前言
前段时间笔者一直在折腾HDFS大目录删除的性能问题,也尝试了很多不同的方案来降低大目录删除所带来的性能影响,包括改INodeDirectly内部child list结构,或者是在Snapshot层面做改进优化等等(详见此文章:HDFS大目录文件删除方案的实践思考)。不过后续笔者在对比HDFS的删除操作和新一代存储Ozone系统内部的删除操作时,发现二者还是存在不少区别的,后者在设计上有着不小的改进之处。本文笔者来聊聊关于HDFS和Ozone的删除行为操作的对比,以及后面对HDFS现有删除操作的一些brainstorm的一些想法。
现有HDFS删除操作的性能问题
重新再回到这个老生常谈的问题–HDFS删除操作性能问题,用简单两个词简单概括:第一操作重,第二影响大。
这个过程简单来说如下:
- 1)递归遍历目录树结构,收集里面需要被清除的INode实例(包括INode目录和INode文件),以及INodeFile下面所属的block块,即待删除的块。
- 2)然后执行block的批量删除操作,每一批处理完毕,中间释放一下锁,然后再拿锁进行处理。
鉴于上述过程涉及到NameNode元数据的改动,因此都是在持有FSN全局锁的情况下执行的,因此这个过程就变得很重了。
下图是HDFS内部数据删除过程的一个简要示意图:
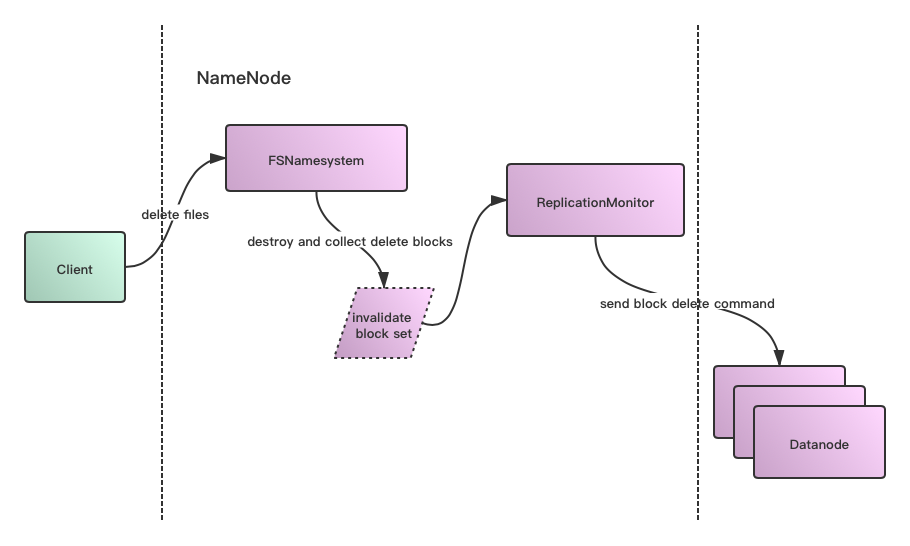
在上述过程中,中间待删除的数据块信息被查询出来后,并没有做持久化,都是在一个过程中进行的,因此一个很自然的优化点设想是:
这个过程能否做到异步化处理?此外,这种一个目录一次性的清理方式能否变为多个batch式的delete行为?RemoveBlock已经是batch化了,前面清理INode的时候是否也能够做到batch处理化,而不是一下遍历完毕的方式?
OK,针对上述几个提议,出发点都是好的,不过要想实现上述几点改进势必要解决下面会出现的问题:
- 删除操作异步化处理,HDFS认为只有INode真正被清理了,才算释放quota,这里的quota一致性问题如何保证?当然如果我们允许牺牲少血的quota准确性来做异步删除,那也是可以接受的。
- 如果在INode目录树内删除的时候,做batch化处理,删到某一个INode的时候,然后结束退出,那下一次,如何恢复呢?可能会出现某些子INode出现无父INode实例的存在了。那这批被中断处理的INode将会成为脏数据驻留在NameNode里了。另外一个问题,INode删除时中途退出,是否可能出现另外的并发的操作又在读写正在删除的目录呢?
HDFS删除操作的brainstorm改进想法
针对上小节提到的几个棘手的问题,我们难道就没有办法解决了?不是的,凡是总有可行解。
首先第一个,quota不一致的问题,这个按照上面说了,我们可以牺牲一点quota的实时精准度来做delete操作的异步化这个事情,笔者认为这个取舍还是OK的。
然后第二个,关于INode的删除batch处理问题,概括起来有2个小问题:
- 中间INode退出处理的恢复问题。如果在中间按照INode删除的数量达到阈值,然后强制退出处理释放锁,确实会造成一些问题。不过我们可以对这个做个转化,先将这个目录数进行递归遍历,只收集所有的INode实例,将其存放到list结构内。然后针对INode list做batch删除操作处理。在原有目录树内做删除操作中断处理,恢复起来比较难。
- 第二个小问题是,待删除目录存在被读写的可能性在删除操作被batch中断释放的那一会。这个处理的方式比较简单,在batch删除INode的一开始,先将待删除目录文件rename成一个预留的名字,这个名字绝对不会被用户访问到,例如现有.trash之类的目录形式。简单来说,就是先做rename后delete。
有了上述几点的处理,我们再启动一个后台的线程,就可以正式做目录文件的异步化batch处理了,新的处理过程图设想如下所示:
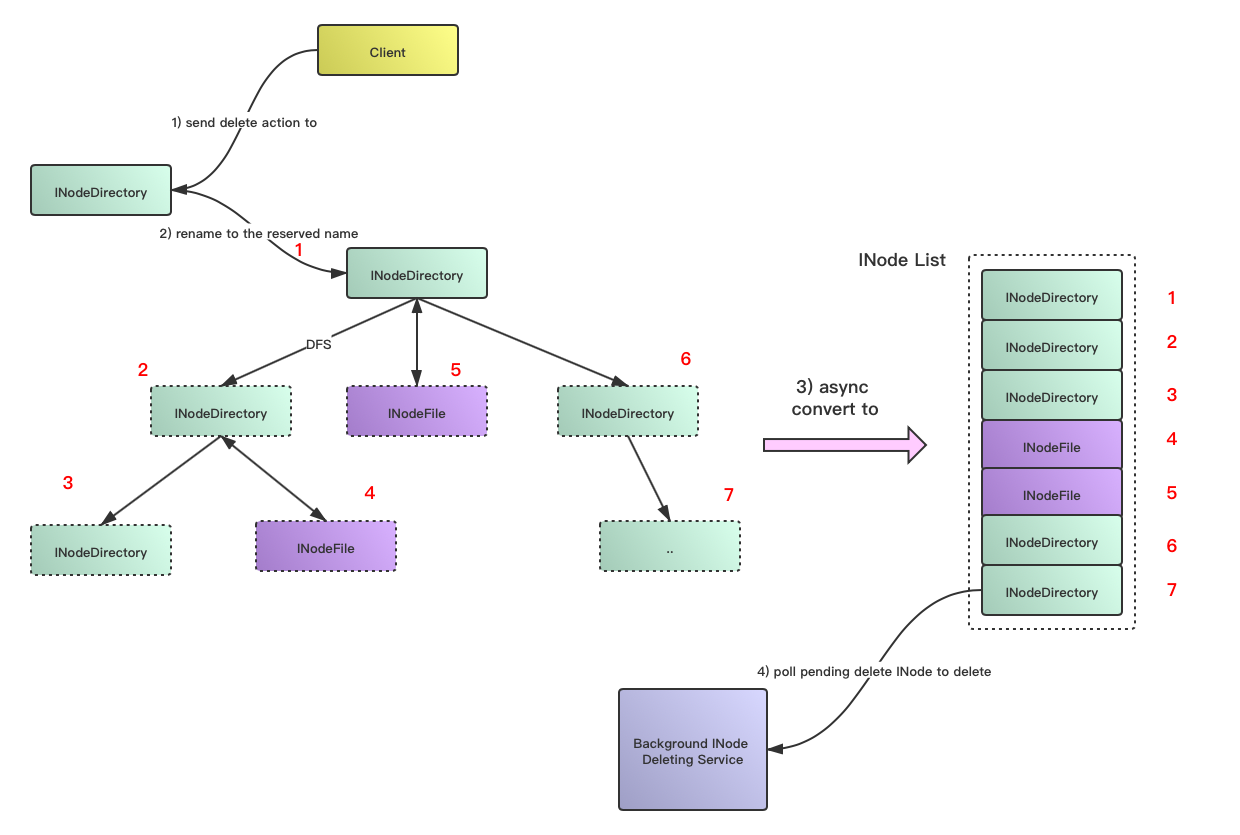
其实上图显示的过程和目前HDFS trash数据清理机制已经很接近 ,trash机制已经满足了rename成预留的名字以及后台删除这2个阶段,唯一可以改进的是将INode删除做batch化处理,而不是直接调NameNode的delete操作方法。笔者个人比较aggressive的想法是,HDFS的delete操作可以变为一个简单的rename操作,所有的实际操作行为都应该有后台专门的service去做异步处理。Client没有必要强制等待删除行为的同步执行结束,尤其在分布式存储系统中。
相关设计:Ozone系统内的删除操作处理
下面我们来看看另外一个对象存储系统Ozone在这块的设计。
首先Ozone同样作为存储系统,它也要面对大数据量删除的情况。不过它的namespace比较的简单,都是K-V,它目前不存在目录树删除的情况。因此它的删除行为比较容易做到batch化,批量拿一批待删除的Key就完事了。
它同样使用了rename成reserved名字的方式+后台删除线程的模型处理方式,Ozone目前现有的删除过程图如下所示:

上图显示Ozone内部删除过程比HDFS是要略复杂一些,源于以下几点背景原因:
- Ozone内部使用了基于Container的存储,涉及到OM SCM服务的交互通信,而不是类似于HDFS这种完全统一化的管理。
- Ozone使用了第三方K-V db存储,不是纯memory,因此它可以做删除信息的持久化处理,因此也可以比较容易做删除行为的再恢复,当系统重新启动的时候。
另外在OM和SCM服务内部,每次做删除的时候,都是有limit限制的去删除一批的数据,这样一来整个删除行为对于Ozone的系统来说,影响就会很小。
笔者在对比完Ozone的删除机理和HDFS现有的删除行为,前者在扩展性,性能上要比后者更佳,后者设计上比较简单的处理设计,因此在量大的时候就展露出了弊端。对Ozone和HDFS删除原理感兴趣的同学可继续阅读笔者之前写的相关文章,链接在文章末尾处。
相关文章
[1],https://blog.csdn.net/Androidlushangderen/article/details/105778885
[2].https://blog.csdn.net/Androidlushangderen/article/details/77619513