集合

集合继承图中可以看到List和Set集合都实现了Collection接口,而Map集合实现Map接口,这篇博客先讲一下List集合。
List(有序、可重复)
ArrayList

ArrayList是我们经常使用的动态数组,其优点就是数组大小可动态增长,效率高,但线程不安全。
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
ArrayList的扩容机制
看下源代码:
1)
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
2)
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
3)
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
4)
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
5)
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
ArrayList的扩容主要发生在向ArrayList集合中添加元素的时候。由add()方法的分析可知添加前必须确保集合的容量能够放下添加的元素。主要经历了以下几个阶段:
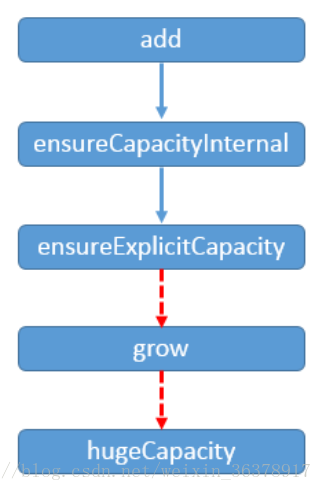
Arraylist 在add新元素前,是先会去判断数组的长度够不够,如果不够的话,会先扩容,1.5倍+1吧,然后将旧数组复制到新的长度的数组中吧,然后再把要新添的元素复制到elementData[size++]上
第一,在add()方法中调用ensureCapacityInternal(size + 1)方法来确定集合确保添加元素成功的最小集合容量minCapacity的值。参数为size+1,代表的含义是如果集合添加元素成功后,集合中的实际元素个数。换句话说,集合为了确保添加元素成功,那么集合的最小容量minCapacity应该是size+1。在ensureCapacityInternal方法中,首先判断elementData是否为默认的空数组,如果是,minCapacity为minCapacity与集合默认容量大小中的较大值。
第二,调用ensureExplicitCapacity(minCapacity)方法来确定集合为了确保添加元素成功是否需要对现有的元素数组进行扩容。首先将结构性修改计数器加一;然后判断minCapacity与当前元素数组的长度的大小,如果minCapacity比当前元素数组的长度的大小大的时候需要扩容,进入第三阶段。
第三,如果需要对现有的元素数组进行扩容,则调用**grow(minCapacity)**方法,参数minCapacity表示集合为了确保添加元素成功的最小容量。在扩容的时候,首先将原元素数组的长度增大1.5倍(oldCapacity + (oldCapacity >> 1)),然后对扩容后的容量与minCapacity进行比较:① 新容量小于minCapacity,则将新容量设为minCapacity;②新容量大于minCapacity,则指定新容量。最后将旧数组拷贝到扩容后的新数组中。
总结:
实现机制:ArrayList.ensureCapacity(int minCapacity)
首先得到当前elementData 属性的长度oldCapacity。然后通过判断oldCapacity和minCapacity参数谁大来决定是否需要扩容, 如果minCapacity大于 oldCapacity,那么我们就对当前的List对象进行扩容。 扩容的的策略为:取oldCapacity*1.5和minCapacity之间更大的那个。然后使用数组拷贝的方法,把以前存放的数据转移到新的数组对象中 如果minCapacity不大于oldCapacity那么就不进行扩容。
Vector

优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
ArrayList和Vector的主要区别:
(1)Vector是多线程安全的,而ArrayList线程不安全,Vector类中的方法很多有synchronized进行修饰。
(2)Vector可以自定义增长容量(capacityIncrement),而ArrayList不可以,源代码如下:
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
LinkedList

优点: 底层数据结构是链表,增删快。
缺点: 线程不安全,查询慢。
数组是在连续的存储位置上存放对象的引用,而链表则是将每个对象存放在单独的链接中。
/**
* Constructs an empty list.
*/
public LinkedList() {
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
上面是LinkedList的两个构造函数,第一个方法是构造一个空的List,第二个方法是复制一份已有的List,Collection<? extends E> c可以看到对泛型类型的要求,泛型要求该类型需要“继承”E,也就是需要是E的子类。
内部类Node节点
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
element:存放元素,pre:用来指向前一个元素,next:指向后一个元素,构成链表
看下两个基本的方法:
add(e)
1) public boolean add(E e) {
linkLast(e);
return true;
}
2) /**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
可以看到add方法是调用了linkLast方法,final Node newNode = new Node<>(l, e, null);将新的链表pre指向了last节点,存放元素e,next节点设为Null。然后将新的节点设为last。后续根据原链表中是否为空进行选择。
remove(int index)
1) public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
2) /**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3)
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
4) /**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
过程:根据index定位到Node节点,将Node节点在链表中移除。这里比较耗性能的是查找Node节点,
判断index 与size >> 1的关系,也叫是折半查找,只不过只折了一次,后续通过一个for循环遍历链表,如果链表很大的话,每次遍历都会很耗性能,这也是链表查询慢的原因。
以上就是Java集合List的总结,内容不是很充分,我也是参考了很多博客,列出一些个人认为比较重要的地方,大家可以从下面的这几篇博客中继续学习:
相关博客:
https://www.cnblogs.com/linliquan/p/11323172.html
https://www.cnblogs.com/chenglc/p/8073049.html
https://blog.csdn.net/feiyanaffection/article/details/81394745