1
总括
首先我们来看一下AdaGrad算法
我们可以看出该优化算法与普通的sgd算法差别就在于标黄的哪部分,采取了累积平方梯度。
简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同
2
作用
那么它起到的作用是什么呢?
起到的效果是在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
下面通过例子讲解一下:
假设我们现在采用的优化算法是最普通的梯度下降法mini-batch。它的移动方向如下面蓝色所示: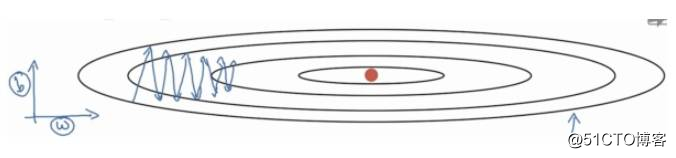
假设我们现在就只有两个参数w,b,我们从图中可以看到在b方向走的比较陡峭,这影响了优化速度。
而我们采取AdaGrad算法之后,我们在算法中使用了累积平方梯度r=:r + g.g。
从上图可以看出在b方向上的梯度g要大于在w方向上的梯度。
那么在下次计算更新的时候,r是作为分母出现的,越大的反而更新越小,越小的值反而更新越大,那么后面的更新则会像下面绿色线更新一样,明显就会好于蓝色更新曲线。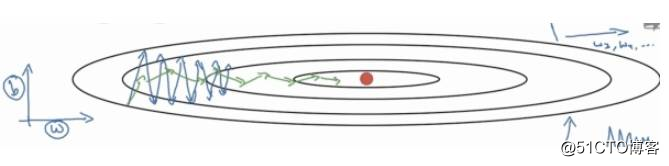
在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
这就是AdaGrad优化算法的直观好处。
参考:YBB的Deep Learning 最优化方法之AdaGrad
吴恩达老师DeepLearning.ai课程slides
推荐阅读:
精选干货|近半年干货目录汇总
干货|吴恩达 DeepLearning.ai 课程提炼笔记(1-2)神经网络和深度学习 --- 神经网络基础
干货|吴恩达 DeepLearning.ai 课程提炼笔记(1-3)神经网络和深度学习 --- 浅层神经网络
欢迎关注公众号学习交流~ 
欢迎加入交流群交