文章目录
前言
在大规模的分布式存储系统中,数据是分布式地存储在不同的存储节点中。在节点数量达到比较大规模的时候,出现数据损坏的情况就会变得十分的常见了。数据节点出现数据损坏是很常见的现象,我们不能保证它是绝对完美的,因此我们的一个目标是使数据损坏对系统的影响降到最低甚至没有影响。这里其实就谈到了系统对于异常数据的处理机制了,相对于系统被动式地感知数据的损坏(用户访问行为错误触发),主动式的数据自检行为无疑是一种更好的解决办法。本文笔者就来聊聊Hadoop Ozone内部的数据自检服务Data Scrubbing服务,从原理上来说类似于HDFS BlockScanner和VolumeScanner的服务。
数据的损坏
首先我们来说说数据的损坏。一个磁盘数据的损坏会有很多可能的引发原因,包括软件层面的或者是硬件层面的,比如以下几类:
- 硬件层面的问题,比如磁盘驱动问题等。
- 磁盘的Bit rot位衰减问题。
- 文件系统lost write问题,比如实际内容已经写入磁盘,但在文件系统层面认为没有写入。或者是相反的情况。
当然,引发上述3类磁盘问题的影响因素也会有很多,比如:
- 磁盘的使用时间
- 磁盘的类型,比如企业级磁盘,或者近线性磁盘
- 磁盘数据的本地性访问等等
- …
当然以上种种因素导致磁盘数据损坏的情况时,我们如何能够快速地检测出来呢?我们继续往下看。
Ozone的Data Scrubbing机制
这里我们用一个 标准的术语Data Scrubbing来称呼这种行为,意为数据的清理,它也是一种数据的错误检测以及矫正的行为。
在Data Scrubbing行为中,数据的清理动作是一种自检的行为,这样能够让系统能够更迅速地感知到损坏的数据,然后进行及时地处理,减少对于用户的影响。而对于这个自检行为来说,它的要求主要有如下几点:
- 需要周期性的数据检查行为。
- 内存、磁盘元数据文件的对比检查,此行为为粗粒度的检查,执行周期可较短。
- 实际数据内容的一致性检查,这里面还会涉及到计算得到的checksum的值检查,此行为为细粒度的检查,执行周期宜较长。
- 检查行为需要有执行的进度记录标志(最后一次检查到哪个数据的哪个文件),以便下次做快速地恢复执行,无须系统每次重启后需要重头来过。这是十分有必要的,因为对于数据内容的对比检查,一个周期是需要花不少时间的。在这里,我们把这个步骤暂且叫做Data Scrubbing的checkpoint行为。
- 为了避免节点的数据自检行为影响到其上正常的数据读写服务,我们需要对此进行限流控制。
在Ozone中,当损坏的数据被Data Scrubbing服务检测出来之后,Container数据会被标记为Unhealthy状态并通知到SCM服务。然后SCM中心管理服务会进行此Container副本的replication操作,来保证数据的一个健康冗余度。
按照上述处理,Ozone下的一个完整的Data Scrubbing流程将会如下所示:
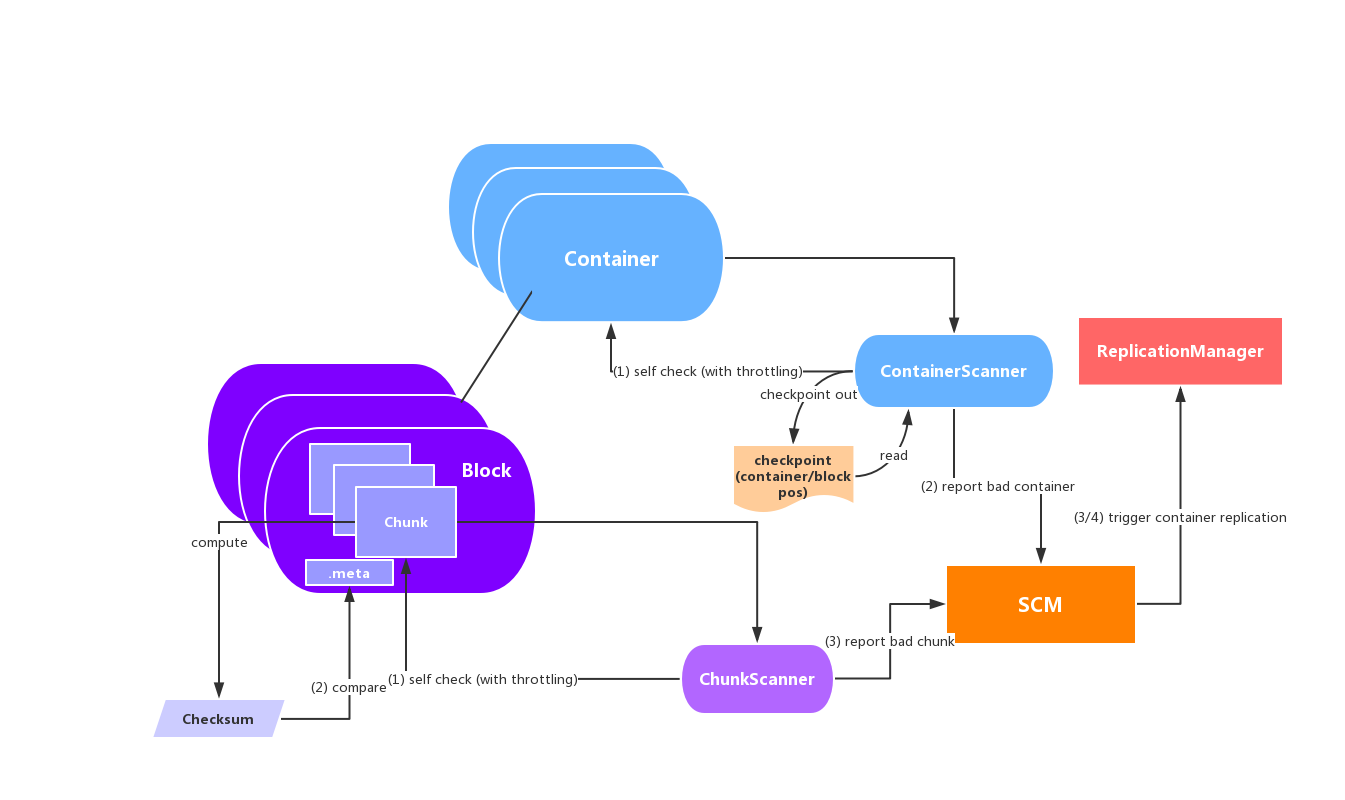

这里解释一下,Ozone内部的副本是以Container为单位的,不是Block。Block是从Container中分配出去的,它是一个逻辑概念。Block下的Chunk文件才是实际存储数据的文件。对照上文所述的, ContainerScanner是粗粒度的自检行为,而ChunkScanner则是细粒度的检查。
以上就是本文所阐述的Data Scrubbing的服务模型。
引用
[1]. https://issues.apache.org/jira/browse/HDDS-1162. Data Scrubbing for Ozone Containers
