对于处理过中文的Python程序员来说,想必对UnicodeEncodeError和UnicodeDecodeError并不陌生。为了更好的理解Python中的编码问题,我们首先介绍一下字符编码以及Python的两种字符串类型:str和unicode之间的区别。
字符编码
我们在编辑器中输入的文字,对用户来说是可读的。但是机器只能读懂01串,那怎么把我们方便阅读的符号转换成机器能读懂的01串呢?
这就需要给出符号-二进制之间的映射关系,而且必须是一一映射:即给定一个符号,机器有而且有唯一的二进制对应。根据字符得到二进制表示是编码过程(encode);根据二进制表示得到字符是解码过程(decode)。
ASCII字符集与字符编码
刚开始的时候,给出了ASCII标准,用一个8bits字节来表示字符。而且这个字节实际上只用了7位,最高位是不用的,这样总共能表示128个字符。意味着ASCII字符集只有128个。
随着计算机的普及,越来越多的国家开始使用计算机。128个字符难以满足各个国家的语言需求,这促使包含更多字符的字符集诞生,并且需要采用新的编码方案。
Latin-1
充分利用8bits字节的高位,扩展到256个字符。
Unicode字符集与字符编码
Unicode字符集包含了所有种语言的所有字符。通常用U+后接4位的16进制数字表示一个Unicode字符,比如U+FFFF。
UTF-8编码
UTF-8是针对Unicode字符集的一种编码方案。
用变长字节来表示字符:有的字符用一个字节表示(比如ASCII中规定的字符),有的字符用2个字节表示。最大长度为4字节。
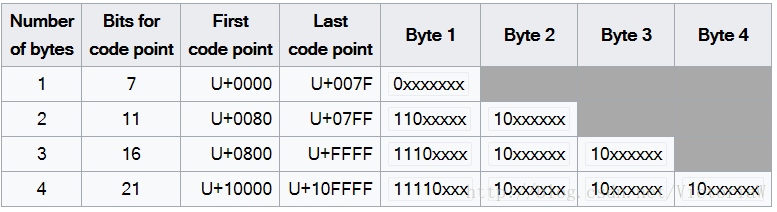
上面这张图是从Wikipedia中截取的。Number of Bytes列表示字节数;Bits for code point列表示多少个bit位是真正有用的;First code point列表示该字节数能表示的第一个Unicode字符;Last code point列表示对应字节数能表示的最后一个Unicode字符;Byte i(i=1,2,3,4)列表示第i字节上的bit值。
以第二行为例,这一行的编码需要两个字节,其中真正有用的bit位只有11个,另5位是占位符,能表示从U+0080~U+07FF的Unicode字符。

至于具体的编码方式,我们以欧元符号€为例。€在Unicode字符集中对应U+20AC:
- U+20AC位于U+0800~U+FFFF之间,所以需要三个字节来表示;
- 十六进制20AC可以写成二进制:0010 0000 1010 1100;
- 前4个bit放在第一字节的低4位:11100010;
- 中间6个bit放在第二字节的低6位:10000010;
- 后6个bit放在第三字节的低6位:10101100;
于是€的UTF-8编码为:11100010 10000010 10101100。
Unicode字符集还有其他的编码方式,这里就介绍到这里。
要记住:所有的编码方式都是向后兼容ASCII的。ASCII字符对应什么二进制,那么在其他编码方式中也对应同样的二进制。
Python的字符串类型
Python包含两种字符串类型:str(其实就是二进制)和unicode。当只会用到ASCII字符集时,一切相安无事。一旦出现其他字符集,问题也就接踵而来。所以下面我们着重介绍非ASCII字符串。
- str类型
我们平时写的用引号括起来的字符串都是str类型的。
>>> x = '哈哈'
>>> x
'\xb9\xfe\xb9\xfe'- 1
- 2
- 3
根据上面的打印结果,可以知道str类型的x存的其实是二进制序列,而非字符串。为什么会出现这种情况呢?我们赋给x的明明是字符串。
其实很简单,x经过了一次隐形的编码过程encode()。应该采用的是系统默认编码方案。
- unicode类型
如果在引号的前面加上字符u,那么我们就得到一个unicode字符串:
>>> x = u'哈哈'
>>> x
u'\u54c8\u54c8'- 1
- 2
- 3
unicode对象保存的是字符串本身,而非二进制序列。比如程序中的unicode字符串中包含两个U+54c8字符。
unicode编码为str
但是有的时候,我们需要二进制序列,比如将数据写入文件、发送到网络或者写入数据库中时。如果不进行任何处理,会出现错误:
>>> x = u'哈哈'
>>> x
u'\u54c8\u54c8'
>>> f = open('test.txt', 'w');
>>> f.write(x)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这是因为在把字符串写入文件时,会首先检查字符串的类型,如果是str类型的字符串,那么一切OK;如果是unicode类型的字符串,那么会隐式地对其编码,即x.encode()。而系统默认的编码方案是ASCII(可以通过sys.getdefaultencoding()查看),对非ASCII字符进行编码的时候,肯定会出现错误。
为了避免错误,在写入文件之前,应该用utf-8或者gbk编码方案对unicode字符串编码:
>>> x = u'哈哈'
>>> x
u'\u54c8\u54c8'
>>> f = open('test.txt', 'w');
>>> x = x.encode('utf-8') #unicode -> str
>>>x
'\xe5\x93\x88\xe5\x93\x88'
>>> f.write(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
str解码为unicode
当从文本中读取数据时,读到的是str字符串,而且我们已经知道,它保存的是二进制序列。如果其中包含非ASCII文本,我们应该怎么恢复呢?这时候就要用到解码decode()。
>>> f = open('test.txt', 'w');
>>> x = f.read()
>>> x
'\xe5\x93\x88\xe5\x93\x88'
>>> x = x.decode('utf-8') #str -> unicode
>>> x
u'\u54c8\u54c8'- 1
- 2
- 3
- 4
- 5
- 6
- 7
一定要记得,用什么方式编码的就必须用什么方式解码。不然的话,从二进制到字符的对应过程会出现UnicodeDecodeError。
print语句
print语句的参数需要是str类型,而且在执行的时候会用系统的编码方式对str进行隐式解码。
两个遗留问题
#-*-coding:utf-8 -*-
现在暂且认为如果脚本中包含中文,那么必须加上这个声明。setdefaultencoding()
这个方法貌似现在不可以用了。我觉得这个设置与encode()、decode()在不指明参数的情况下的默认参数有关。