文章目录
参考:
吴恩达视频课
深度学习笔记
1. 什么是人脸识别
门禁闸机:人脸识别+活体检测
人脸验证(face verification)
- 输入图片,ID / 人名
- 输出图片是否是这个人(1对1问题)
人脸识别(face recognition)(1对多问题,比人脸认证更难)
- 有 K 个人的数据库
- 输入图片
- 输出这个人的 ID 或者 未识别(不在数据库中)
2. One-Shot学习
人脸识别面临的挑战:要解决一次学习问题,通过单单 一张图片/人脸 就能去识别这个人
- 然而小的训练集不足以去训练一个稳健的神经网络
- 新人员的加入,你要重新训练吗?不是好的想法
办法: 学习 Similarity 函数,看差异是否小于某个超参数阈值

当加入了新的人,只需要将这个人与系统里的每个人,用 d 函数进行对比
3. Siamese 网络
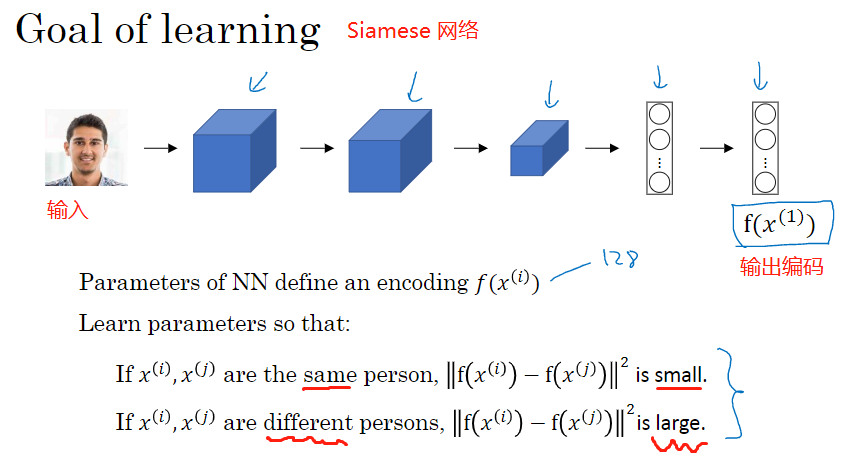
考查编码之差的范数
d ( x ( 1 ) , x ( 2 ) ) = ∥ f ( x ( 1 ) ) − f ( x ( 2 ) ) ∥ 2 2 d\left(x^{(1)}, x^{(2)}\right)=\left\|f\left(x^{(1)}\right)-f\left(x^{(2)}\right)\right\|_{2}^{2} d(x(1),x(2))=∥∥∥f(x(1))−f(x(2))∥∥∥22
对于两个不同的输入,运行相同的卷积神经网络,然后比较它们,这一般叫做Siamese网络架构
改变这个网络所有层的参数,得到不同的编码结果,用反向传播来改变这些所有的参数,以确保满足条件(相同的人,d 小,不同的人,d 大)
4. Triplet 损失
定义三元组损失函数然后应用梯度下降,来学习优质的神经网络参数

我们希望: ∥ f ( A ) − f ( P ) ∥ 2 ≤ ∥ f ( A ) − f ( N ) ∥ 2 \|f(A)-f(P)\|^{2} \leq\|f(A)-f(N)\|^{2} ∥f(A)−f(P)∥2≤∥f(A)−f(N)∥2
为了防止网络把所有的输入都学成固定的输出(也满足上式),加入一个超参数 a a a(间隔 margin)
∥ f ( A ) − f ( P ) ∥ 2 − ∥ f ( A ) − f ( N ) ∥ 2 + a ≤ 0 \|f(A)-f(P)\|^{2}-\|f(A)-f(N)\|^{2}+a \leq 0 ∥f(A)−f(P)∥2−∥f(A)−f(N)∥2+a≤0
定义损失函数为:
L ( A , P , N ) = max ( ∥ f ( A ) − f ( P ) ∥ 2 − ∥ f ( A ) − f ( N ) ∥ 2 + a , 0 ) L(A, P, N)=\max \left(\|f(A)-f(P)\|^{2}-\|f(A)-f(N)\|^{2}+a, \quad0\right) L(A,P,N)=max(∥f(A)−f(P)∥2−∥f(A)−f(N)∥2+a,0)
对于整个训练集:总的损失是所有的单个三元组损失之和
训练集选择原则:
- 同一个人需要有多张照片,不然不能产生足够多的数据(且AP,AN比例会不均衡)
- 要选择比较难的组合来训练 d ( A , P ) ≈ d ( A , N ) d(A,P) \approx d(A,N) d(A,P)≈d(A,N) ,这样还可以增加学习的效率
- 如果随机选择,其中很多样本太简单,算法不会有什么效果,因为网络总是很轻松的得到正确结果
注意:获得足够多的人脸数据不容易,可以下载别人的预训练模型,而不是一切从头开始
5. 人脸验证与二分类
Triplet loss 是一个学习人脸识别卷积网络参数的好方法,还可以把人脸识别当成一个二分类问题

把人脸验证当作一个监督学习,创建一个只有成对图片的训练集,不是三个一组,目标标签是1表示是一个人,0表示不同的人。
利用不同的成对图片,使用反向传播算法去训练Siamese神经网络。
6. 什么是神经风格迁移

7. 深度卷积网络在学什么
浅层的隐藏单元通常会找一些简单的特征,比如边缘或者颜色阴影
一个深层隐藏单元会看到一张图片更大的部分,在极端的情况下,可以假设每一个像素都会影响到神经网络更深层的输出,靠后的隐藏单元可以看到更大的图片块

8. Cost function

J ( G ) = α ∗ J content ( C , G ) + β ∗ J style ( S , G ) J(G) = \alpha*J_{\text{content}}(C,G) + \beta*J_{\text{style}}(S,G) J(G)=α∗Jcontent(C,G)+β∗Jstyle(S,G)
算法步骤:
- 随机生成白噪声图片
- 使用代价函数 J ( G ) J(G) J(G),梯度下降将其最小化
- 更新 G : = G − ∂ ∂ G J ( G ) G := G - \frac{\partial}{\partial G}J(G) G:=G−∂G∂J(G),更新像素值

9. Content cost function
通常会选择网络的中间层 l l l 出来计算损失
J content ( C , G ) = 1 2 ∥ a [ l ] [ C ] − a [ l ] [ G ] ∥ 2 J_{\text {content }}(C, G)=\frac{1}{2}\left\|a^{[l][C]}-a^{[l][G]}\right\|^{2} Jcontent (C,G)=21∥∥∥a[l][C]−a[l][G]∥∥∥2
a [ l ] [ C ] , a [ l ] [ G ] a^{[l][C]},a^{[l][G]} a[l][C],a[l][G] 表示 l l l 层的两个图片 C, G 的激活函数值
10. Style cost function
图片的风格定义为层 l l l 中各个通道之间激活项的相关系数

style matrix 风格矩阵(又叫 Gram 矩阵):
G k k ′ [ l ] ( S ) = ∑ i = 1 n H [ l ] ∑ j = 1 n W [ l ] a i , j , k [ l ] ( S ) a i , j , k ′ [ l ] ( S ) G_{k k^{\prime}}^{[l](S)}=\sum_{i=1}^{n_{H}^{[l]}} \sum_{j=1}^{n_{W}^{[l]}} a_{i, j, k}^{[l](S)} a_{i, j, k^{\prime}}^{[l](S)} Gkk′[l](S)=i=1∑nH[l]j=1∑nW[l]ai,j,k[l](S)ai,j,k′[l](S)
G k k ′ [ l ] ( G ) = ∑ i = 1 n H [ l ] ∑ j = 1 n W [ l ] a i , j , k [ l ] ( G ) a i , j , k ′ [ l ] ( G ) G_{k k^{\prime}}^{[l](G)}=\sum_{i=1}^{n_{H}^{[l]}} \sum_{j=1}^{n_{W}^{[l]}} a_{i, j, k}^{[l](G)} a_{i, j, k^{\prime}}^{[l](G)} Gkk′[l](G)=i=1∑nH[l]j=1∑nW[l]ai,j,k[l](G)ai,j,k′[l](G)
G k k ′ [ l ] = ∑ i = 1 n H [ l ] ∑ j = 1 n W [ l ] a i , j , k [ l ] a i , j , k ′ [ l ] G_{k k^{\prime}}^{[l]}=\sum_{i=1}^{n_{H}^{[l]}} \sum_{j=1}^{n_{W}^{[l]}} a_{i, j, k}^{[l]} a_{i, j, k^{\prime}}^{[l]} Gkk′[l]=i=1∑nH[l]j=1∑nW[l]ai,j,k[l]ai,j,k′[l]
然后两个图像的风格矩阵做差,再求 Frobenius范数,在乘以归一化常数,就得到 l l l 层的风格损失
对各层都使用风格代价函数,会让结果变得更好,在神经网络中使用不同的层,包括类似边缘的低级特征的层,以及高级特征的层,使得神经网络在计算风格时能够同时考虑到这些低级和高级特征

用梯度下降法,或更复杂的优化算法来找到一个合适的图像 G G G,并计算 J ( G ) J(G) J(G) 的最小值
11. 一维到三维推广
一维推广:

三维推广:
医学CT扫描(使用X光照射,输出身体的3D模型,CT扫描可以获取你身体不同片段)

还有例子,可以将电影中随时间变化的不同视频切片看作是3D数据,将这个技术用于检测动作及人物行为
作业
本文地址:https://michael.blog.csdn.net/article/details/108775763
我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!
