什么是码点
这就要提到unicode了,unicode是一个大集合,里面的规模可以容纳100多万个符号,每个符号的编码都不一样,为了会有unicode,ASCII根本不够用啊,而且没一个统一标准,即使用到限制位,不同的国家同样的编码代表的符号可能都不一致,何况还有亚洲国家呢。所以为每一个字符分配一个唯一的数字,这个数字就是码点。
Unicode
unicode是分区定义。每个区可以存放 65536 个(2^16)字符,称为一个平面。目前,一共有 17 个平面。最前面的 65536 个字符位,称为基本平面(简称 BMP ),它的码点范围是从 0 到 2^16−1,写成 16 进制就是从 U+0000 到 U+FFFF。所有最常见的字符都放在这个平面,这是 Unicode 最先定义和公布的一个平面。剩下的字符都放在辅助平面(简称 SMP ),码点范围从 U+010000 到 U+10FFFF。JavaScript 内部,字符以 UTF-16 的格式储存
UTF-16
UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。它的编码规则很简单:基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。也就是说,UTF-16 的编码长度要么是 2 个字节(U+0000 到 U+FFFF),要么是 4 个字节(U+010000 到 U+10FFFF)。那么问题来了,当我们遇到两个字节时,到底是把这两个字节当作一个字符还是与后面的两个字节一起当作一个字符呢?在基本平面内,从 U+D800 到 U+DFFF 是一个空段,即这些码点不对应任何字符。因此,利用这个空段来做辅助平面的映射即可。辅助平面的字符位共有2^20个。需要20个二进制位表示。然而二个字节只能表达16位,所以需要两个基本平面码点来映射辅助平面。故很巧妙的UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF,称为高位(H),后 10 位映射在 U+DC00 到 U+DFFF,称为低位(L)因此,当我们遇到两个字节,发现它的码点在 U+D800 到 U+DBFF 之间,就可以断定,紧跟在后面的两个字节的码点,应该在 U+DC00 到 U+DFFF 之间,这四个字节必须放在一起解读。
ES6
1.JavaScript 允许采用\uxxxx形式表示一个字符,其中xxxx表示字符的 Unicode 码点。在ES6之前,这种表达方式仅仅限制码点在\u0000~\uFFFF之间的字符,超出这个范围的字符,必须用两个双字节的形式表示。如今ES6允许将码点放进大括号就能正常解释一一个字符。
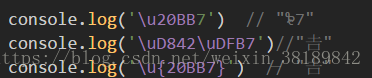
2.对于Unicode 码点大于0xFFFF的字符,JavaScript会认为是两个字符,对于这种四个字节的字符,JavaScript往往无法正确处理,ES6新方法codePointAt 可以正确识别4个字节的字符
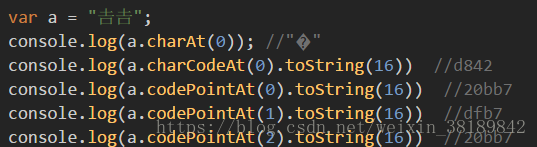
可以发现codePointAt 还是有一个小bug的,第一个字符返回的是正确的码号,但是第二个字符返回的其实是后两个字节
3.ES6之前String.fromCharCode可以将码点转换为字符,但是无法识别32位即4字节的字符,然而ES6退出了String.fromCodePoint可以正确识别大于0xFFFF的字符。

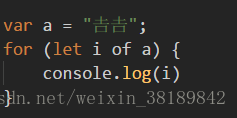
4.当然最最牛逼的就是for of了,字符串的遍历器能够正确遍历码点大于0xFFFF的字符。