文章目录
一、正则表达式
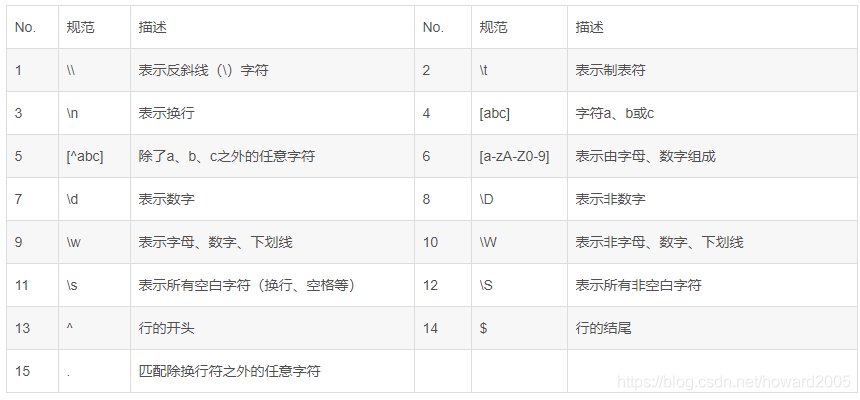
1、规范表示
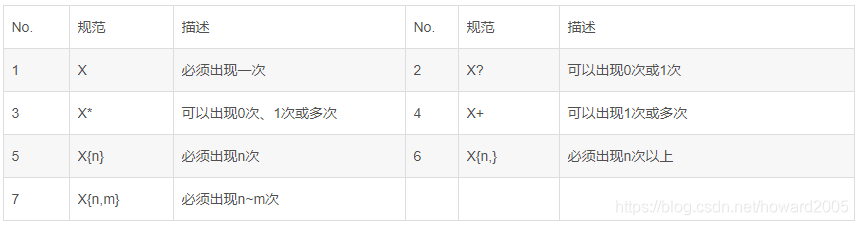
2、数量表示
- 说明:X表示一组规范
3、逻辑运算符
- 说明:X、Y表示一组规范

二、Python正则表达式模块 - re
re.match#从头匹配re.search#全局匹配第一个符合的字符串re.findall#匹配全部,放到列表re.finditer#找到匹配的所有子串,并把它们作为一个迭代器返回。这个匹配是从左到右有序地返回。如果无匹配,返回空列表。用for 循环出匹配到值。re.split#匹配到到值进行分割。re.sub# 以正则表达式为基础的替换工作。
三、字符串清洗
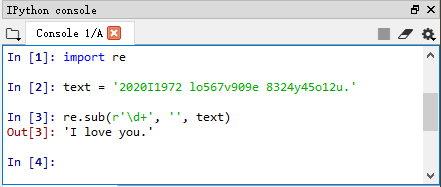
1、清洗字符串中的数字
2、清除网址中的垃圾字符
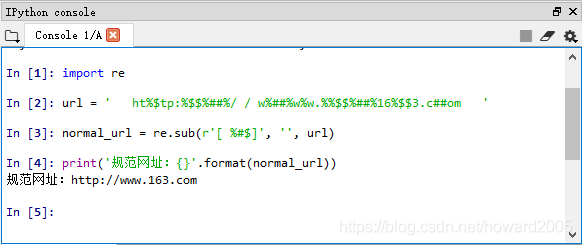
网址中包含垃圾字符,比如ht%$tp:%$$%##%/ / w%##%w%w.%%$$%##%16%$$3.c##om,包含的垃圾字符有空格、%、$与#,需要清洗掉,变成规范的网址:http://www.163.com。
四、字符串提取
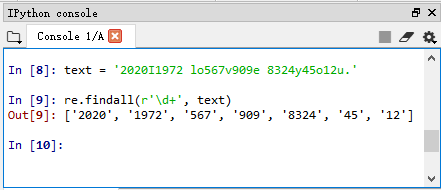
1、提取字符串中的全部正整数
2、提取字符串中的全部实数
text = 'amy68.5mike-90.5brian67.8green56.2smith60brown-90'
re.findall(r'(\+*\-*\d+\.*\d*)', text)
['68.5', '-90.5', '67.8', '56.2', '60', '-90']

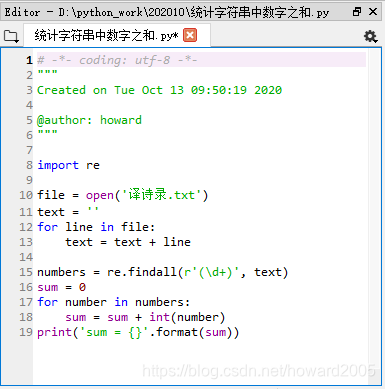
3、统计文件中全部数字之和
-
创建文本文件 - 译诗录.txt

-
编写程序 - 统计字符串中数字之和.py
-
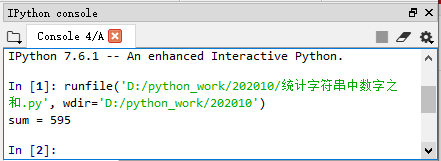
运行程序,查看结果
4、获取字符串中的邮箱、手机号码、网址和IP地址
- 创建程序 - 获取字符串中特殊数据.py
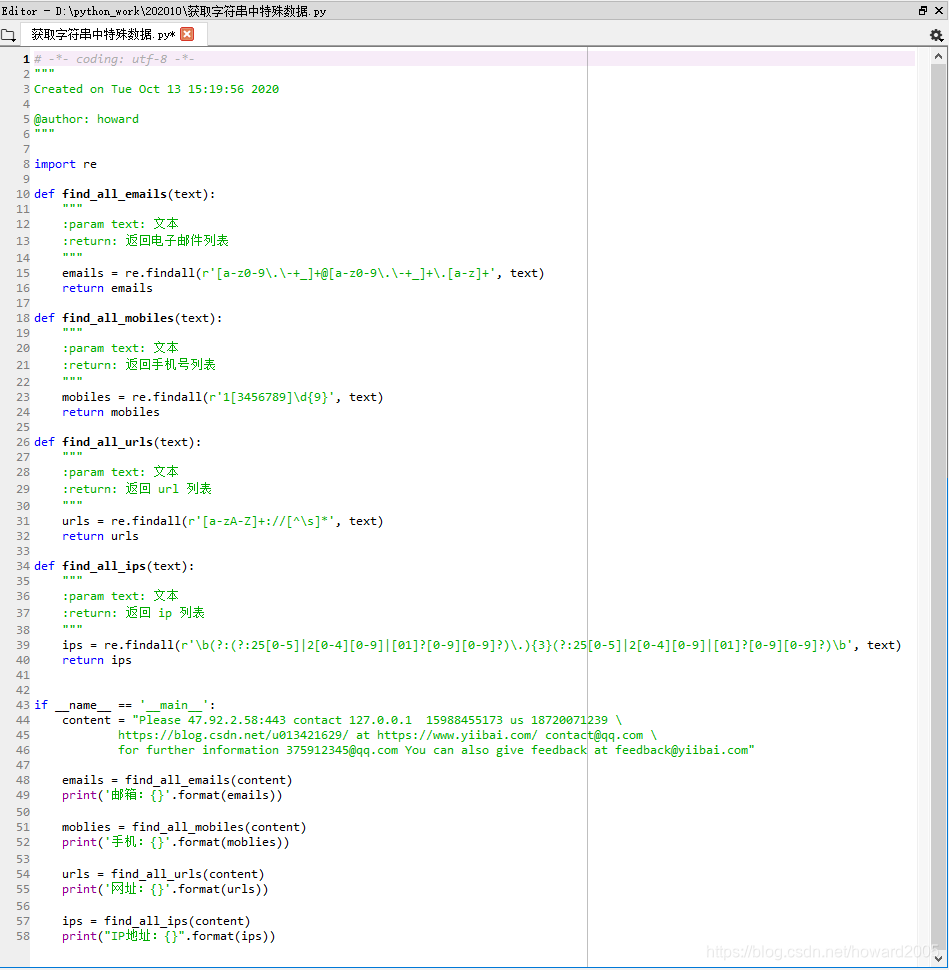
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 13 15:19:56 2020
@author: howard
"""
import re
def find_all_emails(text):
"""
:param text: 文本
:return: 返回电子邮件列表
"""
emails = re.findall(r'[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+', text)
return emails
def find_all_mobiles(text):
"""
:param text: 文本
:return: 返回手机号列表
"""
mobiles = re.findall(r'1[3456789]\d{9}', text)
return mobiles
def find_all_urls(text):
"""
:param text: 文本
:return: 返回 url 列表
"""
urls = re.findall(r'[a-zA-Z]+://[^\s]*', text)
return urls
def find_all_ips(text):
"""
:param text: 文本
:return: 返回 ip 列表
"""
ips = re.findall(r'\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b', text)
return ips
if __name__ == '__main__':
content = "Please 47.92.2.58:443 contact 127.0.0.1 15988455173 us 18720071239 \
https://blog.csdn.net/u013421629/ at https://www.yiibai.com/ contact@qq.com \
for further information 375912345@qq.com You can also give feedback at feedback@yiibai.com"
emails = find_all_emails(content)
print('邮箱:{}'.format(emails))
moblies = find_all_mobiles(content)
print('手机:{}'.format(moblies))
urls = find_all_urls(content)
print('网址:{}'.format(urls))
ips = find_all_ips(content)
print("IP地址:{}".format(ips))
- 运行程序,查看结果
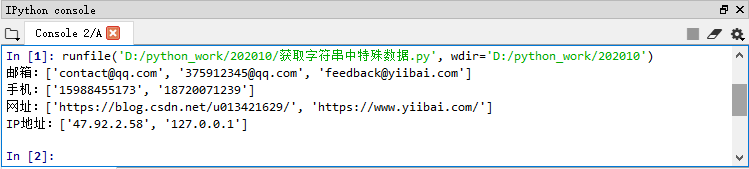
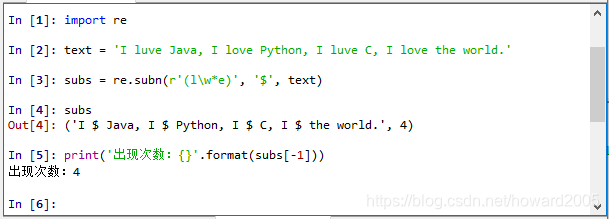
五、统计子串出现次数
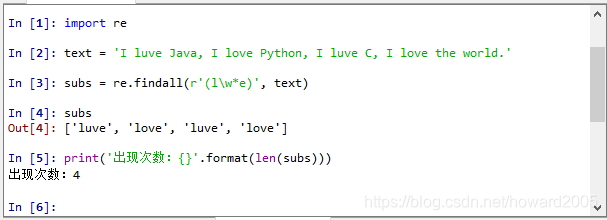
1、利用findall()函数
2、利用subn()函数