预警
在本篇文章中,将为各位老铁介绍不同的搜索算法以及它们的复杂度。因为力求通俗易懂,所以篇幅可能较长,大伙可以先Mark下来,每天抽时间看一点理解一点。本文配套的Github,欢迎各位老铁star,会一直更新的。
开篇
和排序类似,搜索或者叫做查找,也是平时我们使用最多的算法之一。无论我们搜索数据库还是文件,实际上都在使用某种搜索算法来定位想要查找的数据。
线性查找
执行搜索的最常见的方法是将每个项目与我们正在寻找的数据进行比较,这就是线性搜索或顺序搜索。它是执行搜索的最基本的方式。如果列表中有n项。在最坏的情况下。我们必须搜索n个项目才能找到一个特定的项目。下面遍历一个数组来查找一个项目。
function linearSearch(array $arr, int $needle) {
for ($i = 0, $count = count($arr); $i < $count; $i++) {
if ($needle === $arr[$i]) {
return true;
}
}
return false;
}
线性查找的复杂度
| best time complexity | O(1) |
|---|---|
| worst time complexity | O(n) |
| Average time complexity | O(n) |
| Space time complexity | O(1) |
二分搜索
线性搜索的平均时间复杂度或最坏时间复杂度是O(n),这不会随着待搜索数组的顺序改变而改变。所以如果数组中的项按特定顺序排序,我们不必进行线性搜索。我们可以通过执行选择性搜索而可以获得更好的结果。最流行也是最著名的搜索算法是“二分搜索”。虽然有点像二叉搜索树,但我们不用构造二叉搜索树就可以使用这个算法。
function binarySearch(array $arr, int $needle) {
$low = 0;
$high = count($arr) - 1;
while ($low <= $high) {
$middle = (int)(($high + $low) / 2);
if ($arr[$middle] < $needle) {
$low = $middle + 1;
} elseif ($arr[$middle] > $needle) {
$high = $middle - 1;
} else {
return true;
}
}
return false;
}
在二分搜索算法中,我们从数据的中间开始,检查中间的项是否比我们要寻找的项小或大,并决定走哪条路。这样,我们把列表分成两半,一半完全丢弃,像下面的图像一样。

递归版本:
function binarySearchRecursion(array $arr, int $needle, int $low, int $high)
{
if ($high < $low) return false;
$middle = (int)(($high + $low) / 2);
if ($arr[$middle] < $needle) {
return binarySearchRecursion($arr, $needle, $middle + 1, $high);
} elseif ($arr[$middle] > $needle) {
return binarySearchRecursion($arr, $needle, $low, $middle - 1);
} else {
return true;
}
}
二分搜索复杂度分析
对于每一次迭代,我们将数据划分为两半,丢弃一半,另一半用于搜索。在分别进行了1,2次和3次迭代之后,我们的列表长度逐渐减少到n/2,n/4,n/8…。因此,我们可以发现,k次迭代后,将只会留下n/2^k项。最后的结果就是 n/2^k = 1,然后我们两边分别取对数 得到 k = log(n),这就是二分搜索算法的最坏运行时间复杂度。
| best time complexity | O(1) |
|---|---|
| worst time complexity | O(log n) |
| Average time complexity | O(log n) |
| Space time complexity | O(1) |
重复二分查找
有这样一个场景,假如我们有一个含有重复数据的数组,如果我们想从数组中找到2的第一次出现的位置,使用之前的算法将会返回第5个元素。然而,从下面的图像中我们可以清楚地看到,正确的结果告诉我们它不是第5个元素,而是第2个元素。因此,上述二分搜索算法需要进行修改,将它修改成一个重复的搜索,搜索直到元素第一次出现的位置才停止。

function repetitiveBinarySearch(array $data, int $needle)
{
$low = 0;
$high = count($data);
$firstIndex = -1;
while ($low <= $high) {
$middle = ($low + $high) >> 1;
if ($data[$middle] === $needle) {
$firstIndex = $middle;
$high = $middle - 1;
} elseif ($data[$middle] > $needle) {
$high = $middle - 1;
} else {
$low = $middle + 1;
}
}
return $firstIndex;
}
首先我们检查mid所对应的值是否是我们正在寻找的值。 如果是,那么我们将中间索引指定为第一次出现的index,我们继续检查中间元素左侧的元素,看看有没有再次出现我们寻找的值。 然后继续迭代,直到low >low>high。 如果没有再次找到这个值,那么第一次出现的位置就是该项的第一个索引的值。 如果没有,像往常一样返回-1。我们运行一个测试来看代码是否正确:
public function testRepetitiveBinarySearch()
{
$arr = [1,1,1,2,3,4,5,5,5,5,5,6,7,8,9,10];
$firstIndex = repetitiveBinarySearch($arr, 6);
$this->assertEquals(11, $firstIndex);
}
发现结果正确。

到目前为止,我们可以得出结论,二分搜索肯定比线性搜索更快。但是,这一切的先决条件是数组已经排序。在未排序的数组中应用二分搜索会导致错误的结果。 那可能存在一种情况,就是对于某个数组,我们不确定它是否已排序。现在有一个问题就是,是否应该首先对数组进行排序然后应用二分查找算法吗?还是继续使用线性搜索算法?
小思考
对于一个包含n个项目的数组,并且它们没有排序。由于我们知道二分搜索更快,我们决定先对其进行排序,然后使用二分搜索。但是,我们清楚最好的排序算法,其最差的时间复杂度是O(nlogn),而对于二分搜索,最坏情况复杂度是O(logn)。所以,如果我们排序后应用二分搜索,复杂度将是O(nlogn)。
但是,我们也知道,对于任何线性或顺序搜索(排序或未排序),最差的时间复杂度是O(n),显然好于上述方案。
考虑另一种情况,即我们需要多次搜索给定数组。我们将k表示为我们想要搜索数组的次数。如果k为1,那么我们可以很容易地应用之前的线性搜索方法。如果k的值比数组的大小更小,暂且使用n表示数组的大小。如果k的值更接近或大于n,那么我们在应用线性方法时会遇到一些问题。假设k = n,线性搜索将具有O(n2)的复杂度。现在,如果我们进行排序然后再进行搜索,那么即使k更大,一次排序也只会花费O(nlogn)时间复。然后,每次搜索的复杂度是O(logn),n次搜索的复杂度是O(nlogn)。如果我们在这里采取最坏的运行情况,排序后然后搜索k次总的的复杂度是O(nlogn),显然这比顺序搜索更好。
我们可以得出结论,如果一些搜索操作的次数比数组的长度小,最好不要对数组进行排序,直接执行顺序搜索即可。但是,如果搜索操作的次数与数组的大小相比更大,那么最好先对数组进行排序,然后使用二分搜索。
二分搜索算法有很多不同的版本。我们不是每次都选择中间索引,我们可以通过计算作出决策来选择接下来要使用的索引。我们现在来看二分搜索算法的两种变形:插值搜索和指数搜索。
插值搜索
在二分搜索算法中,总是从数组的中间开始搜索过程。 如果一个数组是均匀分布的,并且我们正在寻找的数据可能接近数组的末尾,那么从中间搜索可能不是一个好选择。 在这种情况下,插值搜索可能非常有用。插值搜索是对二分搜索算法的改进,插值搜索可以基于搜索的值选择到达不同的位置。例如,如果我们正在搜索靠近数组开头的值,它将直接定位到到数组的第一部分而不是中间。使用公式计算位置,如下所示
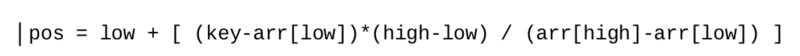
可以发现,我们将从通用的mid =(low * high)/2 转变为更复杂的等式。如果搜索的值更接近arr[high],则此公式将返回更高的索引,如果值更接近arr[low],则此公式将返回更低的索引。
function interpolationSearch(array $arr, int $needle)
{
$low = 0;
$high = count($arr) - 1;
while ($arr[$low] != $arr[$high] && $needle >= $arr[$low] && $needle <= $arr[$high]) {
$middle = intval($low + ($needle - $arr[$low]) * ($high - $low) / ($arr[$high] - $arr[$low]));
if ($arr[$middle] < $needle) {
$low = $middle + 1;
} elseif ($arr[$middle] > $needle) {
$high = $middle - 1;
} else {
return $middle;
}
}
if ($needle == $arr[$low]) {
return $low;
}
return -1;
}
插值搜索需要更多的计算步骤,但是如果数据是均匀分布的,这个算法的平均复杂度是O(log(log n)),这比二分搜索的复杂度O(logn)要好得多。 此外,如果值的分布不均匀,我们必须要小心。 在这种情况下,插值搜索的性能可以需要重新评估。下面我们将探索另一种称为指数搜索的二分搜索变体。
指数搜索
在二分搜索中,我们在整个列表中搜索给定的数据。指数搜索通过决定搜索的下界和上界来改进二分搜索,这样我们就不会搜索整个列表。它减少了我们在搜索过程中比较元素的数量。指数搜索是在以下两个步骤中完成的:
- 我们通过查找第一个指数k来确定边界大小,其中值2^k的值大于搜索项。 现在,2k和2(k-1)分别成为上限和下限。
- 使用以上的边界来进行二分搜索。
下面我们来看下PHP实现的代码
function exponentialSearch(array $arr, int $needle): int
{
$length = count($arr);
if ($length == 0) return -1;
$bound = 1;
while ($bound < $length && $arr[$bound] < $needle) {
$bound *= 2;
}
return binarySearchRecursion($arr, $needle, $bound >> 1, min($bound, $length));
}
我们把$needle出现的位置记位i,那么我们第一步花费的时间复杂度就是O(logi)。表示为了找到上边界,我们的while循环需要执行O(logi)次。因为下一步应用一个二分搜索,时间复杂度也是O(logi)。我们假设j是我们上一个while循环执行的次数,那么本次二分搜索我们需要搜索的范围就是2^j-1 至 2^j,而j=logi,即
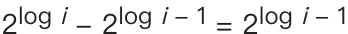
那我们的二分搜索时间复杂度需要对这个范围求log2,即

那么整个指数搜索的时间复杂度就是2 O(logi),省略掉常数就是O(logi)。
| best time complexity | O(1) |
|---|---|
| worst time complexity | O(log i) |
| Average time complexity | O(log i) |
| Space time complexity | O(1) |
哈希查找
在搜索操作方面,哈希表可以是非常有效的数据结构。在哈希表中,每个数据都有一个与之关联的唯一索引。如果我们知道要查看哪个索引,我们就可以非常轻松地找到对应的值。通常,在其他编程语言中,我们必须使用单独的哈希函数来计算存储值的哈希索引。散列函数旨在为同一个值生成相同的索引,并避免冲突。
PHP底层C实现中数组本身就是一个哈希表,由于数组是动态的,不必担心数组溢出。我们可以将值存储在关联数组中,以便我们可以将值与键相关联。
function hashSearch(array $arr, int $needle)
{
return isset($arr[$needle]) ? true : false;
}
树搜索
搜索分层数据的最佳方案之一是创建搜索树。在第理解和实现树中,我们了解了如何构建二叉搜索树并提高搜索效率,并且介绍了遍历树的不同方法。 现在,继续介绍两种最常用的搜索树的方法,通常称为广度优先搜索(BFS)和深度优先搜索(DFS)。
广度优先搜索(BFS)
在树结构中,根连接到其子节点,每个子节点还可以继续表示为树。 在广度优先搜索中,我们从节点(主要是根节点)开始,并且在访问其他邻居节点之前首先访问所有相邻节点。 换句话说,我们在使用BFS时必须逐级移动。
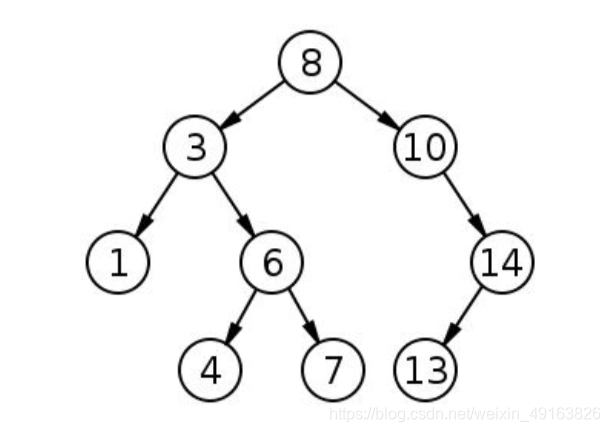
使用BFS,会得到以下的序列。
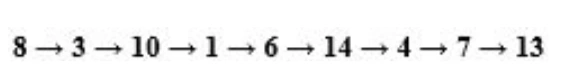
伪代码如下:
procedure BFS(Node root)
Q := empty queue
Q.enqueue(root)
while(Q != empty)
u := Q.dequeue()
for each node w that is childnode of u
Q.enqueue(w)
end for each
end while
end procedure
下面是PHP代码。
class TreeNode
{
public $data = null;
public $children = [];
public function __construct(string $data = null)
{
$this->data = $data;
}
public function addChildren(TreeNode $treeNode)
{
$this->children[] = $treeNode;
}
}
class Tree
{
public $root = null;
public function __construct(TreeNode $treeNode)
{
$this->root = $treeNode;
}
public function BFS(TreeNode $node): SplQueue
{
$queue = new SplQueue();
$visited = new SplQueue();
$queue->enqueue($node);
while (!$queue->isEmpty()) {
$current = $queue->dequeue();
$visited->enqueue($current);
foreach ($current->children as $children) {
$queue->enqueue($children);
}
}
return $visited;
}
}
如果想要查找节点是否存在,可以为当前节点值添加简单的条件判断即可。BFS最差的时间复杂度是O(|V| + |E|),其中V是顶点或节点的数量,E则是边或者节点之间的连接数,最坏的情况空间复杂度是O(|V|)。
图的BFS和上面的类似,但略有不同。 由于图是可以循环的(可以创建循环),需要确保我们不会重复访问同一节点以创建无限循环。 为了避免重新访问图节点,必须跟踪已经访问过的节点。可以使用队列,也可以使用图着色算法来解决。
深度优先搜索(DFS)
深度优先搜索(DFS)指的是从一个节点开始搜索,并从目标节点通过分支尽可能深地到达节点。 DFS与BFS不同,简单来说,就是DFS是深入挖掘而不是先扩散。DFS在到达分支末尾时然后向上回溯,并移动到下一个可用的相邻节点,直到搜索结束。还是上面的树
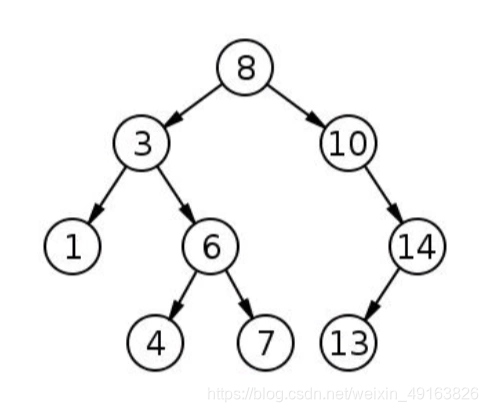
这次我们会获得不通的遍历顺序:

从根开始,然后访问第一个孩子,即3。然后,到达3的子节点,并反复执行此操作,直到我们到达分支的底部。在DFS中,我们将采用递归方法来实现。
procedure DFS(Node current)
for each node v that is childnode of current
DFS(v)
end for each
end procedure
public function DFS(TreeNode $node): SplQueue
{
$this->visited->enqueue($node);
if ($node->children) {
foreach ($node->children as $child) {
$this->DFS($child);
}
}
return $this->visited;
}
如果需要使用迭代实现,必须记住使用栈而不是队列来跟踪要访问的下一个节点。下面使用迭代方法的实现
public function DFS(TreeNode $node): SplQueue
{
$stack = new SplStack();
$visited = new SplQueue();
$stack->push($node);
while (!$stack->isEmpty()) {
$current = $stack->pop();
$visited->enqueue($current);
foreach ($current->children as $child) {
$stack->push($child);
}
}
return $visited;
}
这看起来与BFS算法非常相似。主要区别在于使用栈而不是队列来存储被访问节点。它会对结果产生影响。上面的代码将输出8 10 14 13 3 6 7 4 1。这与我们使用迭代的算法输出不同,但其实这个结果没有毛病。
因为使用栈来存储特定节点的子节点。对于值为8的根节点,第一个值是3的子节点首先入栈,然后,10入栈。由于10后来入栈,它遵循LIFO。所以,如果我们使用栈实现DFS,则输出总是从最后一个分支开始到第一个分支。可以在DFS代码中进行一些小调整来达到想要的效果。
public function DFS(TreeNode $node): SplQueue
{
$stack = new SplStack();
$visited = new SplQueue();
$stack->push($node);
while (!$stack->isEmpty()) {
$current = $stack->pop();
$visited->enqueue($current);
$current->children = array_reverse($current->children);
foreach ($current->children as $child) {
$stack->push($child);
}
}
return $visited;
}
由于栈遵循Last-in,First-out(LIFO),通过反转,可以确保先访问第一个节点,因为颠倒了顺序,栈实际上就作为队列在工作。要是我们搜索的是二叉树,就不需要任何反转,因为我们可以选择先将右孩子入栈,然后左子节点首先出栈。
DFS的时间复杂度类似于BFS。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。之前说过,PHP方面的技术点很多,也是因为太多了,实在是写不过来,写过来了大家也不会看的太多,所以我这里把它整理成了PDF和文档,如果有需要的可以


更多学习内容可以访问【对标大厂】精品PHP架构师教程目录大全,只要你能看完保证薪资上升一个台阶(持续更新)
以上内容希望帮助到大家,很多PHPer在进阶的时候总会遇到一些问题和瓶颈,业务代码写多了没有方向感,不知道该从那里入手去提升,对此我整理了一些资料,包括但不限于:分布式架构、高可扩展、高性能、高并发、服务器性能调优、TP6,laravel,YII2,Redis,Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等多个知识点高级进阶干货需要的可以免费分享给大家,需要的可以加入我的PHP技术交流群953224940