0 简介
0 什么是大数据
在互联网中产生的海量数据 ,需要存储, 需要分析运算 --> 实际经济价值
大数据的领域: 各行各业
海量数据的存储
海量数据的运算
资源调度
1 HADOOP 是什么
海量数据无法存储? HDFS
海量数据的运算 ? MapReduce
集群的资源调用 ? Yarn
2 HADOOP应用
HDFS 海量存储数据的一套标准
MapReduce 第一代运算框架[思想]-->第二代 spark 第三代 flink
Yarn资源调度的一个标准 [运算]
3 大数据领域特点
1 数据量大
2 数据类型多
3 处理速度,正确
4 安全
5 横向扩展 (存储 , 运算资源)

4 HADOOP的内容
1 HDFS
2 MapReduce
3 yarn
a. 大数据处理海量数据
b. 存储 和 运算
c. 应用广泛
d. hadoop 1) HDFS 2) MapReduce 3) yarn
e. 特点
2 HDFS
2.1 基础功能
是分布式文件系统 (hadoop distribute file system)
用来存储海量数据的: 应该保证存储的安全,扩展,提供读取功能 ,上传

用于一次存储多次读取,管理数据文件
1 .数据存储在集群中的位置 [单独的一个机器记录数据存储的位置]
2 集群中某个节点宕机以后,数据无法读取[数据丢失] : 数据存储副本(3个副本在不同的机器上)
3 集群中副本的个数不够默认的(3个) ,进行副本复制 ,如果复制的文件块过大 容易复制失败
4 在HDFS中存储的数据块不易太大, 选择128M一个数据块 存储在物理磁盘上
5 系统为客户提供一个虚拟的访问目录(方便用户上传,下载)
2.2 HDFS的系统架构

在HDFS中采用的是主从结构
主节点 :namenode
从节点 datanode
2.2.1 namenode
- 记录用户存储数据的元信息
- 接收客户端的请求
- 接收datanode的注册和汇报(存储信息)
2.2.2 datanode
- 启动注册汇报
- 接收客户端真正的读写操作
2.3 安装
| linux01 | linux02 | linux03 |
| namenode | secondary namenode | |
| datanode | datanode | datanode |
2.3.1 上传
统一将安装包上传到/opt/apps下
1) rz
2) 上传软件
3)alt+p
2.3.2 解压
将压缩安装包解压到当前目录
tar -zxvf hadoop-3.1.1.tar.gz
v显示解压进度
tar -zxf hadoop-3.1.1.tar.gz 不显示进度 速度快些

目录结构

2.3.3 配置
[root@linux01 hadoop]# pwd
/opt/apps/hadoop-3.1.1/etc/hadoop
- vi hadoop-env.sh
export JAVA_HOME=/opt/apps/jdk1.8.0_141
2 vi hdfs-site.xml
<configuration>
<!-- 集群的namenode的位置 datanode能通过这个地址注册-->
<property>
<name>dfs.namenode.rpc-address</name>
<value>linux01:8020</value>
</property>
<!-- namenode存储元数据的位置 -->
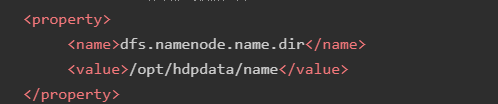
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hdpdata/name</value>
</property>
<!-- datanode存储数据的位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hdpdata/data</value>
</property>
<!-- secondary namenode机器的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux02:50090</value>
</property>
</configuration>2.3.4 分发到集群的每台机器
scp -r hadoop-3.1.1 linux02:$PWD
scp -r hadoop-3.1.1 linux03:$PWD

2.3.5 初始化
bin/hadoop namenode -format

2.3.6 单节点启动
1) 启动namenode
bin/hadoop-daemon.sh start namenode 启动namenode
jps
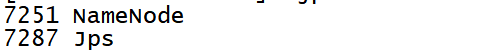
访问web页面http://linux01:9870/

2) 启动datanode
在
linux01
linux02
linux03
上启动datanode
/opt/apps/hadoop-3.1.1/sbin/hadoop-daemon.sh start datanode
在页面上可以看到




2.3.7 配置系统环境变量
vi /etc/profile
export JAVA_HOME=/opt/apps/jdk1.8.0_141
export TOMCAT_HOME=/opt/apps/apache-tomcat-7.0.47
export HADOOP_HOME=/opt/apps/hadoop-3.1.1
export PATH=$PATH:$JAVA_HOME/bin:$TOMCAT_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile2.3.8 一键启动
1 ) 在配置文件的目录中修改workers配置文件 (启动的时候会读取这个文件 ,在配置的主机上分别启动datanode)
vi workers
linux01
linux02
linux03
2) 在启动和停止的脚本中添加如下配置
vi sbin/start-dfs.sh | vi stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3 一键启动|停止
start-dfs.sh
读取workers 获取启动DN的主机
读取hdfs-site.xml文件 在哪个机器上启动namenode和secondarynamenode

3 HDFS客户端操作
3.1 shell客户端
bin> hdfs dfs 打开操作HDFS分布式文件系统的控制台
- hdfs dfs -put 本地文件 hdfs://linux01:8020/
- hdfs dfs -get hdfs://linux01:8020/demo.txt /
hdfs dfs
[root@linux01 bin]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...] 查看文本内容
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] 修改权限
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>] put
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] get
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]] df 系统容量 (分布式系统的存储总空间)
[-du [-s] [-h] [-v] [-x] <path> ...] 查看文件大小
[-expunge]
[-find <path> ... <expression> ...] 搜索
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 下载
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]] 列出目录下的内容
[-mkdir [-p] <path> ...] 创建文件夹
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>] 移动 重命名
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] 上传
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] 删除
[-rmdir [--ignore-fail-on-non-empty] <dir> ...] 删除文件夹
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>] 尾部查看内容
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
hdfs dfs -ls hdfs://linux01:8020/
hdfs dfs -ls / 显示的是本地的文件系统内容 说明 hdfs dfs -ls / 默认操作的本地系统
修改 etc/hadoop/core-site.xml 让默认操作的文件 系统是HDFS分布式文件系统
vi etc/hadoop/core-site.xml


<property>
<name>fs.defaultFS</name>
<value>hdfs://linux01:8020</value>
</property>
- hdfs dfs -ls /
- hdfs dfs -mkdir -p /aa/bb/cc
- hdfs dfs -put 本地文件 /aa/
- hdfs dfs -get /aa/a.txt /doit18/
- hdfs dfs -rm -r /aa/*
- hdfs dfs -chmod -R 777 /aa/
- hdfs dfs -df -h
- hdfs dfs -du -hs /
3.2 java客户端
3.3 HDFS存储数据特点
1 一个大于128M的文件在HDFS 中的确是分块存储在指定的目录中[]数据物理切块存储
/opt/hdpdata/data/current/BP-436644294-192.168.133.3-1600488030052/current/finalized/subdir0/subdir0
2 默认的切块大小128M
3 数据的物理切块 在集群中默认存储3个副本