1.neural machine translation by jointly learning to align and translate
这篇文章是将attention机制应用于机器翻译上,普通的seq2seq模型要将输入文本的信息编码至固定长度的隐向量中,当面对长文本时会损失许多信息,那么就要利用attention对输入文本的不同片段根据其重要程度分配不同的权重,使得信息被更有效地编码。传统seq2seq模型由于相当于对输入的每一部分都固定分配相同的权重而被称为硬对齐(hard-alignments),加入attention机制就实现了输入和输出的软对齐(soft-alignments)。
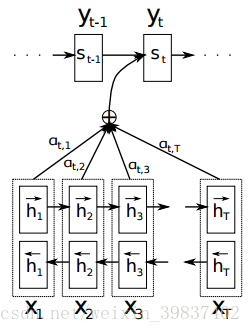
编码过程即将输入序列输入RNN,得到各时间步的RNN隐向量。
解码过程根据context vector ci、上一时间步的输出yi-1和当前的RNN隐向量si计算得到当前时间步的输出概率分布,g为非线性函数。
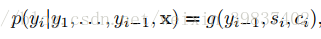
si由下式计算而得:
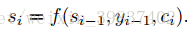
普通seq2seq使用固定的context vector ci,而attention seq2seq的context vector由如下过程生成:
a为匹配度计算函数,文章中a函数使用了一个感知机来训练得到,其参数会在训练过程中通过BP算法得到更新,si-1为上一时间步的隐状态,hj为输入序列中的单词。
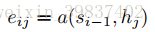
计算得到各个单词的attention值eij后,使用softmax将其归一化,得到每个单词相对于翻译过程当前时间步的重要程度即权重αij。

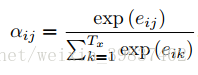
最终根据这些权重,新的context vector由输入序列各时间步的隐向量的attention加权和来表示,这样在解码的每一个时间步,都可以使用一个专属定制的context vector,无需把所有信息都考虑进去,只需考虑对当前解码更重要的context部分。
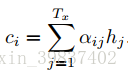
整个解码流程如下图所示:
2.Effective Approaches to Attention-based Neural Machine Translation
本文针对NMT任务使用的attention机制提出两种结构,global attention将attention作用于全部输入序列,local attention每个时间步将attention作用于输入序列的不同子集。前者被称为soft attention,其原理和论文1一样,后者是hard attention和soft attention的结合,该文通过context vector ct和隐向量ht来预测当前输出:


两种attention机制不同的是context vector的计算:
Global Attention

在global attention中,将输入序列的各个时间步都考虑进去,每个时间步的attention值由下式计算而得:

文章尝试了多种匹配度计算函数,实验表明第二种函数效果较好:

Local Attention

为了进一步减少计算代价,在解码过程的每一个时间步仅关注输入序列的一个子集,于是在计算每个位置的attention时会固定一个上下文窗口,而不是在全局范围计算attention。根据一个预测函数,先预测当前解码时要对齐的源语言端的位置Pt,然后通过上下文窗口,仅考虑窗口内的词,Pt可以直接等于当前解码的位置或是使用感知机进行预测,S是当前序列的长度,v和W为感知机的参数。

论文1中当前的context vector会参与生成当前的RNN隐向量,由此将每一步的context信息传递下去,这篇文章直接将融合了context信息和上一步隐状态信息的ht hat作为下一时间步的输入以达到这个目的:
