一,Request库简介
1, 安装
pip install requests
r.status_code返回状态码,为200时说明访问状态正确
>>> import requests
>>> r = requests.get("https://www.baidu.com/")
>>> r.status_code
200
>>> r.encoding = 'utf-8' #转换为utf-8编码
>>> type(r)
<class 'requests.models.Response'>
2,Requests库7个主要方法
HTTP协议和requests库的这7个方法功能一致
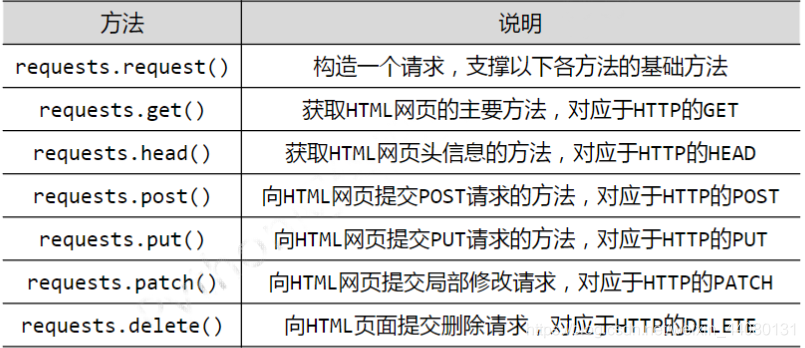
(1)request.get()函数:

参数说明:

response对象属性:

编码:

(2)requests.head():
>>> import requests
>>> r = requests.get("https://www.baidu.com/")
>>> r.status_code
200
>>> r.headers
{
'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform',
'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html',
'Date': 'Wed, 20 Jan 2021 12:31:06 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:24:45
GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-
age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
>>> r = requests.head("https://www.baidu.com/")
>>> r.status_code
200
>>> r.headers
{
'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform',
'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html',
'Date': 'Wed, 20 Jan 2021 12:32:10 GMT', 'Last-Modified': 'Mon, 13 Jun 2016 02:50:35
GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18'}
>>>
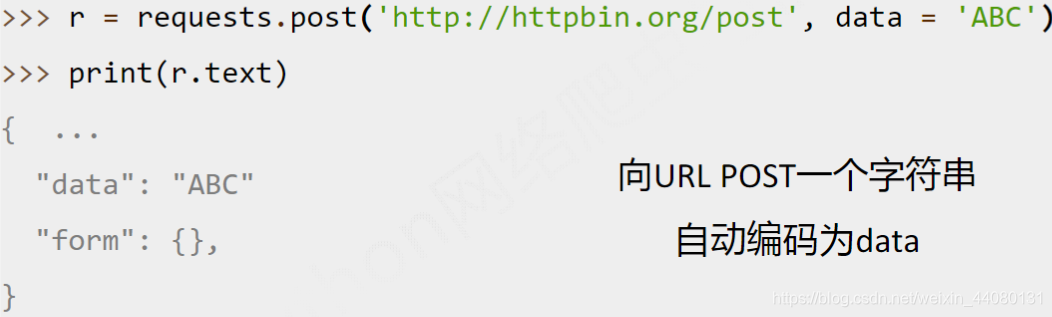
(3) requests.post()函数:

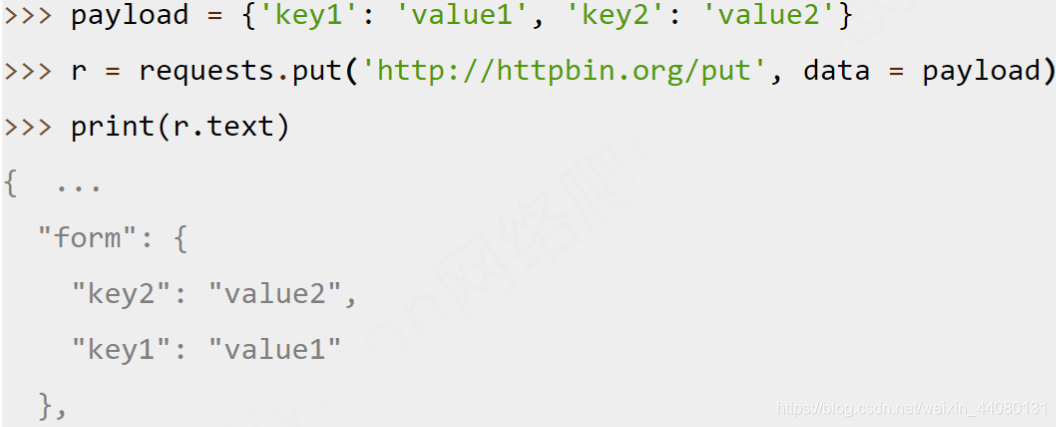
(3) requests.put()函数:
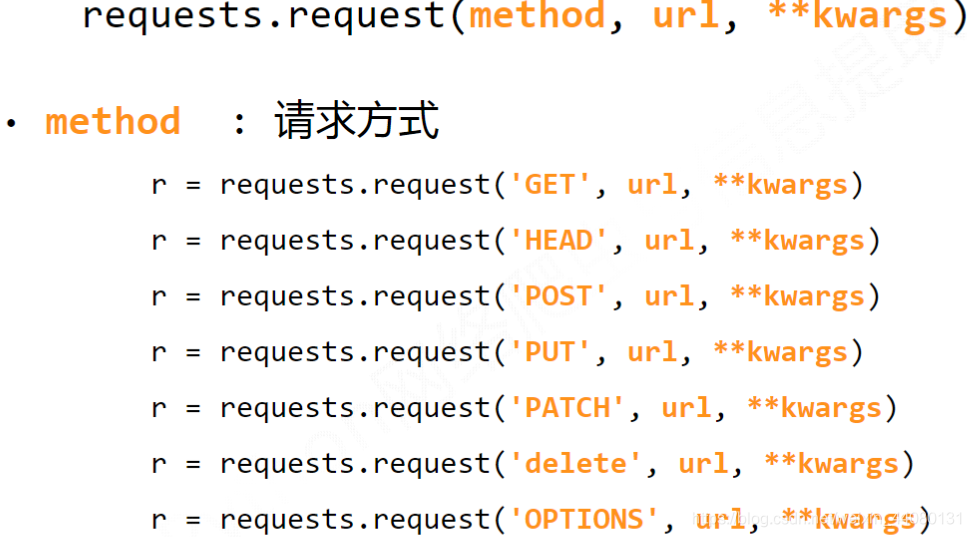
(4) request()方法中传入请求参数:


- 模拟浏览器:

- 隐藏爬虫的源ip地址:

其实最常用的是get()和head()方法,head方法一般在爬取页面内容太多是使用。
其他的因为涉及到对服务器数据进行修改会受限制。
二, 通用框架
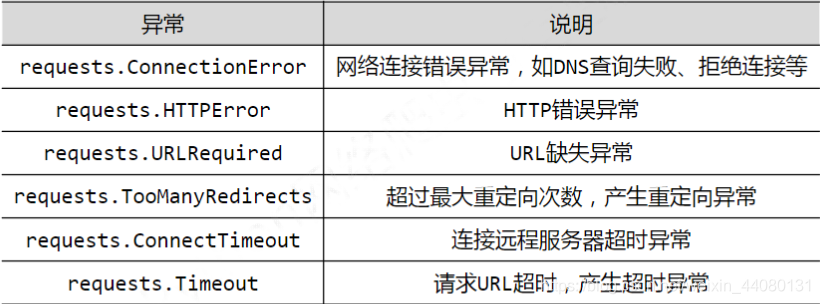
网络访问并非每次都能成功,如果请求url出现异常需要给出提示,requests库异常类型:
常用的访问框架为:
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()#如果状态码不为200,引发HTTPError异常
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="https://www.baidu.com"
print(getHTMLText(url))
运行输出:
============================ RESTART: D:/爬虫/基本框架.py ============================
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type
content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta
content=always name=referrer><link rel=stylesheet type=text/css
href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css>
<title>百度一下,你就知道</title></head> <body link=#0000cc> ...</body> </html>
三, Robots协议
网络爬虫可爬取的内容会有约束,可能面临法律、隐私等风险。
Robots协议:robots exclusion standard:

京东案例:

基本建议:
