前言
Ozone的出现的初衷就是要解决HDFS namespace的扩展性问题,那么现在问题了,未来如何将这两大从设计上上来已经完全大改变的系统整合起来呢?这个听起来非常有意思,本文笔者结合最近社区的一些讨论,来简单聊聊这个话题。
Ozone的核心结构
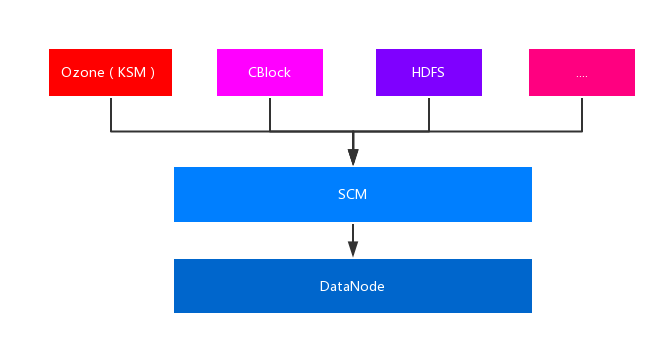
社区在设计Ozone的时候,提出了一个具有关键性意义的概念:Storage Container。而不是HDFS中的块(block)概念。二者的关系是:Storage Container对外提供块服务。而Storage Container由底层存储向外提供服务,它可以支持不同的上层系统。所以Ozone的结构是这样的:
有人会说了,将block块服务剥离开来真的有这么重要吗?答案是非常重要。如果大家维护过拥有大规模数量级块的HDFS集群,一定经历过很多很多大大小小的问题。比如说以下几点:
- 大量的块导致NameNode维护的blockMap异常庞大,耗费内存。
- 每次涉及到块更新的操作都会持有一个全局锁,导致系统平均RPC的延时会提高,触发GC更频繁。
- 块规模的变大,在很多操作上会遇到瓶颈,快照,块汇报,等等。
而在Ozone中,SCM只负责维护这些Container信息。原先的block report就会变成container report。此时的关系变为:
KSM: object —> block
SCM: block —> container
在上图中,我们看到的是1对1的关系,在未来Ozone会支持到多对多的关系,类似与目前HDFS的Federation。
如何在Ozone上构建HDFS
Ozone既然已经出现了,现在我们如何把现有HDFS移植到Ozone之上。比如达到下面的架构,这样就充分利用了新设计的架构体系。
在这里,我们需要一个关键的实现:Ozone FS,Ozone内部提供的文件系统接口。以此将新的数据写出到Ozone FileSystem,Ozfs完全兼容现有的hdfs路径格式和读取方式,可以给Spark、Hive程序使用。通过现有文件操作兼容API,可以将数据从老的HDFS转移到Ozone中。这步操作实质做的改动:将全存入内存的namespace数据移到了k-v存储的namespace中。相比于之前内存式的查询读取,K-V存储下查询的操作就变为了IO scan的方式了,效率上还是会有所影响。可能在未来,再进一步优化,只保留工作集的数据在内存中,达到新HDFS的状态结果。
当然,要想让现有HDFS更加平滑地构建于Ozone之上,还需要很多的工作需要去做。
参考资料
1.https://issues.apache.org/jira/secure/attachment/12895963/HDFS%20Scalability%20and%20Ozone.pdf”