Requests库的详细安装过程
对于初学Python爬虫小白,认识和使用requests库是第一步,requests库包含了网页爬取
的常用方法。下面开始安装requests库。
1.检查是否安装过requests库:Windows加r打开cmd命令提示符,输入pip install requests,
回车查看。
2.若回车后显示空,则需要下载安装tar包。网站链接:https://pypi.org/project/pip/#files。
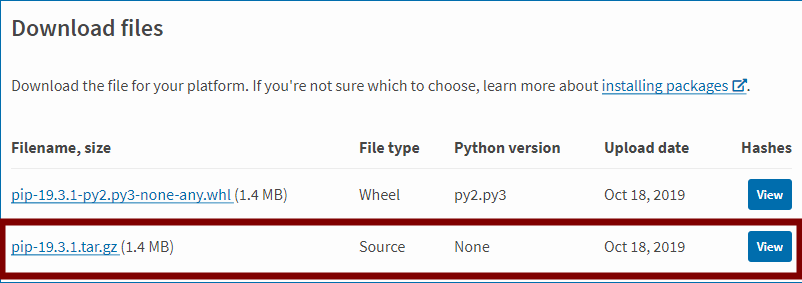
3.解压下载的tar包,将pip文件放在Python安装目录下的lib包内。
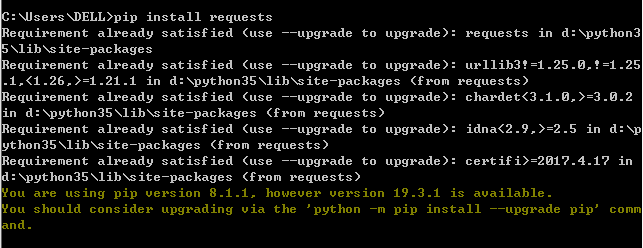
4.打开cmd命令管理器,输入pip install requests,显示如下图则安装成功。
扫描二维码关注公众号,回复:
7798431 查看本文章

Python对于其他库函数的安装类似如上方法。例如BeautifulSoup4的安装,只需按上面步骤
即可,命令行输入pip install beautifulsoup4。
requests库的常用方法

get()方法
get()方法构造一个请求服务器的request对象。
requests.get()
r = requests.get(url)
r是返回的一个包含服务器资源的对象
response对象的属性

r.status_code返回的要么是200,要么是404或者其他,只有返回200时是表示连接成功。
r.text返回输出网页的内容,解决乱码问题。
r.encoding返回网页的编码,如果header不存在charset,则默认返回ISO-8859-1。
r.apparent_encoding,从文本内容分析出网页的编码方式。实际上更加全面。
Requests库的异常
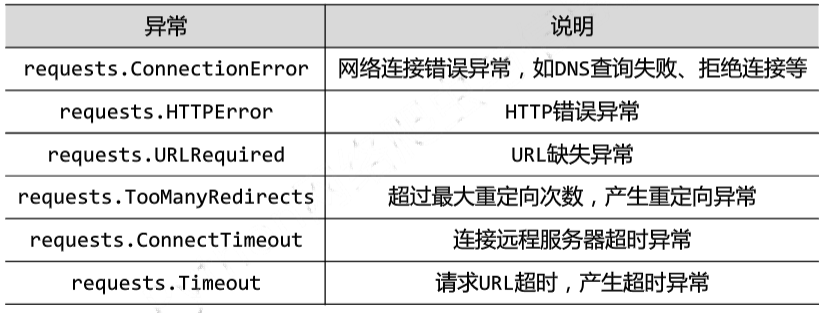
Response的异常
返回状态不是200时,产生一个requests.HTTPError的异常。