前言
在我们需要比较对象是否相等时,我们往往需要采取重写equals方法和hashcode方法。
该篇,就是从比较对象的场景结合通过代码实例以及部分源码解读,去跟大家品一品这个重写equals方法和hashcode方法。
正文
场景:
我们现在需要比较两个对象 Pig 是否相等 。
而Pig 对象里面包含 三个字段, name,age,nickName ,我们现在只需要认为如果两个pig对象的name名字和age年龄一样,那么这两个pig对象就是一样的,nickName昵称不影响相等的比较判断。
代码示例:
Pig.java:
/**
* @Author : JCccc
* @CreateTime : 2020/4/21
* @Description :
**/
public class Pig {
private String name;
private Integer age;
private String nickName;
public Pig() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
}可以看到上面的Pig对象,没有重写equals方法 和 hashcode 方法,那么我们去比较两个Pig对象,就算都设置了三个一样的属性字段,都是返回 false:
public static void main(String[] args) {
Pig pig1=new Pig();
pig1.setName("A");
pig1.setAge(11);
pig1.setNickName("a");
String name= new String("A");
Pig pig2=new Pig();
pig2.setName(name);
pig2.setAge(11);
pig2.setNickName("B");
System.out.println(pig1==pig2); //false
System.out.println(pig1.equals(pig2)); //false
System.out.println(pig1.hashCode() ==pig2.hashCode()); //false
}为什么false? 很简单,因为pig1和pig2都是新new出来的,内存地址都是不一样的。
== : 比较内存地址 ,那肯定是false了 ;
equals: 默认调用的是Object的equals方法,看下面源码图,显然还是使用了== ,那就还是比较内存地址,那肯定是false了;

hashCode: 这是根据一定规则例如对象的存储地址,属性值等等映射出来的一个散列值,不同的对象存在可能相等的hashcode,但是概率非常小(两个对象equals返回true时,hashCode返回肯定是true;而两个对象hashCode返回true时,这两个对象的equals不一定返回true; 还有,如果两个对象的hashCode不一样,那么这两个对象一定不相等!)。
一个好的散列算法,我们肯定是尽可能让不同对象的hashcode也不同,相同的对象hashcode也相同。这也是为什么我们比较对象重写equals方法后还会一起重写hashcode方法。接下来会有介绍到。
好的,上面啰嗦了很多,接下来我们开始去重写equals方法和hashCode方法,实现我们这个Pig对象的比较,只要能保证name和age两个字段属性一致,就返回相等true。
首先是重写equals方法(看上去我似乎写的很啰嗦吧,我觉得这样去写更容易帮助新手去理解):
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Pig pig = (Pig) o;
boolean nameCheck=false;
boolean ageCheck=false;
if (this.name == pig.name) {
nameCheck = true;
} else if (this.name != null && this.name.equals(pig.name)) {
nameCheck = true;
}
if (this.age == pig.age) {
ageCheck = true;
} else if (this.age != null && this.age.equals(pig.age)) {
ageCheck = true;
}
if (nameCheck && ageCheck){
return true;
}
return false;
}稍微对重写的代码做下解读,请看图:

事不宜迟,我们在重写了equals后,我们再比较下两个Pig对象:

可以看到,到这里好像已经能符合我们的比较对象逻辑了,但是我们还需要重写hashCode方法。
为什么?
原因1.
通用约定,

翻译:
/*请注意,通常需要重写{@code hashCode}
*方法,以便维护
*{@code hashCode}方法的常规约定,它声明
*相等的对象必须有相等的哈希码。
*/原因2.
为了我们使用hashmap存储对象 (下面有介绍)
没错,就是文章开头我们讲到的,相同的对象的hashCode 的散列值最好保持相等, 而不同对象的散列值,我们也使其保持不相等。
而目前我们已经重写了equals方法,可以看到,只要两个pig对象的name和age都相等,那么我们的pig的equals就返回true了,也就是说,此时此刻,我们也必须使两个pig的hashCode 的散列值保持相等,这样才是对象相等的结果。
事不宜迟,我们继续重写hashCode方法:
@Override
public int hashCode() {
int result = 17;
result = 31 * result + name.hashCode();
result = 31 * result + age;
return result;
}然后我们再比较下两个pig对象:

也就是说,最终我们重写了equals和hashCode方法后, Pig.java:
/**
* @Author : JCccc
* @CreateTime : 2020/4/21
* @Description :
**/
public class Pig {
private String name;
private Integer age;
private String nickName;
public Pig() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Pig pig = (Pig) o;
boolean nameCheck=false;
boolean ageCheck=false;
if (this.name == pig.name) {
nameCheck = true;
} else if (this.name != null && this.name.equals(pig.name)) {
nameCheck = true;
}
if (this.age == pig.age) {
ageCheck = true;
} else if (this.age != null && this.age.equals(pig.age)) {
ageCheck = true;
}
if (nameCheck && ageCheck){
return true;
}
return false;
}
@Override
public int hashCode() {
int result = 17;
result = 31 * result + name.hashCode();
result = 31 * result + age;
return result;
}
}
看到这里,应该有不少人觉得,重写怎么有点麻烦,有没有简单点的模板形式的?
有的,其实在java 7 有在Objects里面新增了我们需要重新的这两个方法,所以我们重写equals和hashCode还可以使用java自带的Objects,如:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Pig pig = (Pig) o;
return Objects.equals(name, pig.name) &&
Objects.equals(age, pig.age);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}那么如果还是觉得有点麻烦呢?
那就使用lombok的注解,让它帮我们写,我们自己就写个注解!
导入lombok依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>然后在Pig类上,使用注解:
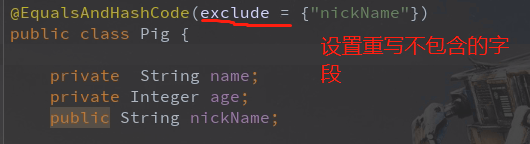
然后编译后,可以看到lombok帮我们重写了equals和hashcode方法:
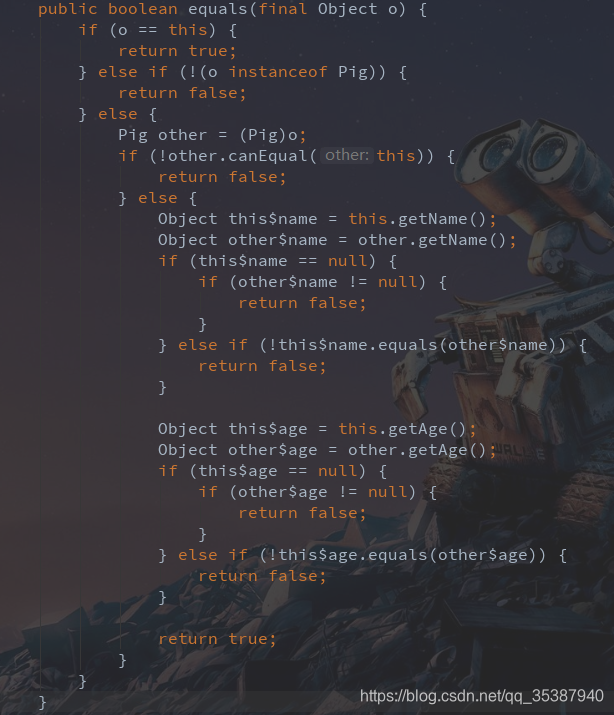
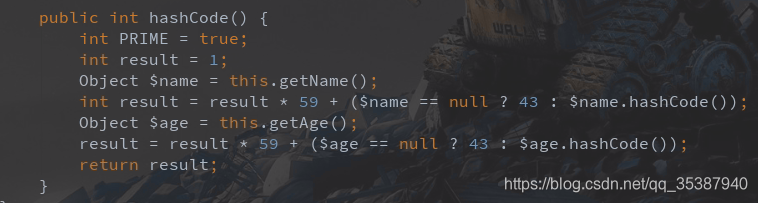
其实如果咱们使用到了lombok的话,用@Data注解应该基本就够用了,它结合了@ToString,@EqualsAndHashCode,@Getter和@Setter的功能。
ps:再啰嗦几句, 我们自己重写了hashCode方法后,能够确保两个对象返回的的hashCode散列值是不一样的,这样一来,
在我们使用hashmap 去存储对象, 在进行验重逻辑的时候,咱们的性能就特别好了。
为啥说这样性能好, 我们再啰嗦地补充一下hashmap在插入值时对key(这里key是对象)的验重:
HashMap中的比较key:
先求出key的hashcode(),比较其值是否相等;
-若相等再比较equals(),若相等则认为他们是相等 的。
-若equals()不相等则认为他们不相等。
如果只重写hashcode()不重写equals()方法,当比较equals()时只是看他们是否为 同一对象(即进行内存地址的比较),所以必定要两个方法一起重写。HashMap用来判断key是否相等的方法,其实是调用了HashSet判断加入元素 是否相等。
好的,该篇介绍就到此吧。
ps:其实没有结束,我还想啰嗦一下,因为我们在重写hashcode方法的时候,我们看到了一个数字 31 。 想必会有很多人奇怪,为什么要写个31啊?
这里引用一下《Effective Java》 里面的解释:
之所以使用 31, 是因为他是一个奇素数。
如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。
使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。
31 有个很好的性能,即用移位和减法来代替乘法,
可以得到更好的性能: 31 * i == (i << 5)- i,
现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。那么可能还有眼尖的人看到了,为什么还要个数字17?
这个其实道理一样,在《Effective Java》里,作者推荐使用的就是 基于17和31的散列码的算法 ,而在Objects里面的hash方法里,17换做了1 。
好吧,这篇就真的到此结束吧。