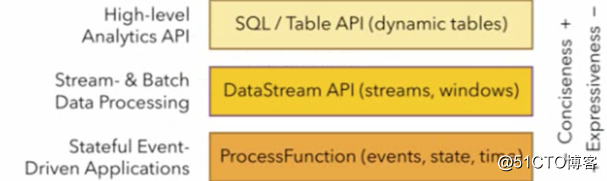
Flink对批处理和流处理,提供了统一的上层API
Table API是一套内嵌在java和scala语言中的查询api,它允许以非常直观的方式组合来自一些关系运算符的查询
Flink的sql支持基于实现了sql标准的Apache calcite
先来个栗子感受下:
demo效果: 在数据源txt中读取,输出id和temperature 这2个字段,按照id做筛选,输出,分别用table api和sql来实现
在pom.xml中加入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<!-- 也可以不用引入下面的包,因为上面已经包含了-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>1.10.1</version>
</dependency>在tabletest包下建一个Example object:
package com.mafei.apitest.tabletest
import com.mafei.sinktest.SensorReadingTest5
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala._
object Example {
def main(args: Array[String]): Unit = {
//创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.getConfig.setAutoWatermarkInterval(200) //直接全局设置watermark的时间为200毫秒
val inputStream = env.readTextFile("/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt")
env.setParallelism(1)
//先转换成样例类类型
val dataStream = inputStream
.map(data => {
val arr = data.split(",") //按照,分割数据,获取结果
SensorReadingTest5(arr(0), arr(1).toLong, arr(2).toDouble) //生成一个传感器类的数据,参数中传toLong和toDouble是因为默认分割后是字符串类别
})
//首先创建表执行环境
val tableEnv = StreamTableEnvironment.create(env)
//基于流创建一张表
val dataTable: Table = tableEnv.fromDataStream(dataStream)
//调用table api进行转换
val resultTable = dataTable
.select("id, temperature")
.filter("id == 'sensor3'")
resultTable.toAppendStream[(String,Double)].print("result")
//第二种,直接写sql来实现
tableEnv.createTemporaryView("table1", dataTable)
val sql: String = "select id, temperature from table1 where id='sensor1'"
val resultSqlTable = tableEnv.sqlQuery(sql)
resultSqlTable.toAppendStream[(String, Double)].print("result sql")
env.execute("table api example")
}
}
代码结构及运行效果:
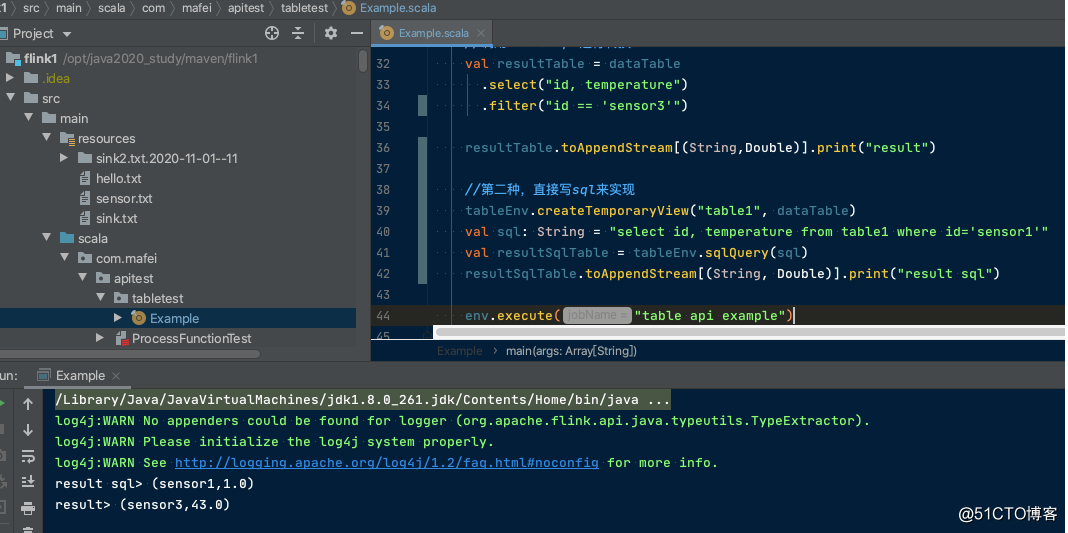
看到效果之后再来分析结构:
Table API和SQL的程序结构,与流式处理的程序结构十分类似
//创建表执行环境
val tableEnv = StreamTableEnvironment.create(StreamExecutionEnvironment.getExecutionEnvironment)
//创建一张表,用于读取数据
tableEnv.connect(....).createTemporayTable("inputTable")
//注册一张表,用于把计算结果输出
tableEnv.connect(....).createTemporaryTable("outputTable")
//通过Table API查询算子,得到一张结果表
val result = tableEnv.from("inputTable").select()
//通过sql查询语句,得到一张表
val sqlResult = tableEnv.sqlQuery("select id, temperature from table1 where id='sensor1'")
//将结果表写入到输出表中
result.insertInto("outputTable")几种引擎实现方式
Flink SQL有好几种实现方式,其中blink 是阿里内部使用后来开源合并到flink的引擎,来看看几种使用方式
/**
*
* @author mafei
* @date 2020/11/22
*/
package com.mafei.apitest.tabletest
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.{EnvironmentSettings, TableEnvironment}
import org.apache.flink.table.api.scala._
object TableApi1 {
def main(args: Array[String]): Unit = {
//1 、创建环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv = StreamTableEnvironment.create(env)
//1,1 基于老版本的planner的流处理
val settings = EnvironmentSettings.newInstance()
.useOldPlanner()
.inStreamingMode()
.build()
val oldStreamTableEnv = StreamTableEnvironment.create(env, settings)
//1.2 基于老版本的批处理环境
val batchEnv = ExecutionEnvironment.getExecutionEnvironment
val oldBatchTableEnv = BatchTableEnvironment.create(batchEnv)
//1.3基于blink planner的流处理
val blinkStreamSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val blinkStreamTableEnv = StreamTableEnvironment.create(env, blinkStreamSettings)
//基于blink planner的批处理
val blinkBatchSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inBatchMode()
.build()
val blinkBatchTableEnv = TableEnvironment.create(blinkBatchSettings)
}
}