使用requests
既然来了,那就尽情在知识的海洋遨游吧!

1. requests简介
获取网页最主要的就是如何模拟浏览器向服务器发送请求,而r第三方库requests库给我们提供了功能齐全的处理方法,下面就让我们一起来看一下requests库的强大之处吧!
2.安装requests库
- liunx用户可以直接使用命令行模式:pip3 install requests
- window10 用户也可以使用命令行模式:pip install requests或通过pycharm下载(教程链接在这里)。
3. requests库的请求方法
3.1 requests.get(url,params,headers)
构造一个向服务器请求的Request对象,并返回一个Response对象。这是最常用的方法,务必熟练掌握。其中response主要的属性如下:
- text:HTTP响应内容的字符串形式,即,url对应的页面内容
- content :HTTP响应内容的二进制形式
- encoding:从HTTP header中猜测的响应内容编码方式
- status_code:HTTP请求的返回状态,200表示连接成功,404表示失败
- apparent_ encoding:从内容中分析出的响应内容编码方式(备选编码方式)
- history:请求历史
- headers:响应的头部信息
- cookies:记录在响应中的cookies
import requests
response = requests.get("http://www.baidu.com")
# 响应的内容文本
print(response.text)
print("+"*70)
# 响应的内容(二进制形式)
print(response.content)
print("+"*70)
# 从响应头部中得到的编码方式
print(response.encoding)
print("+"*70)
# 响应体中得到的编码方式
print(response.apparent_encoding)
print("+"*70)
# 状态码,用查看请求状态
print(response.status_code)
print("+"*70)
# 响应的头部
print(response.headers)
print("+"*70)
# 响应cookies
print(response.cookies)
print("+"*70)
# url
print(response.url)
print("+"*70)
# 请求历史
print(response.history)
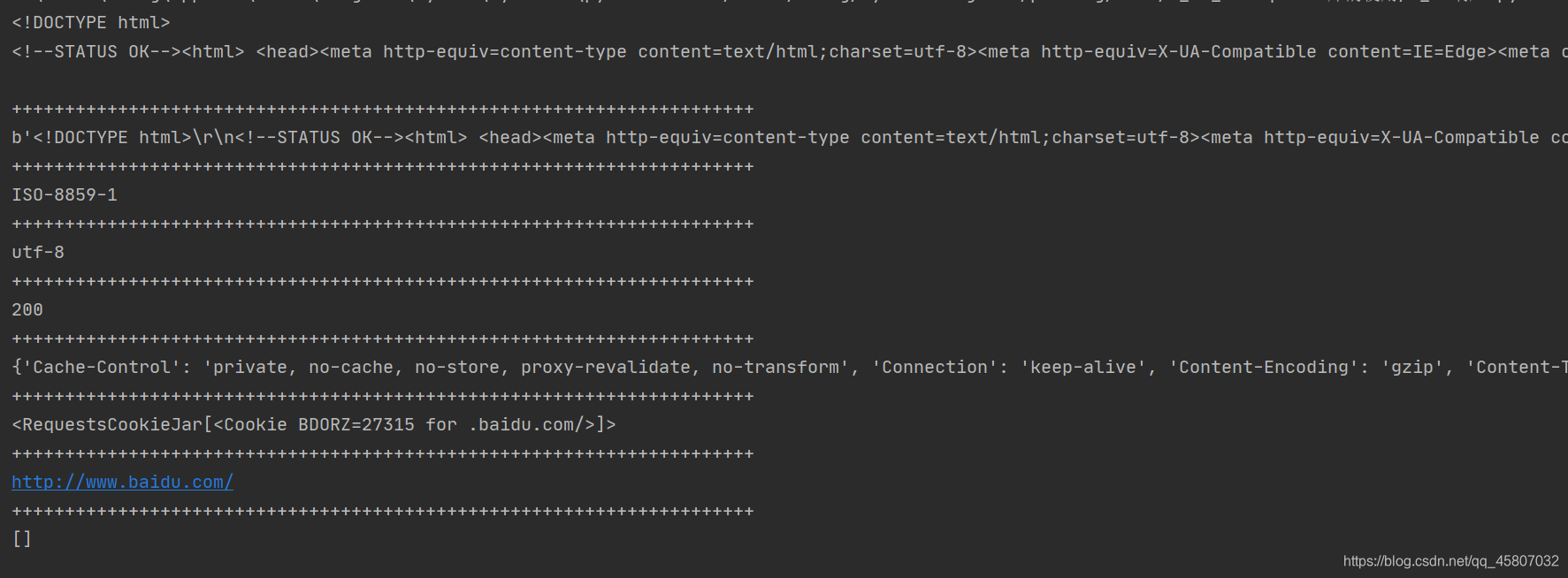
参数url是指需要爬取的网页的 url;参数headers是指需要传递的头部信息,如User-Agent,cookies等;params 是需要传递的参数,示例代码如下:
import requests
url1 ="http://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
response1 = requests.get(url1,headers=headers)
print(response1.content)
print(response1.text) # 注意区分两者区别
# 抓取二进制数据,如图片,视频等
url2 = "http://github.com/favicon.ico"
response2 = requests.get(url2,headers=headers)
p = open("github.ico","wb")
p.write(response2.content)
print("图片下载完成")
p.close()
下载的图片如下:

3.2 requests.post(url,data,file)
HTML网页提交POST请求的方法。参数data是提交的数据(一般为字典或json类型);file是上传的文件。
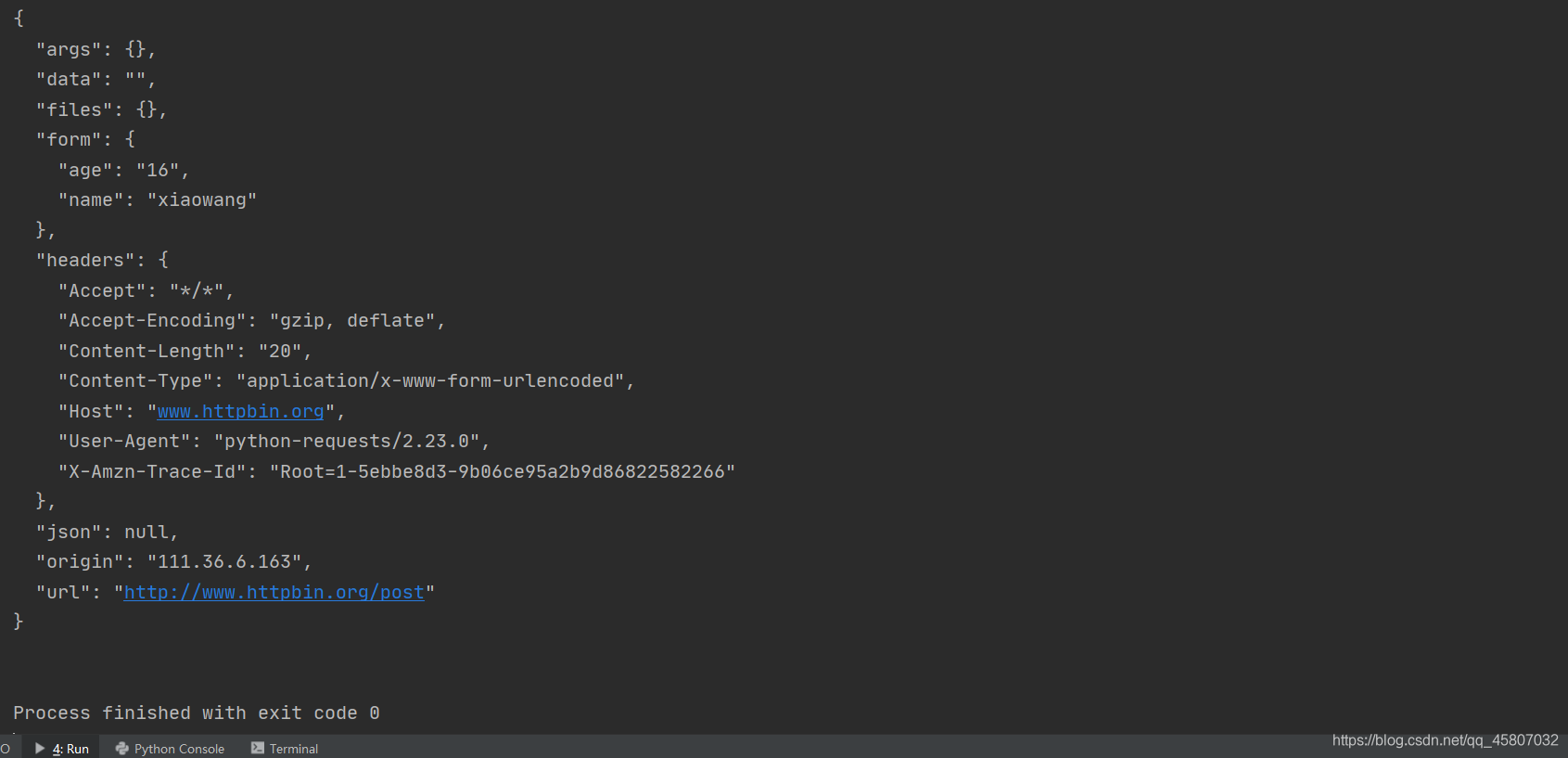
import requests
url='http://www.httpbin.org/post'
data = {
'name':'xiaowang',
'age':'16'
}
response = requests.post(url,data=data)
print(response.text)
运行结果如下,可见提交的数据存放在了form中。
3.3 requests.put()
向HTML网页提交PUT请求的方法 。
3.4 requests.head()
获取HTML网页头信息的方法。
3.5 requests.patch()
向HTML网页提交局部修改请求。
3.6 requests.delete()
向HTML页面提交删除请求。

4. requests库的异常
- requests.HTTPError:HTTP网页状态异常,正常情况下状态码是200
- requests.Timeout:请求超时异常(从发起url请求到获得内容的整个时间段)
- requests.URLRequired:URL缺失异常
- requests.ConnectTimeout:仅指连接远程服务器超时异常
- requests.ConnectionError:网络连接错误异常 ,如DNS查询失败、 拒绝连接等
- requests.TooManyRedirects:超过最大重定向次数, 产生重定向异常。

5. 维持会话
5.1为什么要维持会话?
正常情况下,如果直接使用get等请求方法多次请求网页,对方不会认可这是一次会话,也就是说,每一次请求都是一个新的会话。在需要登录操作时,你需要多次爬取其网站信息,这时就会产生错误(第一次请求登录了,但第二次请求没有登录)。这时维持会话就起到相应作用了。requests库提供的session对象可以帮我们简便的维持一个会话,而不用担心其他问题。下面我们就来看一下session的作用吧!
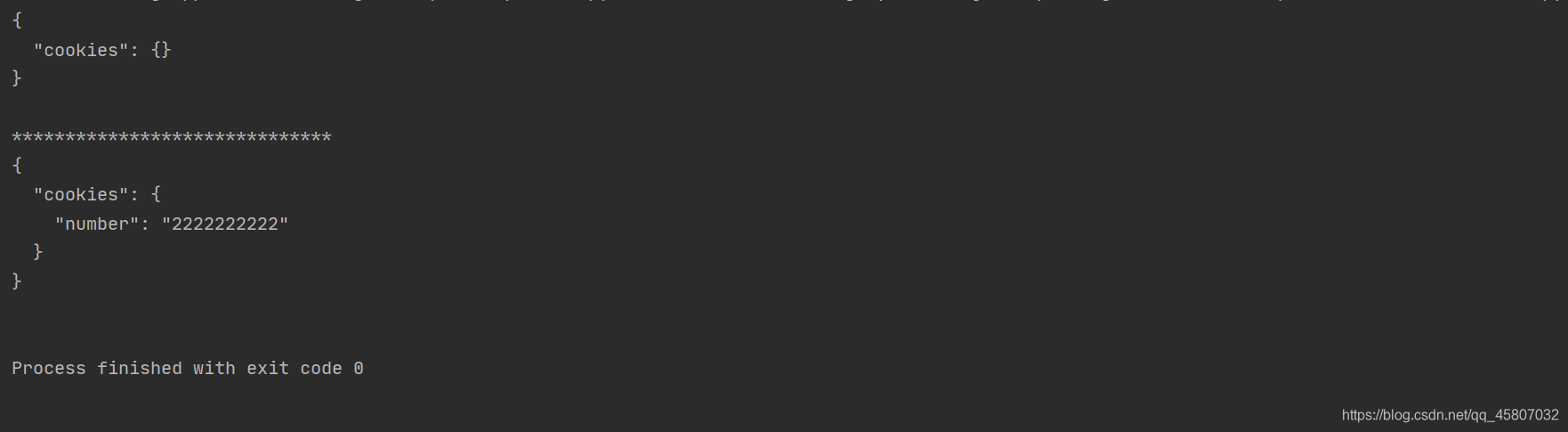
import requests
# 普通的多次的登录并不会保存相同的cookies
r1 = requests.get("http://www.httpbin.org/cookies/set/number/11111111111")
r2 = requests.get("http://www.httpbin.org/cookies")
print(r2.text)
print("*"*30)
s = requests.session() # 建立会话对象
s.get("http://www.httpbin.org/cookies/set/number/2222222222") # 通过会话对象进行请求操作,设置cookies
response = s.get("http://www.httpbin.org/cookies") # 同一会话再次请求,查询cookies
print(response.text)
运行结果如下。可以发现,普通情况下,会话r1 进行设置本次会话的cookies,但再次请求时cookies不再相同,说明不再是同一会话;维持会话状态下两次的cookies相同,说明这是同一会话。因此,session常用于带有模拟登录的操作。
6. SSL证书验证
一些加密网站需要被官方CA机构信任,如果没有被认证,就会出现证书验证错误的结果。
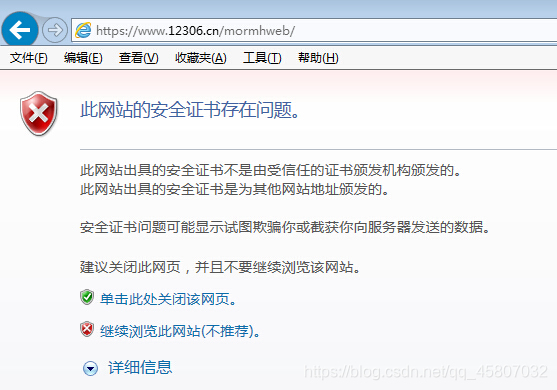
当爬取时,如果我们直接请求网站,就会抛出异常SSLError,表示证书验证错误。不用担心,requests库已经为我们想到了解决办法。它提供了一个参数verify,默认情况下是True(不检查证书),我们只需将其设置成False即可。但此时我们会收到一个警告,我们可以通过设置忽略警告的方式来处理。具体如下:
import requests
from requests.packages import urllib3
urllib3.disable_warnings() # 忽视警告
response = requests.get("https://www.12306.cn")
print(response.status_code)
这时,再次的爬取网站就可以正常访问了。

7. 代理设置
7.1 什么是代理?
在实际爬取过程中,服务器会检测某个ip的访问频率,由于爬虫爬取频率过快,一些网站就会出现验证提示,或直接封ip,更或者不动声色的返回错误的数据信息。为解决这种问题,我们需要来伪装自己的ip,这时就需要代理了。代理实际上就是代理服务器,他的功能是代理用户去取得网络信息。形象的来说,就是一个代理人。利用代理人替我们来爬取数据,这样就可以解决问题了。

7.2 设置代理
强大的requests为我们设置了一个参数proxies,用来设置代理。参数proxies是一个字典,键名是协议,键值是ip和端口。具体如下(此处的代理不是真正的):
import requests
proxies = {
"http":"127.0.0.1:1314",
"https":"127.0.0.1:2345"
}
response = requests.get(url,proxies)
print(response.text)
如果代理服务器需要用户名和密码,则可以设置如下:
proxies = {
"http":"username:[email protected]:1314",
"https":"username:[email protected]:2345"
8. 超时设置
我们请求父服务器并得到其响应需要一定的时间。我们有时会等待特别长的时间。因此为了防止不能及时得到服务器的响应,requests库提供了一个超时设置的参数timeout。在规定的时间内得不到响应就会抛出异常ConnectTimeout。因此我们可以通过设置捕获异常来进行处理。
import requests
response = requests.get("http://www.baidu.com",timeout=0.01)
print(response)

9. 身份验证
在访问网络时,我们可能会面临身份验证的问题。这时,直接登录就会出现异常。requests库的auth参数为我们提供了登录方法。auth是一个元组,元素1为用户名,元素2为密码。
import requests
auth = ("username","password") # 元组,用户名,密码
response = requests.get("http://www.baidu.com",auth=auth) # 此url请更换
print(response.status_code)
10. Request方法
我们可以将请求表示为**数据结构**,将各个参数都通过一个request来表示,这样我们就可以将请求当做**独立的对象**来看待,这在后续进行**队列调度**时会非常方便。如下实例:
import requests
url = "http://www.httpbin.org/post"
data={
"name":"xiaoming",
"age":"18"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
s = requests.Session()
request = requests.Request("post",url,data=data,headers=headers)
prepared = s.prepare_request(request)
response = s.send(prepared)
print(response.text)
从今天起,不定期发布有关爬虫的文章,内容略有不足,还请各位大牛多多指教,见谅!
