#requests库的学习与应用实例
导学
- Request:自动爬取HTML页面自动网络请求提交
- robots协议:网络爬虫排除标准
- Projects:实战项目
单元1:Requests库入门
Requests库安装:pip install requests
get() head()最常用

get()方法
import requests
r = requests.get("url")
#get->request:构造一个向服务器请求的资源的Requests对象
#response->r:返回一个包含服务器资源的的Response对象(包含爬虫返回的内容)
#requests.get(url,params=None,**kwargs)
#url:拟获取页面的url链接
#params:url中的额外参数,字典或字节流格数,可选
#**kwargs:12个控制访问的参数
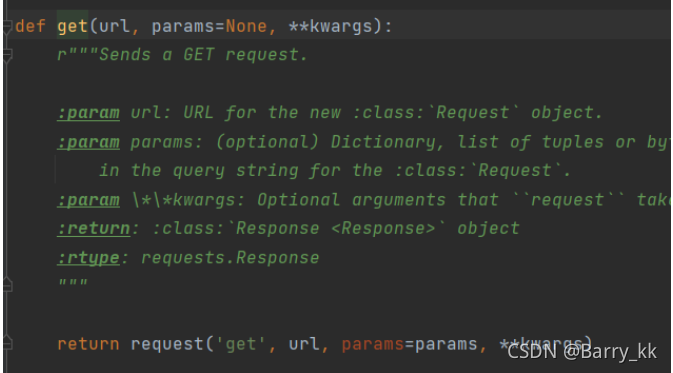
由此可见requests库只有一个request方法,其他方法都是调用request方法
#Requests库的两个重要对象 Response-Request
#Response的属性(包含爬虫返回的内容)
#404或其他:错误或异常
#200:可查看相应属性值

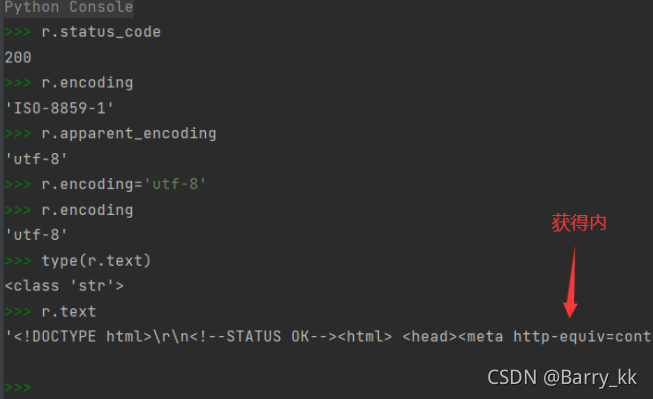
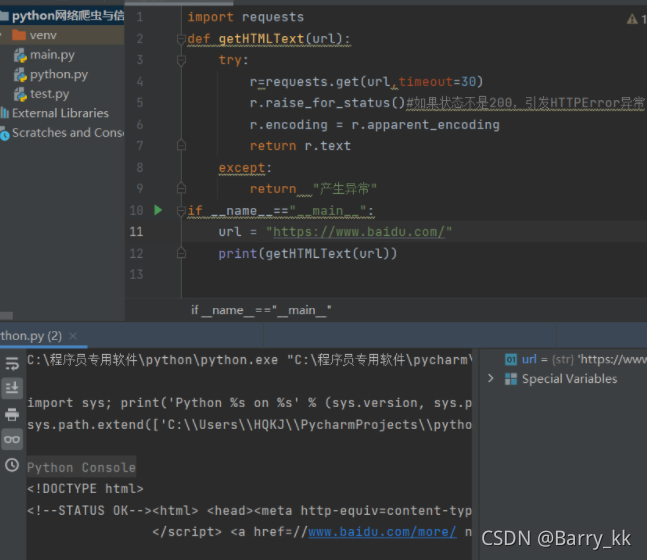
爬取网页的通用代码框架


#爬取网页的通用代码框架
#网络链接有风险,异常处理很重要
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url = "https://www.baidu.ccom/"
print(getHTMLText(url))
返回的正确结果
-
`` if _name_ == " _main_":
扫描二维码关注公众号,回复: 15378720 查看本文章
printf(“11”)语句的作用: ``
一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行。因此if name == ‘main’: 的作用就是控制这两种情况执行代码的过程,在if name == ‘main’: 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的。
HTTP协议及Requests库方法

HTTP协议:超文本传输协议。
http是一个基于“请求与响应”模式的,无状态的应用层协议。
http一般采用url作为定位网络资源的标识。
url格式 http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80
path:请求资源的路径
http://www.bit.edu.cn
HTTP URL的理解
url是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。




#Requests库的head()方法
import requests
r=requests.head("https://www.baidu.com/")
r.headers
#Requests库的post()方法
payload = {
'key1':'value1'}
r = requests.post('http://httpbin.org/post',data = payload)
print(r.text)
```这是结果
{
"args": {
},
"data": "",
"files": {
},
"form": {
"key1": "value1"
}
```
#Requests库的put()方法
payload = {
'k1':'v1','k2':'v2'}
r = requests.put('http://httpbin.org/put',data=payload)
print(r.text)
```这是结果一部分
{
"args": {
},
"data": "",
"files": {
},
"form": {
"k1": "v1",
"k2": "v2"
},
```
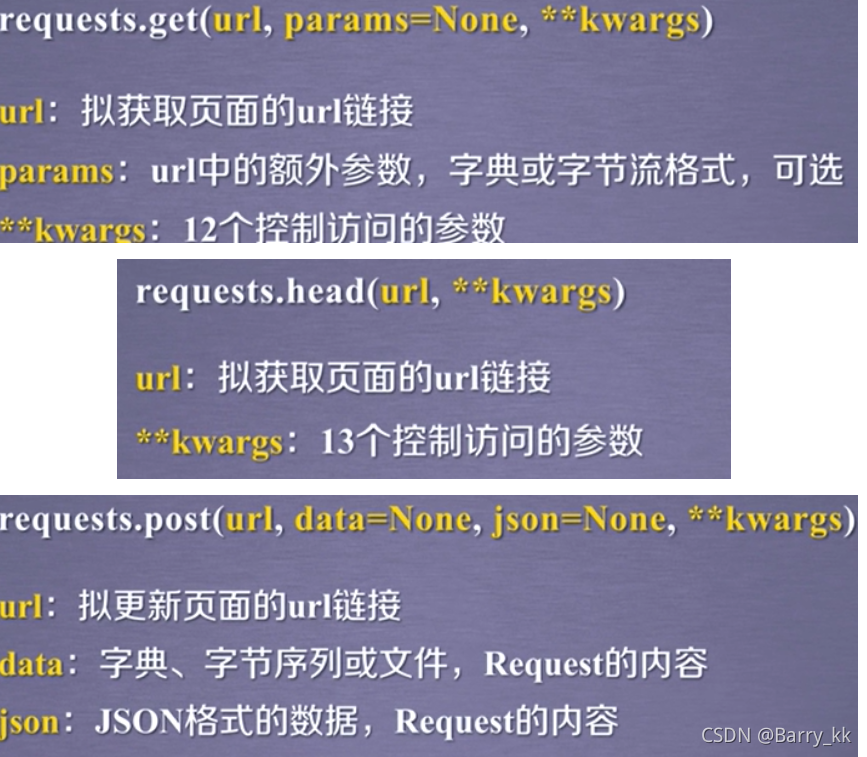
Requests库主要方法解析
request()方法
#requests.request(method,url,**kwargs)
method:请求方式,对应get/put/post等七种
r = request.request('GET',url,**kwargs)#eg
url:拟获取页面的url链接
**kwargs:控制访问的参数,共13个
params:字典或字节序列,作为参数增加到url中
kv = {
'k1':'v1','k2':'v2'}
r = requests.request('GET','http://python123.io/ws',params=kv)
print(r.url)
#结果 https://python123.io/ws?k1=v1&k2=v2
data:字典,字节序列或文件对象,作为Request的内容
kv = {
'k1':'v1','k2':'v2'}
r = requests.request('POST','http://python123.io/ws',data=kv)
json:JSON格式的数据,作为Ruquests的内容
kv = {
'k1':'v1','k2':'v2'}
r = requests.request('POST','http://python123.io/ws',json=kv)
headers:字典,HTTP定制头
hd = {
'user-agent':'chrome/10'}
r = requests.request('POST','http://python123.io/ws',headers=hd)
cookies:字典或CookieJar,Request中的cookie
auth:元组,支持HTTP认证功能
files:字典类型,传输文件
fs = {
'file':open('data.xls','rb')}
r=requests.request('POST','http://python123.io/ws',file=fs)
timeout:设定超时时间,秒为单位
r=requests.request('GET','http://python123.io/ws',timeout=10)
proxies:字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects:True/False,默认为True,重定向开关
stream:True/False,默认为True,获得内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径

单元2:网络爬虫的“盗亦有道”
网络爬虫引发的问题

- 法律风险
- 泄露隐私
- 骚扰问题
网络爬虫的限制
- 来源审查:判断user-agent进行限制
- 发布公告:robots协议
Robots协议(网络爬虫排除标准)
作用:网站告知网络爬虫哪些页面可以抓取,那些不行
协议:在网站根目录下的robots.txt的文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RqWUh17q-1637850721313)(https://www.jd.com/robots.txt)]
语法:
User-agent:*
Disallow:/
Robots协议的遵守方式
网络爬虫:自动或人工识别robots.txt,再进行内容爬取。
约束性:Robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险。
类人行为可不参考Robots协议
单元3:Requests库网络爬虫实战(5个实例)
实例一京东商品页面的爬取
import requests
try:
#https://item.jd.com/100021007462.html
r = requests.get("https://item.jd.com/100021007462.html/")
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print('爬取失败')
结果

实例二亚马逊商品页面的爬取
与访问京东商品不同,我们需要通过headers字段让我们的代码模拟浏览器向亚马逊提供HTTP请求
#正确源代码
import requests
try:
url = "https://www.amazon.cn/dp/B0814XNDPM/ref=s9_acsd_hps_bw_c2_x_2_i?pf_rd_m=A1U5RCOVU0NYF2&pf_rd_s=merchandised-search-2&pf_rd_r=TR3JA9FYNTNPF2PZ66V3&pf_rd_t=101&pf_rd_p=7235aeb5-a996-42a4-a46a-257db647554a&pf_rd_i=2032713071"
kv = {
"user-agent":"Mozilla/5.0"}
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[6000:10000])
except:
print('爬取失败')

爬虫忠实的告诉了亚马逊他写的是python-requests,亚马逊来源审查,使这样的爬虫发生错误。
我们可以更改头部信息headers,模拟浏览器向亚马逊发送请求,首先构造键值对重新定义user-agent内容,调用get函数进行修改。

实例三百度360搜索关键词提交
搜索引擎关键词提交接口
百度:http://www.baidu.com/s?wd=keyword
360:http://www.so.com/s?q=keyword
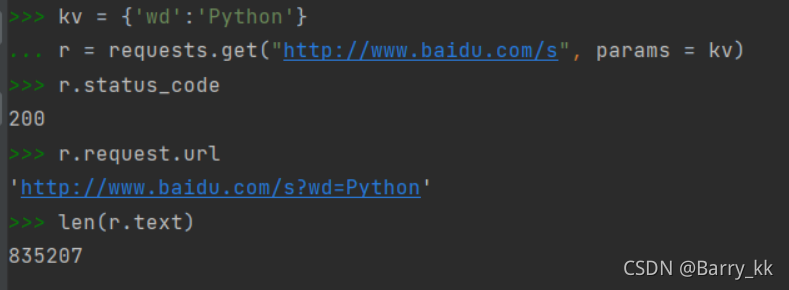
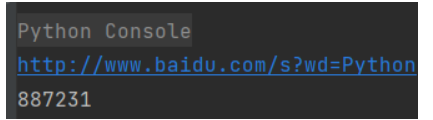
import requests
keyword = 'Python'
try:
kv = {
'wd':keyword}
r = requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
实例四网络图片的爬取与存储(视频)
网络图片链接的格式:
http://www.example.com/picture.jpg
import requests
import os
url = "http://cj.jj20.com/2020/down.html?picurl=/up/allimg/tp05/19100120461512E-0.jpg"
root = "C://程序员专用软件//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
实例五IP地址归属地的自动查询
https://www.ip138.com/ #查询ip地址
https://www.ip138.com/iplookup.asp?ip=112.224.74.158&action=2 #这种形式的链接
import requests
url = "http://m.ip138.com/ip.asp?ip="
#try:
r = requests.get(url+'202.204.80.112')
r.raise_for_status()
# r.encoding = r.apparent_encoding
# print(r.text[-500:])
#except:
print("爬取失败")
