爬取新浪新闻的链接:
https://blog.csdn.net/Iv_zzy/article/details/107535041
爬取中国新闻网的链接
https://blog.csdn.net/Iv_zzy/article/details/107537295
与获取新浪新闻思路不同,新浪新闻的获取是先把所有的链接存入csv文件,再统一对所有的链接解析。本人对网易新闻的获取采用边解析链接、边获取链接的内容(本人尽可能提供不同的方法,若需要,对照修改使用即可)
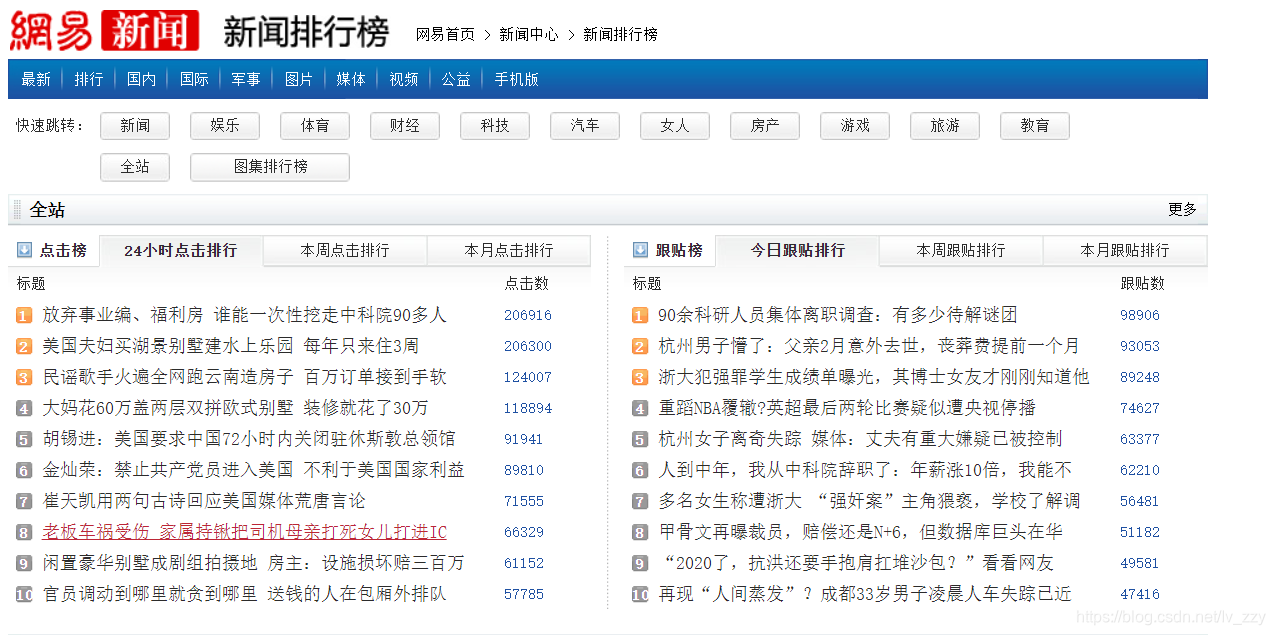
网易排行榜如下图所示
以娱乐新闻为例,点击娱乐,到了这个界面
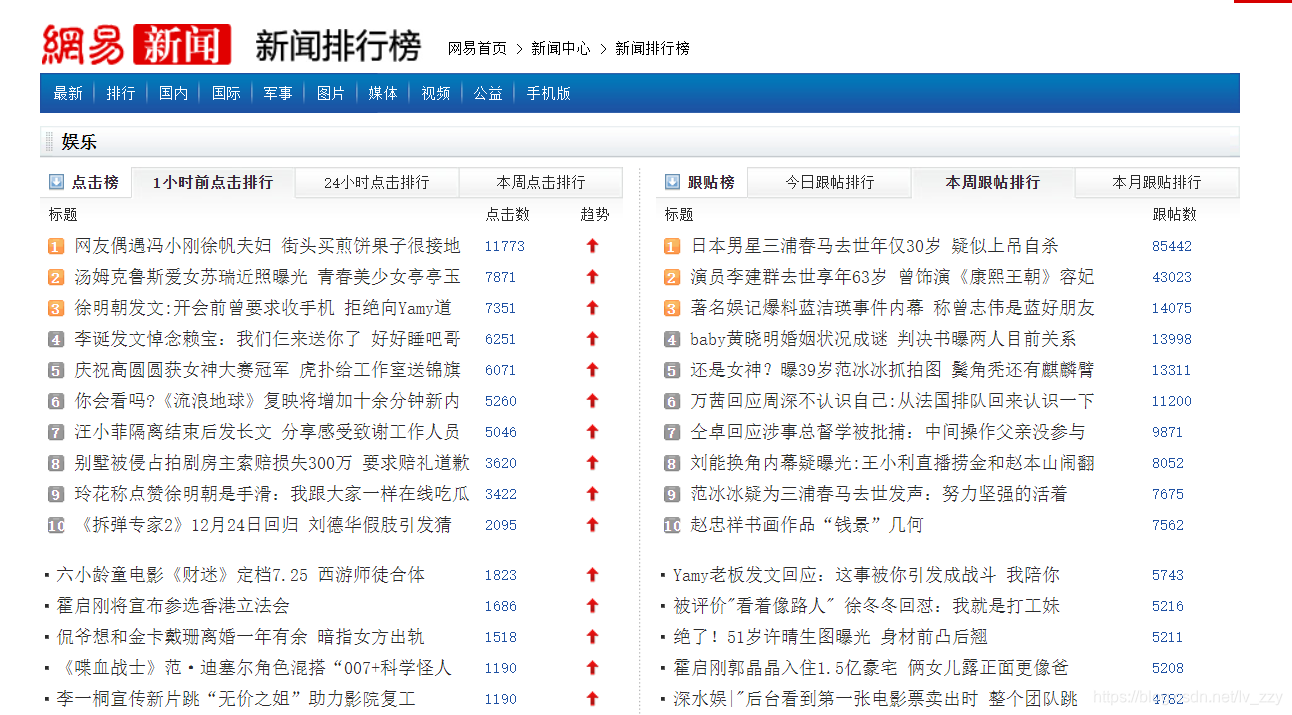 网页链接为:
网页链接为:
http://news.163.com/special/0001386F/rank_ent.html
1、首先,从网页上获取带有链接的title
此处是返回一个list
def Initpage(url, headers):
res = requests.get(url, headers = headers)
res.content.decode('gb18030','ignore') #原网页gbk
soup = BeautifulSoup(res.text, 'html.parser')
#print(soup.prettify())
titles = soup.find('div', 'area-half left').find('div', 'tabContents active').find_all('a') #list
return titles
出来的结果是:

2、对list内的title一个个分解取出链接,获取内容
def parse(titles, headers):
count = 0
for title in titles:
#get urls from html
news_url = (str(title.get('href')))
#read each url
news_response = requests.get(news_url, headers=headers)
news_html = news_response.text
news_soup = BeautifulSoup(news_html, 'html.parser')
#analyze html to find news' title and news' content
if news_soup.find('div', 'post_text') is None: #if html loose, jump out circulation
continue
news_title = news_soup.find('h1').text
contents = news_soup.find('div', 'post_text').find_all('p')[:-2]
news_contents = ""
for content in contents:
if len(content.text)<=0 or ("video" in content.text) or ("img" in content.text):
continue
else:
news_contents = news_contents + content.text.strip()
count = count + 1
try:
print(news_title,news_contents)
print('第'+ str(count) + '条新闻写入成功')
except:
print('第'+ str(count) + '条新闻抓取失败,正在尝试下一条')
另外,需要补充的是,本人尝试将新闻内容存储到数据库,如若有需要的,可以参考以下内容
连接数据库
def con_db():
try:
global db
db = pymysql.connect('localhost','root','123456','newsDB',charset='utf8')
except pymysql.Error as e:
print("Error: {}".format(e))
cur = db.cursor()
print('connection success')
return cur
插入数据
def insert_news(news_title,news_contents):
category = '娱乐' #更改类别
sqli = '''
insert into WYnews(category,newsTitle,newsContent)
values("%s","%s","%s")
'''%(pymysql.escape_string(category),pymysql.escape_string(news_title),pymysql.escape_string(news_contents))
cur.execute(sqli)
time.sleep(1)
若数据量过大,推荐使用多进程处理,处理方法在我前面的文章里有简单介绍
https://blog.csdn.net/Iv_zzy/article/details/107535041
如有转载,请注明出处,谢谢~