Java中的集合
最近心血来潮想着做一个关于Java集合的一个摘要总结,所以也便有了此文,本文适合任何水平的朋友阅读。
在讲解Java中集合之前先来看张图:

这张图就是Java中的所有集合的分布图。
## 由图可见在Java中集合主要分为3种:(List、Set、Map)。
## 本质上List、Set、Map都是接口,而下面的(Vector、ArrayList、LinkedList、HashSet、TreeSet、HashMap、TreeMap、WeerkHashMap、Hashtable)都是上面三个接口的实现类(这语句蕴含着为什么只能new ArrayList<?>(),不能new List<?>()的问题的答案)。
-1).List集合还可以下分为:(ArrayList、Vector、LinkedList)。
-2).Set集合还可以下分为:(HashSet、TreeSet)。
-3).Map集合还可以下分为:(HashMap、TreeMap、WeekHashMap、Hashtable)。
## 下面我们就来一起探究一下Java中的每一个集合的真实面目。
List(有序、可重复): -> ArrayList(底层依赖数组存储)
-1).特点:底层是基于数组的数据结构(后面我们会读源码)、查询快但增删慢、线程不安全、效率高。
-2).使用方法:
// 声明List集合
private static List<Person> list = new ArrayList<Person>();
public static void main(String[] args) {
// 获取Person类中的实例
Person person_1 = new Person("LJ", 21);
Person person_2 = new Person("XXY", 22);
// 向ArrayList集合中存储值
list.add(person_1);
list.add(person_1);
list.add(person_2);
// 打印
System.out.println(list);// 说明ArrayList中是可以存储重复对象的
// 再创建一个集合
List<Person> list2 = new ArrayList<Person>();
list2.add(new Person("小明", 100));
list2.add(new Person("小红", 100));
list.addAll(list2);
System.out.println(list);
// 删除元素
list.remove(0);
list.remove(person_1);
System.out.println("list集合中是否含有person_1对象"+list.contains(person_1));// 打印false ->
// 查找ArrayList集合中是否有指定元素并返回布尔值。
System.out.println("list集合是否为空:" + list.isEmpty());// 打印false
// 将集合转换为数组
Person[] array = list.toArray(new Person[]{});
System.out.println(array[0]);
list.set(2, new Person("小亮", 100));// 打印,将邓小平换成了周恩来
// list.set(3, new Person("小莉", 100));// 报错IndexOutOfBoundsException说明只能在现有的元素基础上进行修改
int num = list.indexOf(person_2);
System.out.println("查询到的索引为:" + num);// 打印0
// 通过遍历器对ArrayList集合进行遍历
ListIterator<Person> listItor = list.listIterator();
while (listItor.hasNext()) {
System.out.println(listItor.next());
}
System.out.println("---分割线---");
// 通过增强型for循环对ArrayList集合进行遍历
for(Person person : list) {
System.out.println(person);
}
// 通过jdk8特有的forEach方式遍历
System.out.println("---分割线---");
list.forEach(person -> {
System.out.println(person);// 正常打印
});
list.clear();// 清空集合
System.out.println(list);
}以上代码都是亲测无误的,其中涉及到几个点需要注意:
-#-.add()方法与addAll方法的区别就是add()方法一次性仅仅增加一个元素,而addAll()方法可以将一个集合B中的所有元素添加到集合A中,是一种批量操作方式。
-#-.可以通过remove(索引/对象)方法来删除指定集合中的元素。
-#-.可以通过set(索引, 对象)方法来修改指定集合中的指定位置的对象。
-#-.可以通过调用toArray(数组)方法来将ArrayList集合转换为数组(需要注意参数,传入一个匿名对应类型的初始数组即可)。
-#-.判断指定集合中是否有某一个对象的时候有两个方法(indexOf(obj)/contains(obj))。只不过indexOf返回的是对应的索引而contains返回的是布尔值。
-#-.isEmpty()方法用来判断指定集合是否为空。
-#-.clear()方法则是清空集合中的所有元素。
-#-.遍历ArrayList集合的3种方式:
-A.通过ListIterator迭代器。
-B.通过增强型for循环(for(T item : 集合){ ... })。
-C.通过jdk8新增的集合的forEach()方法。
## 上面的ArrayList基本使用我们就说完了,剩下的我们一起来剖析下ArrayList的源码(此部分是本人摘取出来的可核心部分,用来探究足够了↓↓↓)。
public class ArrayList<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, Serializable
{
// 杂记:transient的作用:当对象存储时,它的值不需要维持。换句话来说就是,用transient关键字标记的成员变量不参与序列化过程。
transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = new Object[0];
private int size;
public ArrayList()
{
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
private void ensureCapacityInternal(int paramInt)
{
if (this.elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
paramInt = Math.max(10, paramInt);
}
ensureExplicitCapacity(paramInt);
}
private void ensureExplicitCapacity(int paramInt)
{
this.modCount += 1;
if (paramInt - this.elementData.length > 0) {
grow(paramInt);
}
}
private void grow(int paramInt)
{
int i = this.elementData.length;
int j = i + (i >> 1);
if (j - paramInt < 0) {
j = paramInt;
}
if (j - 2147483639 > 0) {
j = hugeCapacity(paramInt);
}
this.elementData = Arrays.copyOf(this.elementData, j);
}
private static int hugeCapacity(int paramInt)
{
if (paramInt < 0) {
throw new OutOfMemoryError();
}
return paramInt > 2147483639 ? Integer.MAX_VALUE : 2147483639;
}
public boolean add(E paramE)// 调用add方法对ArrayList集合进行添加元素
{
ensureCapacityInternal(this.size + 1);
this.elementData[(this.size++)] = paramE;
return true;
}
}## 本次探究ArrayList分为两步走,第一步 (第一次使用ArrayList集合存值)、第二步(第二次使用ArrayList存值)。
第一步:我们在外边向ArrayList集合中添加元素肯定是会调用add方法,所以就以add方法作为突破口来探究ArrayList集合的运行机制。开始:当我们调用add方法的时候肯定传入了一个对象A,暂且先不管,ensureCapacityInternal(this.size + 1);通过这行代码我们去找到对应的方法,参数this.size + 1,size等于0(为什么等于0 => int的默认值),所以参数就是1。由于我们在外边是用的无参构造器所以数组elementData与数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA是一个东西,换句话说二者指向同一个对象即地址相同。所以当我们进入ensureCapacityInternal方法的时候上来就有个(this.elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)结果应该为true,经过Math.Max运算后paramInt就等于10。然后又调用ensureExplicitCapacity(paramInt)方法将paramInt参数传入,找到对应的方法:(paramInt - this.elementData.length > 0)翻译为((10-0) > 0)结果为true所以执行grow函数将paramInt参数传入经过运算i等于0,j等于10,经过运算(j - 2147483639 > 0)为false所以不执行里面的语句直接到了最后一句this.elementData = Arrays.copyOf(this.elementData, j);这个Arrays.copyOf(e, d);函数的意思就是复制指定长度的数组,1参为被复制数组2参为指定的长度。执行完这步elementData数组的地址就变了不再和DEFAULTCAPACITY_EMPTY_ELEMENTDATA数组的地址相等了,并且数组长度为10,这也就是平常我们听说的ArrayList集合底层是基于数组的初始状态下会分配10个长度的由来。然后回到add方法第二句代码this.elementData[(this.size++)] = paramE;elementData数组第0个元素被赋值为paramE(也就是传入进来的参数对象)。如此第一步完毕。
第二步:当我们再向ArrayList集合中存储元素呢?其实还是按照流程一步一步来只不过略有不同,开始:外部调用add方法并传入参数对象。由于执行了++操作所以这次向ensureCapacityInternal方法传入的参数为2 -> 找到对应的方法。又由于elementData数组的地址不等于DEFAULTCAPACITY_EMPTY_ELEMENTDATA数组的地址了,即this.elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA结果为false所以不执行里面语句,直接执行这句代码ensureExplicitCapacity(paramInt);即调用ensureExplicitCapacity方法并将参数2传入 -> 找到对应方法。(paramInt - this.elementData.length > 0)翻译为((2 - 1) > 0)所以继续执行grow方法并将参数2传入。经过计算i等于1,j等于2,继续执行 ... this.elementData = Arrays.copyOf(this.elementData, j);克隆数组elementData指定长度为2。正好与我们存入两个元素对应上了。话不多说回到我们的add方法的第二句代码this.elementData[(this.size++)] = paramE;elementData数组的第1个元素被赋值为paramE(即传进来的入参对象)。至于为啥this.size等于1那是因为在第一步的时候在所有代码执行完毕的时候还执行了最后一步就是++操作,所以此时会是1。
最后大家肯定有一点很疑惑,为啥参数对象都存elementData数组中了?其实给大家看张图片大家也许就明白了。
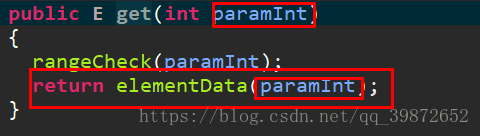
当我们往出取元素的时候也是根据传进来的入参索引在elementData数组中找到对应的元素进行返回的。所以最终我们要的所有信息都在这个elementData数组中。
## 通过这两步呢我们简单的探究了一下ArrayList集合的底层实现。如果源码看不懂也没关系只需要记住ArrayList底层是靠数组来实现的。
List(有序、可重复): -> Vector(底层依赖数组存储)
-1).特点:底层是基于数组的数据结构(后面我们会读源码)、查询快但增删慢、线程安全、效率低。
-2).使用方法:
// 创建Vector集合
private static List<Person> vector = new Vector<Person>();
public static void main(String[] args) {
Person person_1 = new Person("LJ", 21);
Person person_2 = new Person("XXY", 21);
vector.add(person_1);
vector.add(person_1);
vector.add(person_2);
// 通过迭代器对Vector集合进行遍历
ListIterator<Person> listor = vector.listIterator();
while (listor.hasNext()) {
System.out.println(listor.next());// 打印
/**
* Person [name=LJ, age=21]
* Person [name=LJ, age=21]
* Person [name=XXY, age=21]
*/
}
List<Person> list = new ArrayList<Person>();
list.add(new Person("小明", 23));
list.add(new Person("小红", 27));
vector.addAll(list);
System.out.println("---分割线---");
// 通过增强型for循环来进行遍历
for (Person person : vector) {
System.out.println(person);// 打印
/**
* Person [name=LJ, age=21]
* Person [name=LJ, age=21]
* Person [name=XXY, age=21]
* Person [name=小明, age=23]
* Person [name=小红, age=27]
*/
}
// 通过remove删除指定集合的指定元素
vector.remove(vector.size() - 1);
vector.remove(person_1);
System.out.println("---分割线---");
// 通过jdk8新增的forEach方法进行遍历
vector.forEach(person -> {
System.out.println(person);
});
// contains方法判断vector集合中是否有指定对象
System.out.println("vector集合中是否有person_2对象:" + vector.contains(person_2));
// 打印vector集合中是否有person_2对象:true
// isEmpty方法判断vector集合是否为空
System.out.println("vector集合是否为空:" + vector.isEmpty());
// 打印vector集合是否为空:false
Person[] arr = vector.toArray(new Person[]{});
System.out.println("数组长度:" + arr.length + ",第一个元素是:" + arr[0]);
// 打印数组长度:3,第一个元素是:Person [name=LJ, age=21]
vector.set(vector.size() - 1, new Person("小红", 25));
System.out.println("---分割线---");
vector.forEach(person -> {
System.out.println(person);// 打印
/**
* Person [name=LJ, age=21]
* Person [name=XXY, age=21]
* Person [name=小红, age=25]
*/
});
// submit方法截取指定长度数组返回一个新数组(左闭右开)
List<Person> vector_2 = vector.subList(0, 1);
System.out.println("---分割线---");
vector_2.forEach(person -> {
System.out.println(person);// 打印
// 打印Person [name=LJ, age=21]
});
int index = vector.indexOf(person_2);
System.out.println("实例person_2所在的位置为:" + index);// 打印实例person_2所在的位置为:1
// clear方法清空数组
vector.clear();
System.out.println("---分割线---");
vector.forEach(person -> {
System.out.println(person);// 打印
});
}以上代码都是亲测无误的,Vector集合与ArrayList集合极为相似,但是Vector集合内部大部分方法都采用了同步方法的模式,故Vector集合是线程安全的。
Vector集合的用法与ArrayList集合的用法基本相同,这里就不在赘述,如想直观感受直接参看上面代码块中内容即可。
## 上面的Vector基本使用我们就说完了,剩下的我们一起来剖析下Vector的源码(此部分是本人摘取出来的可核心部分,用来探究足够了↓↓↓)。
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, Serializable
{
protected int elementCount;
protected int capacityIncrement;
public Vector(int paramInt1, int paramInt2)
{
if (paramInt1 < 0) {
throw new IllegalArgumentException("Illegal Capacity: " + paramInt1);
}
this.elementData = new Object[paramInt1];
this.capacityIncrement = paramInt2;
}
public Vector(int paramInt)
{
this(paramInt, 0);
}
public Vector()
{
this(10);
}
private void ensureCapacityHelper(int paramInt)
{
if (paramInt - this.elementData.length > 0) {
grow(paramInt);
}
}
private void grow(int paramInt)
{
int i = this.elementData.length;
int j = i + (this.capacityIncrement > 0 ? this.capacityIncrement : i);
if (j - paramInt < 0) {
j = paramInt;
}
if (j - 2147483639 > 0) {
j = hugeCapacity(paramInt);
}
this.elementData = Arrays.copyOf(this.elementData, j);
}
public synchronized boolean add(E paramE)// 经过同步方法修饰的add方法就是线程安全的
{
this.modCount += 1;
ensureCapacityHelper(this.elementCount + 1);
this.elementData[(this.elementCount++)] = paramE;
return true;
}
}可以直观看到凡是直接暴露在外面的方法基本上都是用的是synchronized来修饰的,上面提到过这样会确保线程安全,另一方面肯定会伴随着效率下降(在这里add方法指向的this指向的实例就充当了唯一的锁)。
## 本次探究Vector分为两步走,第一步 (第一次使用Vector集合存值)、第二步(第十一次使用Vector集合存值)。
来,我们还以add方法作为突破口来了解一下Vector集合的机制。
第一步:
我们会先实例化Vector,所以会走无参构造器,
public Vector()
{
this(10);
}
但是该无参构造器又调用了另一个有1个参数的有参构造器并将10传入
public Vector(int paramInt)
{
this(paramInt, 0);
}
然后这个构造器又调用了另一个两个参数的构造器并将参数传入
public Vector(int paramInt1, int paramInt2)
{
if (paramInt1 < 0) {
throw new IllegalArgumentException("Illegal Capacity: " + paramInt1);
}
this.elementData = new Object[paramInt1];
this.capacityIncrement = paramInt2;
}
最后elementData数组被初始化为10个长度。变量capacityIncrement也被初始化为0。
接下在我们在外部调用add方法进行填充,进入add方法后首先会执行ensureCapacityHelper(this.elementCount + 1);意思就是向ensureCapacityHelper方法传入一个参数elementCount变量的数据类型为int所以默认值为0再加上1所以就是调用ensureCapacityHelper(1)方法并向这个方法传入参数1。找到这个方法,执行这句(paramInt - this.elementData.length > 0)翻译为((1 - 10) > 0)返回false,所以里面的代码不用执行,我们返回来回到add方法的第三句代码this.elementData[(this.elementCount++)] = paramE;为elementData数组的第1个元素赋值传入的参数对象。第一次add就此完毕。
第二步:
当第10次add元素的时候,一样在add方法执行ensureCapacityHelper(this.elementCount + 1);此时传入11,找到对应方法执行这句(paramInt - this.elementData.length > 0)翻译为((11 - 10) > 0)返回true,所以执行里面代码,调用grow方法并传入11。经过计算i等于10,j等于20,然后执行本方法最后一句this.elementData = Arrays.copyOf(this.elementData, j);复制一个长度为20的数组,再由elementData数组指向它。返回来回到add方法第三句this.elementData[(this.elementCount++)] = paramE;为elementData[10]elementData集合中第11个元素赋值传入的参数对象。此刻Vector底层运行机制我们就探究完了。简而言之当我们向Vector集合存储元素对象的时候会先去确定数组的长度,长度怎么确定?每到满10都会继续再拓展10个长度。然后再进行存值。
至于有人会问为什么总是涉及到elementData数组,答案和上面我们探究ArrayList集合时候回答的一样,因为elementData是最终与我们打交道的数组。
## 通过这两步呢我们简单的探究了一下Vector集合的底层实现。如果源码看不懂也没关系只需要记住Vector底层是靠数组来实现的。
List(有序、可重复): -> LinkedList(底层依赖链表存储)
-1).特点:底层是基于数组的数据结构(后面我们会读源码)、查询慢但增删快、线程不安全、效率高。
## 有人就要问了啥是链表?来看张图:
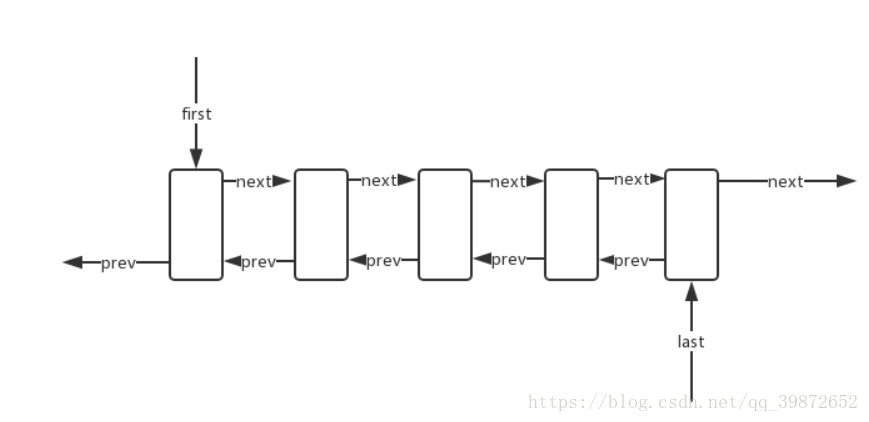
上图所示的结构就是链表(双向链表,可以当做栈、队列、双端队列),每次新增元素的时候都需要next指针指向下一个元素并且last指针会向后移位同时生成prev指针指向上一个元素。
-2).使用方法:
private static List<Person> linkedList = new LinkedList<Person>();
public static void main(String[] args) {
Person person_1 = new Person("LJ", 21);
Person person_2 = new Person("XXY", 22);
linkedList.add(0, person_1);
linkedList.add(1, person_1);
linkedList.add(2, person_2);
// 通过迭代器的方式遍历LinkedList集合
ListIterator<Person> listor = linkedList.listIterator();
while(listor.hasNext()) {
System.out.println(listor.next());// 打印
/*
* Person [name=XXY, age=22]
* Person [name=LJ, age=21]
* Person [name=LJ, age=21]
*/
}
List<Person> vector = new Vector<Person>();
vector.add(new Person("小明", 25));
vector.add(new Person("小红", 28));
linkedList.addAll(vector);
// 通过增强型for循环来遍历linkedList集合
System.out.println("---分割线---");
for(Person person : linkedList) {
System.out.println(person);// 打印
/**
* Person [name=XXY, age=22]
* Person [name=LJ, age=21]
* Person [name=LJ, age=21]
* Person [name=小明, age=25]
* Person [name=小红, age=28]
*/
}
// 通过remove方法来删除集合中的元素
linkedList.remove(0);
linkedList.remove(linkedList.size() - 1);
// 通过jdk8新增的forEach方法进行遍历
System.out.println("---分割线---");
linkedList.forEach(person -> {
System.out.println(person);
});
// isEmpty方法判断集合是否为空
System.out.println("linkedList集合是否为空:" + linkedList.isEmpty());
// 打印linkedList集合是否为空:false
// contains方法判断指定集合中有无指定元素对象返回一个布尔值
System.out.println("linkedList集合中是否有person_2对象:" + linkedList.contains(person_2));
// 打印linkedList集合中是否有person_2对象:true
//通过subList方法来截取集合(两个参数左闭右开)
List<Person> linkedList2 = linkedList.subList(0, 2);
System.out.println("---分割线---");
linkedList2.forEach(person -> {
System.out.println(person);// 打印
/**
* Person [name=LJ, age=21]
* Person [name=XXY, age=22]
*/
});
Person[] arr = linkedList.toArray(new Person[]{});
System.out.println("数组长度:" + arr.length + ",数组第一个元素:" + arr[0]);
// 打印数组长度:3,数组第一个元素:Person [name=LJ, age=21]
linkedList.set(linkedList.size() - 1, new Person("小军", 27));
System.out.println("---分割线---");
linkedList.forEach(person -> {
System.out.println(person);// 打印
/**
* Person [name=LJ, age=21]
* Person [name=XXY, age=22]
* Person [name=小军, age=27]
*/
});
// 通过indexOf方法查找元素位置返回元素所在位置的索引
System.out.println(linkedList.indexOf(person_2));// 打印1
// 通过clear方法清空集合
linkedList.clear();
System.out.println("---分割线---");
linkedList.forEach(person -> {
System.out.println(person);
});
}## 如图所示ArrayList、Vector、LinkedList使用方法都大致相同但底层实现是各有区别。
## 图中的LinkedList基本使用我们就说完了,剩下的我们一起来剖析下LinkedList的源码(此部分是本人摘取出来的可核心部分,用来探究足够了↓↓↓)。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, Serializable
{
transient Node<E> first;
transient Node<E> last;
// 无参构造器
public LinkedList() {}
void linkLast(E paramE)
{
Node localNode1 = this.last;
Node localNode2 = new Node(localNode1, paramE, null);
this.last = localNode2;
if (localNode1 == null) {
this.first = localNode2;
} else {
localNode1.next = localNode2;
}
this.size += 1;
this.modCount += 1;
}
public boolean add(E paramE)
{
linkLast(paramE);
return true;
}
}
LinkedList$Node类中的内部类Node
private static class Node<E>
{
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> paramNode1, E paramE, Node<E> paramNode2)
{
this.item = paramE;
this.next = paramNode2;
this.prev = paramNode1;
}
}