数据存储(TXT)
在爬虫中,用解析器解析出数据后,接下来就是存储数据。
1 文件存储
1.1 TXT文本存储
TXT文本几乎可以兼容任何平台,但有个缺点就是不利于检索。
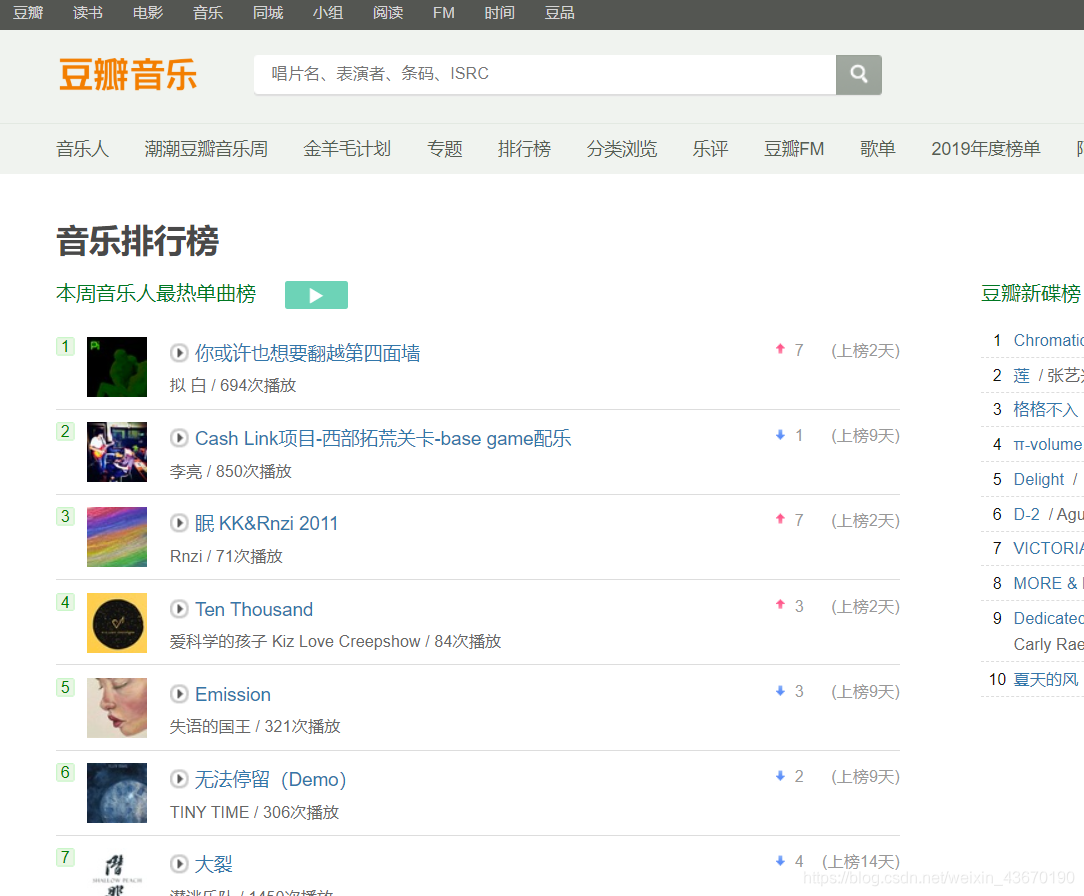
我是爬取下面这个页面中的内容来做练习:
一共有20首歌曲。截图就截了上面一部分。
import requests
from pyquery import PyQuery
url = 'https://music.douban.com/chart'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
req = requests.get(url, headers=headers)
response = req.text
# print(response)
doc = PyQuery(response)
items = doc('.col5 li').items()
# print(items)
# 创建一个空列表,用来存储数据
data_list = []
for li in items:
# 获取每个li节点里的所有文本然后添加进列表中
data = li.text()
data_list.append(data)
# print(data)
# print(data_list)
with open('豆瓣音乐排行榜.txt', 'w', encoding='utf-8') as f:
for dl in data_list:
# 遍历列表,将遍历的内容都存储进txt文本中
#print(dl)
f.write(dl)
f.write('\n' + '=' * 50 + '\n')
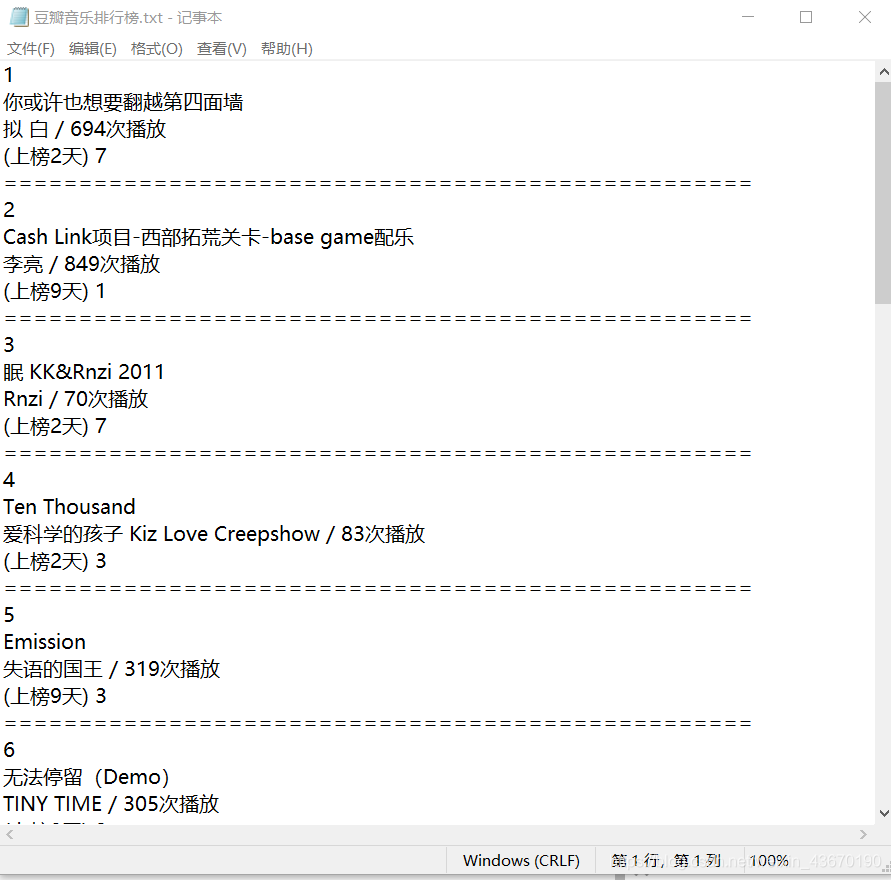 截图是一部分。
截图是一部分。
一开始存储后的文件老是只有最后一首歌曲的文本内容,搞了半天一直这样,最后发现是遍历列表的for循环没有放在with as中,后面试了一下才成功。
希望自己能掌握好这些基础的东西。要加油啊。