首先豆瓣电影排行榜的榜单是ajax异步加载的,不会一下子全部加载完,随鼠标下拉逐步加载数据,f12观察network请求和网站源码可轻易发现
榜单list的url地址,其response是json格式返回值
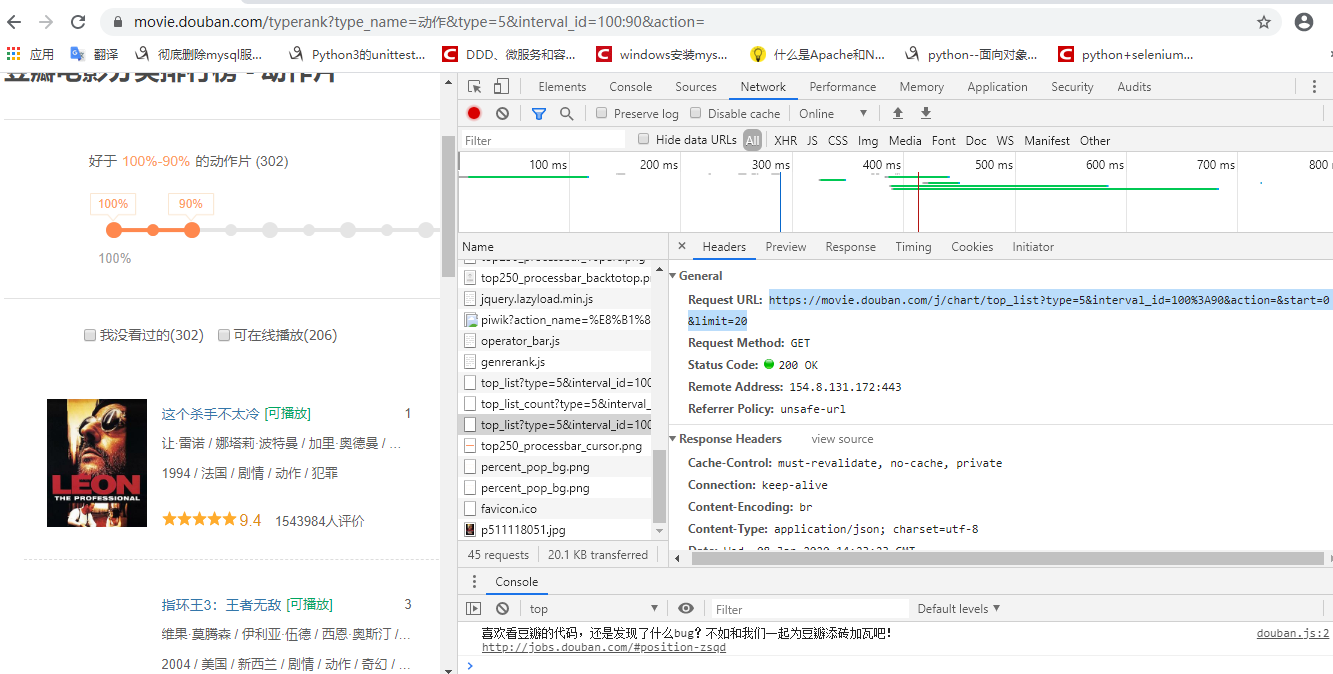
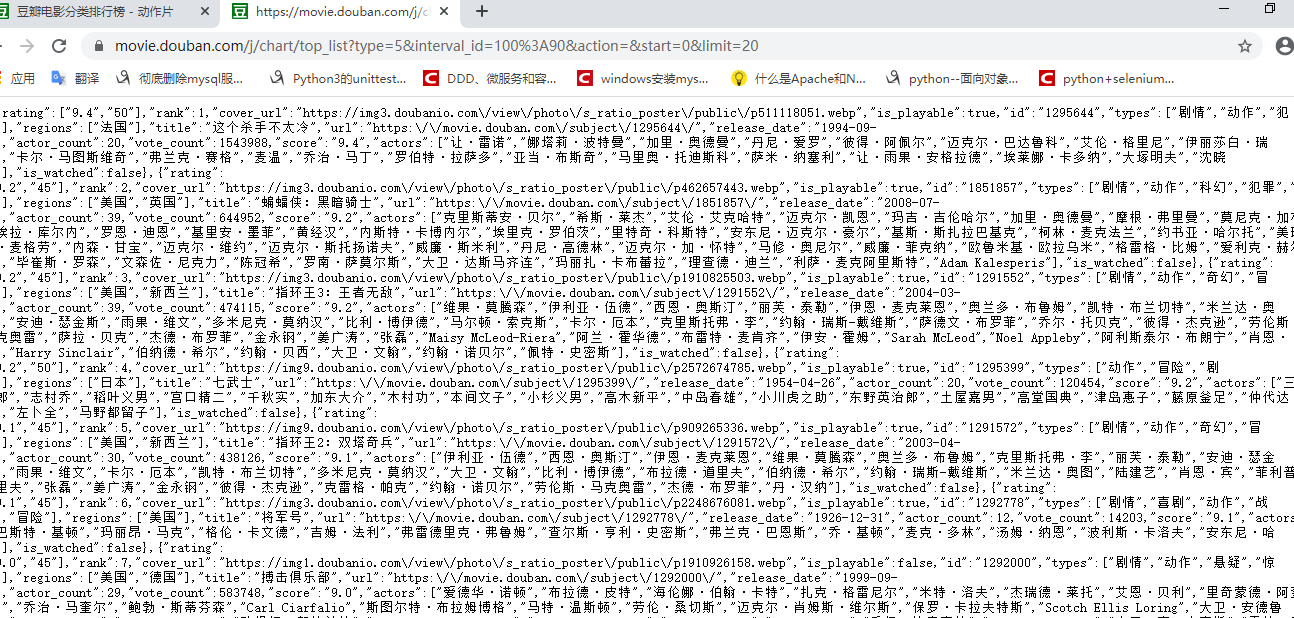
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
当然我们可以使用urllib库方便地拼接接口地址,limit可以设置为100,即可获得百top排行版电影的json串。
代码如下:
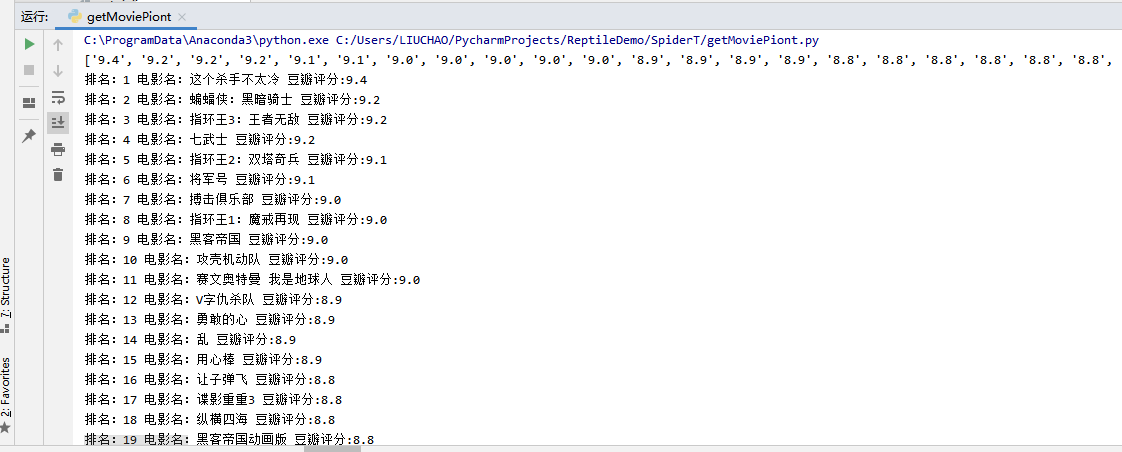
import urllib.request import re headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0"} url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=100" res = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(res).read().decode() pat1=re.compile(r'"rating":\["(.*?)","\d+"\]') pat2=re.compile(r'"title":"(.*?)"') data1=pat1.findall(data, re.I) data2=pat2.findall(data, re.I) print(data1,data2) for x in range(len(data1)): print("排名:{0} 电影名:{1} 豆瓣评分:{2}".format(x+1, data2[x], data1[x]))
运行效果: