前端为什么需要模块化?
JS作为一门脚本语言,在ES6之前是没有模块化这个概念的。
所以多人协作开发过程中,在引入各种各样的js文件后,代码结构就会变得相当复杂,很容易引起全局变量命名冲突等问题。
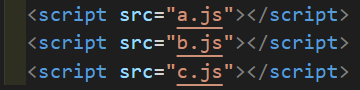
我们先看一个情景:分配任务让小明负责编写 a.js 和 b.js ,小红负责编写 c.js 。
小明在 a.js 定义了一个变量 flag = true,并且打算在 b.js 中使用这个变量,他希望在 a.js 中通过控制 flag 变量来控制 b.js 中的输出情况。
// 小明写的 a.js
var flag = true// 小明写的 b.js
if (flag) {
console.log('我接受到了true的flag');
}但是小红并不知道小明已经定义了一个flag变量,所以她在 c.js 中也定义了一个变量 flag = false。
// 小红写的 c.js
var flag = false如果这时将这三个文件按 a 、 b 、 c 的顺序引入 main.js ,效果如下:
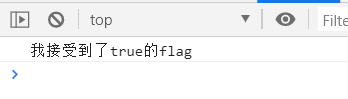
但实际上,文件的引入顺序是充满着随机性的。
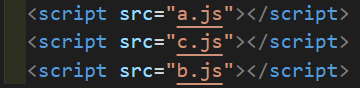
虽说,小明知道 a.js 和 b.js 的引入先后顺序( 先引入a.js,b.js才能拿到a.js中的flag ),但是小红只负责一个 c.js ,所以她是有可能把 c.js 插入在两者之间引入。
所以当这三个文件按照非预期的顺序引入时,意料之外的事情就会发生了。
很明显,由于在a.js之后、b.js之前引入了c.js,所以c.js中的flag覆盖掉了a.js中的flag。
因而此时全局 flag = false,所以b.js并没有按预期输出。
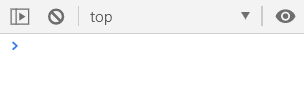
当然,你可以坚持说通过规定引入顺序(以 a、b、c 的顺序)来避免这种情况,或者通过规定变量命名(以flag1、flag2来区分)来避免出现这种情况。
但终究这些措施还是不太方便,我们需要模块化来管理。
ES5 如何实现模块化?
ES5 中没有 ES6 中的模块化语法,但如果又不使用 common.js 这一些模块化方法,该如何模拟实现呢?
模块化的核心就是 导出 和 导入 。
如下,我们对上面的三个文件进行修改:
// 小明写的 a.js
var moduleA = (function () {
var obj = {}
obj.flag = true;
return obj
})()// 小明写的 b.js
(function () {
if (moduleA.flag) {
console.log('我接受到了true的flag');
}
})()// 小红写的 c.js
var moduleB = (function () {
var obj = {}
obj.flag = false;
return obj
})()- 在每个文件中使用立即执行函数来创建一个函数作用域,每个文件都互不干扰,就不会出现命名冲突的问题了。
- 但是如果每个文件都是独立的存在,互相之间没有任何关系,就没有了代码复用的可能,似乎带来的损失也不小。
- 所以,立即执行函数可以再返回一个对象,形成一个闭包,然后将对象存于一个全局变量( module )中。
- 这样一来,每个文件可以通过这种方式选择性地导出自己的变量 / 方法,而每个文件又可以通过引入这些全局变量来使用其他文件的变量 / 方法。
- 到此,文章开篇提到的问题就被简化成了规范全局变量的命名的问题,即只需要规范module变量的命名,保证这些全局的module变量不冲突即可。即小明只需要保证 a.js 在 b.js 之前引入即可,而不再需要管 c.js 是在 b.js 之前或之后引入,因为 b.js 已经是明确引用了moduleA中的flag,所以不会再出现上述问题。
- 这样就可以既减少无谓的干扰,又保留了代码的复用性。