声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
一.Selenium简介
最近博主在学习爬虫的过程中遇到了一个强无敌的工具—Selenium,通过它使得我们的爬虫过程可以像真正的用户在手工操作一般十分有趣,Selenium的大概编程思路如下:
- 获取一个WebDriver对象
- 通过get(url)获取加载完毕的页面
- 利用Selenium中的方法查找或操作页面元素
- 关闭浏览器窗口
二.爬取网页分析
2.1 B站首页获取搜索框和按钮
在进入B站首页后,我们通过Selenium相关函数获取首页的输入框和搜索按钮,然后通过模拟用户输入和点击按钮跳转到带爬取的页面。

在进入到相关的网页后,我们可以通过BeautifulSoup库来获取我们想要的信息。待页面分析完后,我们可以通过操作“下一页”按钮等元素来进行翻页跳转操作。
2.2 网页带获取信息分析
我们可以先手动输入“川建国”,然后打开相应的界面,可以看到建国同志还是比较受欢迎的,其视频页数有50多页。首先,选中第一个视频然后右键,点击检查选项,下面的作图为操作示例,右图该元素对应的源代码:


根据上述结果我们可以看出所有的视频都是一个列表的列表项,我们将右图展开如下

根据上述展开的内容,我们可以使用BeautifulSoup有关函数进行如下操作:
- 通过
findAll()来获取页面中所有的视频元素 - 通过
find()函数来获取视频元素中的<a>标签,并通过get('title')和get('href')分别获取视频名和视频链接 - 通过
find()函数分别获取包含观看量和弹幕数的<span>标签中的文本
三.爬虫详细过程
3.1 获取B站首页待操作元素
通过xpath可以获取B站首页的输入框和按钮,然后可以通过Selenium的相关函数来模拟用户输入和点击搜索操作。
def FirstPage(keywords):
"""
进入B站待爬取的页面并返回带爬取的页面数
"""
try:
#进入B站主页
driver.get("https://www.bilibili.com/")
#获取主页的搜索输入框和按钮
input = WAIT.until(EC.presence_of_element_located((By.XPATH,"//form[@id='nav_searchform']/input[@type='text']")))
button = WAIT.until(EC.element_to_be_clickable((By.XPATH,"//form[@id='nav_searchform']//button[@type='button']")))
#在B站主页面输入搜索关键词
input.send_keys(keywords)
#点击搜索按钮
button.click()
print("-----------------正在爬取第1页-----------------")
#跳转至待爬取页面
hds = driver.window_handles
driver.switch_to_window(hds[-1])
return getPages()#返回待爬取的总页数
except TimeoutException:
FirstPage()
说明:上述结果中使用了webdriver提供的显式等待方式来等待页面元素被加载。
3.2 获取待爬取的总页数
要获取视频总页数可以通过视频下方的按钮,通过获取按钮对应的文本即可得到总页数,代码示例如下:
def getPages():
"""
获取页面数
"""
#获取页数最大的按钮
pages = WAIT.until(EC.presence_of_element_located((By.XPATH,"//div[@id='all-list']/div[@class='flow-loader']//ul[@class='pages']//button[@class='pagination-btn']")))
return int(pages.text)
3.3 操作“下一页”按钮实现跳转
如何跳转到下一个待爬取的页面呢?很简单就像人工操作那样点击下一页按钮,只不过这里采用了Selenium来进行模拟,同样我们可以先获取该按钮,然后”点击“(通过click()函数)即可。
next_button = WAIT.until(EC.element_to_be_clickable((By.CSS_SELECTOR,"#all-list > div.flow-loader > div.page-wrap > div > ul > li.page-item.next > button")))
next_button.click()
3.4 获取网页中的有用信息
Selenium可以通过driver.page_source获取网页源码,然后我们就可以利用2.2节中介绍的相关函数来进行网页信息的抓取。
def parseHTML(html):
"""
解析HTML页面
"""
vlist = []
soup = BeautifulSoup(html,'lxml')
#获取视频列表中的所有视频
videos = soup.findAll('li',attrs = {"class":"video-item matrix"})
for video in videos:
title = video.find('a').get('title') #通过<a>标签获取视频名
href = video.find('a').get('href')[2:] #通过<a>标签获取视频链接
times = video.find('span',attrs = {"class":"so-icon watch-num"}).text.strip() #通过<span>标签获取观看量
barrage = video.find('span',attrs = {"class":"so-icon hide"}).text.strip() #通过<span>标签获取弹幕数
print(title,href,times,barrage)
vlist.append([title,href,times,barrage])
return vlist
3.5 保存到Excel中
通过openpyxl模块,我们可以将之前保存到列表中的视频信息最后保存到excel中去。
def Saver(vlist):
"""
vlist:视频信息列表
将数据保存在excel中
"""
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = '爬虫结果'
sheet.cell(1,1,'视频名')
sheet.cell(1,2,'视频链接')
sheet.cell(1,3,'播放量')
sheet.cell(1,4,'弹幕数')
for idx,m in enumerate(vlist):
sheet.cell(idx + 2,1,m[0])
sheet.cell(idx + 2,2,m[1])
sheet.cell(idx + 2,3,m[2])
sheet.cell(idx + 2,4,m[3])
workbook.save(u'JianGuo_info.xlsx') # 保存工作簿
完整源码地址:selenium_demo
四.成果展示
程序运行截图如下:
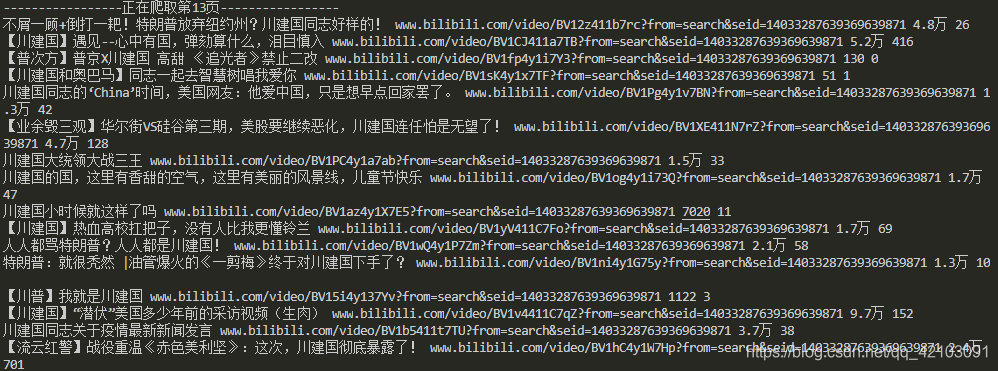
excel中保存的部分结果截图如下:

五结语
在本文中,博主直接使用了ChromeDriver来测试程序,但是这样对于程序员来说不是特别友好,更好的方式是使用phantomJS,即通过phantomJS来获取Driver这样就可以直接在程序中进行测试而不会打开浏览器窗口了。最后我提供一些干货供大家自取:
- Selenium的安装:可以直接使用pip命令
- ChromeDriver下载地址
- 官方教程
- 某大佬的中文教程
- 另一大佬的学习笔记
以上便是本文的全部内容,要是觉得不错就支持一下吧,你们的支持是博主继续创作下去的不竭动力!!!