知识点1 预备知识
1.计算机只能够识别认识数字,不认识字母和符号,所以有必要搭建一个数字与其他符号之间的映射关系表;
2.有许许多多的映射关系,例如1980年诞生的ASCII表就是其中的一种,是一种用于信息交互的美国标准代码。
知识点2 ord()函数
ord()函数的作用是将每一个字符转化为其对应的ASCII嘛,即数字。
在这里可以结合一下之前的一些知识,方便进行更好的理解:
-
对于每一个字符的表示,每一个字符都是由0~256之间的一个数字表示,存储在一个8bit大小的存储空间当中;
-
8bit相当于1byte大小的存储空间,因此可以理解为,一个字符大小就是1byte。
代码展示:
>>> print(ord('3'))
51
>>> print(ord('H'))
72
>>> print(ord('h'))
104
>>> print(ord('\n'))
10
知识点3 Unicode字符集
由于全国各地有着不同的语言和字符,因此不能单一地代用ASCII码这种单一的映射编码方式,例如日本的计算机与美国的计算机之间就不能直接进行交互,因此Unicode字符集应运而生。
需要注意的是,Unicode是一种字符集,规定了符号对应的二进制代码,是编码字符集,不是实际的编码方案。
最初的Unicode用的是一个16位长度的2进制序列,即65535个,随着字符数量的增多,逐渐出现了65535不够用的情况,因此产生了扩展位。
在Unicode字符集诞生后,就产生了新的问题,如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
因此,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
utf-8\utf-16\utf-32都是属于Unicode编码的表现形式,具体有以下的几种特征:
- utf-16 固定长度,占2个字节
- utf-32 固定长度,占4个字节
- utf-8 非固定长度,占1-4个字节
- 均向上兼容ASCII码
- 自动检测是ASCII码还是utf-8
- utf-8更适用于系统时间数据的编码和传输
- 相较而言,utf-8的编码方式是最出色的
为何utf-8是较为出色的呢?
1.utf-8是unicode的实现,适用于全球所有字符;
2.utf-8是边长的,可以根据不同的字符用1-3个字节来表示,具体实现是通过其标志位,这样相对于其他几种更加节省存储空间。
知识点4 不同编码方式py2和py3的区别
以下通过代码阐释详细的区别:
py2代码
Python 2.7.10
>>> x = '이광춘'
>>> type(x)
<type 'str'>
>>> x = u'이광춘'
>>> type(x)
<type 'unicode'>
>>>
py3代码
Python 3.5.1
>>> x = '이광춘'
>>> type(x)
<class 'str'>
>>> x = u'이광춘'
>>> type(x)
<class 'str'>
>>>
根据输出结果可知:
- 在py2当中,字符串和unicode是两种不同的类型需要通过u来进行转化,十分麻烦;
- 在py3当中,所有的都是字符串类型,在python世界中,所有的东西都是unicode的,不管是亚洲文字还是欧洲,所以不用费力进行转换工作了,十分方便。
以上,阐述的是第一个区别,第二个区别,如下图所示:

根据结果可知:
- 在py2当中,byte类型与str类型是一样的,但是它们与unicode类型是不一样的;
- 在py3当中,str类型与unicode类型是一样的,但是它们与byte类型是不一样的;
- byte这种类型是raw(未经加工),unencoded(未经编码)的最原始的数据。
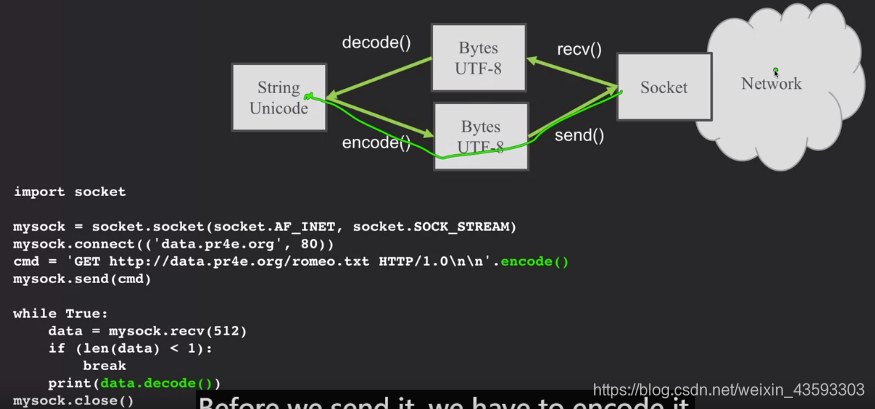
由此,我们可以知道,当python用于处理文件的时候,从文件中读取的字符串通常都是可以直接使用的,而如果要与网络交互数据,取得的一般都是utf-8(最原始的byte数据),所以需要进行编码解码,变成unicode。
代码示例python字符串与byte之间的转化:
while True:
data = mysock.recv(512)
if (len(data) < 1):
break
mystring = data.decode()
print(mystring)
- 当我们与外部资源交互的时候,我们发送给外部是bytes,因此需要对py3的字符串进行encoding编码得到对应的utf-8或者别的类型(utf-16\utf-32\ASCII等);
- 反过来说,当从外部资源读数据到py3的时候,需要解码。
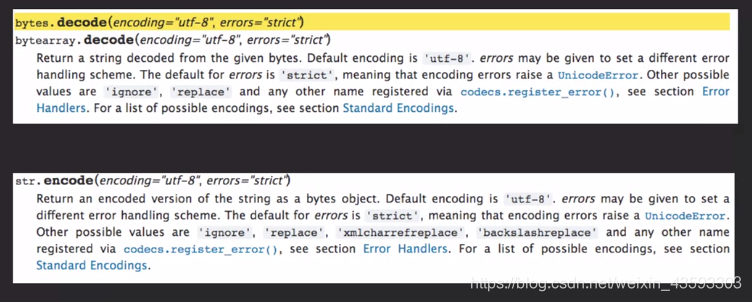
- 从python的功能函数可以有更加直观的体现,encode与decode分别是str与byte的功能函数,往外发送的一定是byte,接受回来的得经过decode变成unicode。
- 明确地说,utf-8是一种编码方式,python字符串经过utf-8编码方式变成byte数据类型发送。