶累计量的语音端点检测
非高斯信号的主要数学分析工具时高阶累计量及基于高阶累计量的高阶谱估计。这是因为对任何类型的高斯信号,其三阶以上的高阶累计量均为0。利用该特性可抑制噪声。同时高阶累计量还可用于盲源分离。
Ref
现代语音信号处理[胡航 电子工业出版社] 第三章 时域分析