什么是布隆过滤器
使用布隆过滤器可以实现去重。
优点: 占用的内存要比使用HashSet要小的多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会判定重复,但是重复数据一定会判定重复。
布隆过滤器 (Bloom Filter)是由Burton Howard Bloom于1970年提出,它是一种space efficient的概率型数据结构,用于判断一个元素是否在集合中。在垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。
哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的1/8或1/4的空间复杂度就能完成同样的问题。
布隆过滤器可以插入元素,但不可以删除已有元素。其中的元素越多,误报率越大,但是漏报是不可能的。
因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
原理
核心思想:当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
详细说明:

布隆过滤器需要的是一个位数组(和位图类似)和K个映射函数(和Hash表类似),在初始状态时,对于长度为m的位数组array,它的所有位被置0。

对于有n个元素的集合S={S1,S2…Sn},通过k个映射函数{f1,f2,…fk},将集合S中的每个元素Sj(1<=j<=n)映射为K个值{g1,g2…gk},然后再将位数组array中相对应的array[g1],array[g2]…array[gk]置为1:
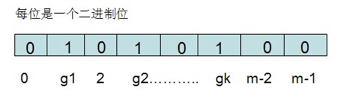
如果要查找某个元素item是否在S中,则通过映射函数{f1,f2,…fk}得到k个值{g1,g2…gk},然后再判断array[g1],array[g2]…array[gk]是否都为1,若全为1,则item在S中,否则item不在S中。
布隆过滤器会造成一定的误判,因为集合中的若干个元素通过映射之后得到的数值恰巧包括g1,g2,…gk,在这种情况下可能会造成误判,但是概率很小。