Bigdata:
结构化数据:约束如mysql
半结构化数据:如json格式
非结构化数据:没有任何额外的去描述这段数据的元数据;如日志
收集数据方式:蜘蛛程序(爬虫),收集的都是非结构化或半结构化数据因此不能存储在rdbms中,并且这些收集到海量数据不是ELK能处理检索的,有以下瓶颈:
存储:
分析处理:
Google论文:阐述解决方式
2003年:The Google File System #元数据在内存中有主节点的分部署存储框架,不适合进行随机读写
2004年:MapReduce: Simplified Data Processing On Large Cluster #每个GFS上安装一个MapReduce分布式分析处理数据框架
2006年:BigTable:A Distributed Storage System for Structure Data #用于存储结构化数据的分布式存储系统,类似于键值对的格式
Hadoop:这三篇实现的山寨版~:
HDFS + MapReduce = Hadoop
HDFS:有主节点(NN)和冗余功能的分布式数据存储,元数据共享存放zookeeper中,主节点NN配置为高可用并从zookeeper中获取元数据
NN:主节点
SNN:辅助主节点,用来实现高可用,一旦NN故障可以快速启用SNN提高修复速度
DN:子节点,有副本的冗余机制
zookeeper:Hadoop之外的高可用的分布式数据管理与系统协调框架,HDFS的元数据共享存放zookeeper中共享给NN和SNN来作为冗余
MapReduce:是一个API、一个分布式运行框架、是一个运行环境
JobTracker:负责集群资源管理、作业管理
TaskTracker:子节点,负责运行作业
每一个HDFS的DN节点也都是MapReduce的一个TaskTracker运行节点所以每一个节点即是存储数据节点又是运行数据节点
HBase:HBase是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用HDFS作为其底层数据存储。HBase是针对谷歌BigTable的开源实现,二者都采用了相同的数据模型,具有强大的非结构化数据存储能力。HBase与传统关系数据库的一个重要区别是,前者釆用基于列的存储,而后者采用基于行的存储。HBase具有良好的横向扩展能力,可以通过不断增加廉价的商用服务器来增加存储能力。
MapReduce:函数式编程:
Lisp, ML函数式编程语言;高阶函数;
map, fold
map:做映射,一个任务映射为多个,接受一个函数为参数,并将其应用于列表中的所有元素;从而生成一个结果列表;
fold:做折叠,接受两个参数:函数,初始值,并把域第一个的参数运行结果应用在第二个参数上
hadoop1运行机制:
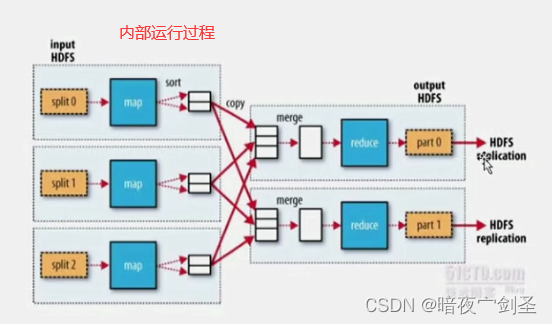
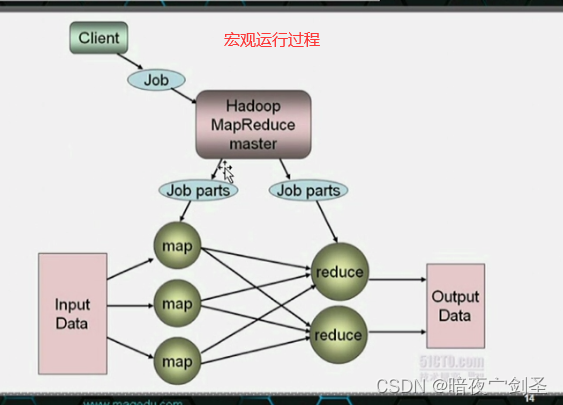
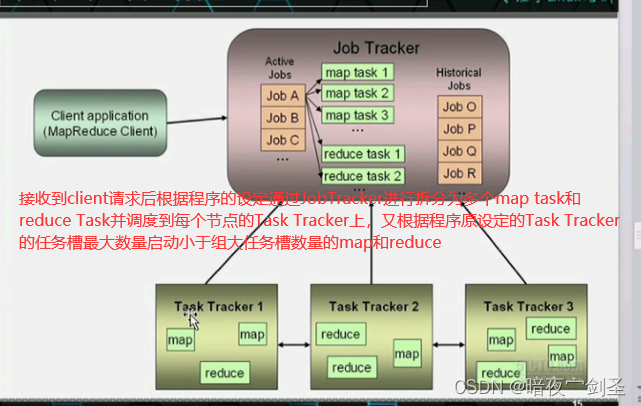
MapReduce是批处理方式:效率缓慢需要等待所有映射节点同步完成才能反馈结果,木桶效应取决于效率最低服务器
mapreduce:传输排序
mapper:负责拆分数据并转换成键值数据,并可用根据程序员开发的程序本地把相同的键值对通过映射进行统计排序,并把相同数据发往同一个reducer
reducer:收集自己节点发来的数据通过折叠统计数据并输出最终结果存放到HDFS
所以Hadoop需要运行起来需要一个java程序员根据自己的业务需求调用MapReduceAPI开发一个运行在MapReduce环境上的程序,实现map分词、合并、发送等功能和reducer的折叠功能
hadoop2运行机制:
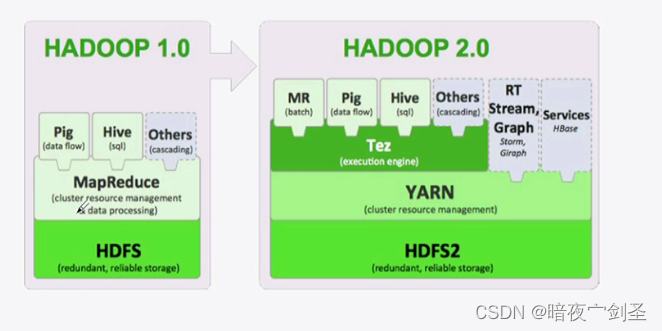
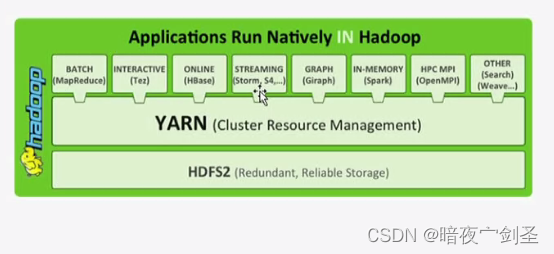
hadoop2:在hadoop1中,MapReduce的主节点Job Tracker负责分发作业、监控节点状态并修复,所以job Tracker在一个很繁忙的系统上很容易成为性能瓶颈,所以在hadoop2中把job Tracker的这些功能分割成了多个程序,而被切割出来的功能可以被当作公共库或公共功能框架进而被各种程序所使用
Yarn:分布式资源管理系统,用于统一管理调度集群中的资源(内存等)
Tez:执行引擎,提供在hadoop1中运行时环境的组件。Tez是支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG 作业的性能,在hadoop2后从MR中拆分出来;Tez源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。目前hive支持mr、tez计算模型,tez能完美二进制mr程序,提升运算性能。
DAG(AM):通常所说的 DAG 组件,指的是每个分布式作业的中心管理点,负责协调分布式作业的执行。而现代的分布式系统中的作业执行流程,通常可以通过 DAG 上面的调度以及数据流来描述。相对于传统的 Map-Reduce执行模式, DAG 的模型能对分布式作业做更精准的描述,也是当今各种主流大数据系统 (Hadoop 2.0+, SPARK, FLINK, TENSORFLOW 等) 的设计架构基础,区别只在于 DAG 的语义是透露给终端用户,还是计算引擎开发者。
依赖于Tez的功能框架:
MR:用来实现批量处作业,可以依赖于Tez或者YARN来完成处理
Pig:是一种数据流语言和运行环境, 一个执行 MapReduce 编码的更高层次的脚本编程环境接口。它在MapReduce的基础上创建了更简单的过程语言抽象,为Hadoop应用程序提供了一种更加接近结构化査询语言的接口,用于分析较大数据集,并将其表示为数据流,在hadoop2上不在依赖于MR而依赖于Tez
Hive:是—个基于Hadoop的数据仓库工具,可以用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储。Hive的学习门槛比较低,因为它提供了类似于关系数据库SQL语言的查询语言——HiveQL,可以通过HiveQL语句快速实现简单的MapReduce统计,Hive自身可以将HiveQL语句转换为MapReduce任务进行运行;Hive进行数据离线批量处理时,需将查询语言先转换成MR任务,由MR批量处理返回结果,所以Hive没法满足数据实时查询分析的需求。
Hive和Pig类似于两种变成语言,以后可根据工作需要进行学习这两种语言
依赖于Yarn的功能框架:
Tez
Batch:批处理
RT:stream graph:实时流式图形处理,图状算法数据结构
Spark:内存DAG计算模型,Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍
HPC MPI:高性能计算
HBase:
Oozie:工作流调度器,Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。可以通过Oozie提供的接口进行编排
RConnectors:R编程语言,可以用来实现数据的统计分析
Mahout:数据挖掘算法库,Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序,从而应用于人工智能。
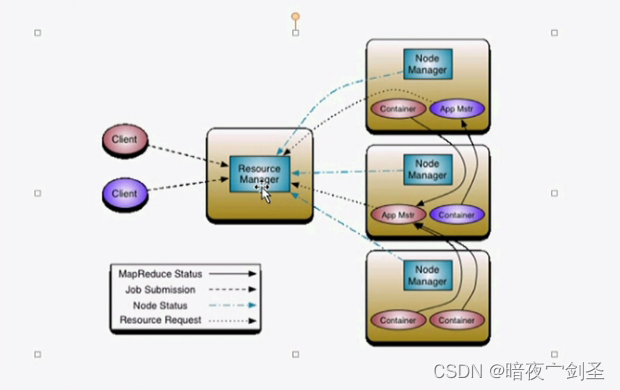
如上图所释:
Node Manager:负责管理监控自己所在节点并定时向Resource Manager推送自己的状态信息
Container:hadoop1中的Map和Reduce在hadoop2中一律被称为Container
App Mstr:Container的管理临时程序
执行过程:当Client提交任务后,Resource Manager会先查询空闲节点,然后在空闲节点创建一个App Mstr(App Mstr也是运行在container中的)。之后App Mstr来控制此任务需创建几个Container,然后向Resource Manager申请,Resource Manager会把要申请的若干container分配好后并通知App Mstr。于是App Mstr会使用这些container进行作业,而在此过程中App Mstr会不断向Resource Manager汇报进度,等结束后Resource Manager会把App Mstr给关掉
Hbase:
HDFS2:因为存储是流式数据,所以目前仅支持创建、删除、追加操作,不能实现随机读写所以就出现了Hbase
Hbase:
一个列示存储的NoSql的数据库,以每列为一个单位,所以可以访问每一列而要访问一行需要便利整个数据。与之对应的是SQL中的行式存储。
列族:由于可能要访问少量的几个列的行数据所以可以把若干列创建为一个,在访问行时只便利列族中的少数几列
cell:Hbase中列跟行交叉处的的一个单元并以键值对数据进行存储,此单元可以存储多个版本,可以取出此单元的最新数据也可以还原到之前的数据
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
HBASE是工作在HDFS之上,转化为chunk的。需要用到大数据块时,读取到HBase中,进行读取和修改,然后覆盖或者写入HDFS从而实现随机读写。
HBase基于分布式实现:需要另起一套集群,只不过此集群是运行在HDFS之上罢了,所以在HDFS集群之上要部署mapreduce集群,然后在部署HBase集群。
HBase严重依赖于ZooKeeper解决HBase分区脑裂问题
HBase因为建立在HDFS之,HDFS本身就有副本冗余机制
以用Hadoop作为静态数据仓库,HBase作为数据存储,放那些进行一些操作会改变的数据
HBase有自己的增删查改的接口语言需要单独学习
Sqoop:工作在hadoop之外的批量数据同步工具,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。也有一套自己的增删改查接口
Flume:
单独的、hadoop之外的日志收集工具,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将个节点产生的数据收集、传输、处理并最终写入目标的路径的过程抽象为数据流。
数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
在Hadoop集群中最终以流式的方式导入到HDFS中
Ambari: 是apache hadoop生态圈的全生命周期管理工具,安装部署配置管理工具。就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具。
注意:Hadoop尽量不要运行在虚拟机上,因为对IO影响比较大
Hadoop分发版(社区版/第三方发行版):
Cloudera: CDH
Hortonworks: HDP
Intel:IDH
MapR