版权声明:本文为博主原创文章,未经博主允许不得转载。@ceezyyy11 https://blog.csdn.net/ceezyyy11/article/details/86717906
初探Python网络爬虫:Requests库
首先打开cmd,输入pip install requests,下载requests库
>>> import requests
>>> r=requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.encoding='utf-8'
>>> r.text
1. r=requests.get(URL)构造一个向服务器请求资源的Request对象,并返回一个包含服务器资源的Response对象
2. r.status_code:HTTP请求返回的状态,200表示成功,404表示失败
3. r.text:URL对应的页面内容
4. r.encoding:网页的编码方式
5. r.content:HTTP相应内容的二进制格式
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=300)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return '产生异常'
if __name__=="__main__":
url="http://www.baidu.com"
#url可以为任意网址(科学上网....emmmmm')
print(getHTMLText(url))
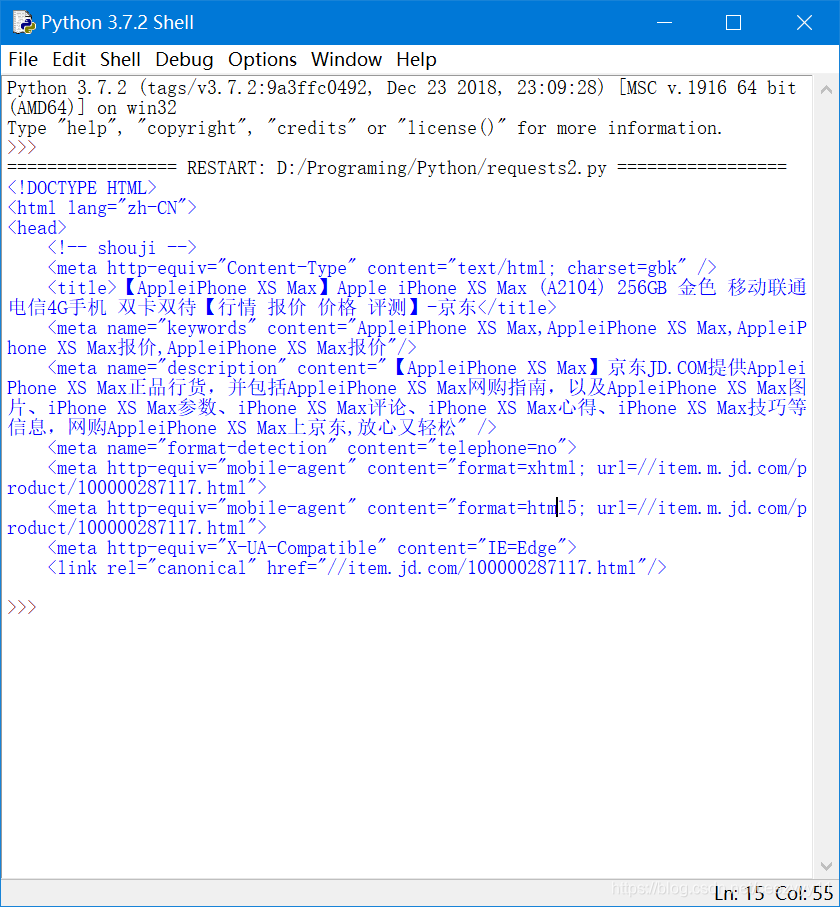
实例1:爬取京东商品信息
- 我们先上京东官网,找一件商品信息,此文以iPhone XS Max为例:

代码
import requests
url="https://item.jd.com/100000287117.html"
try:
r=requests.get(url)
r.raise_for_status
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
运行结果
实例2:百度搜索关键词提交
import requests
keyword="Python" #搜索关键词
try:
kv={'wd':keyword} #键值对
r=requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
r.encoding=r.apparent_encoding
print(type(r))
except:
print("爬取失败")
运行截图

requests.get(url,params=None,**kwargs)
kwargs:控制访问的参数,均为可选项
params:字典或字节序列,作为参数增加到URL中
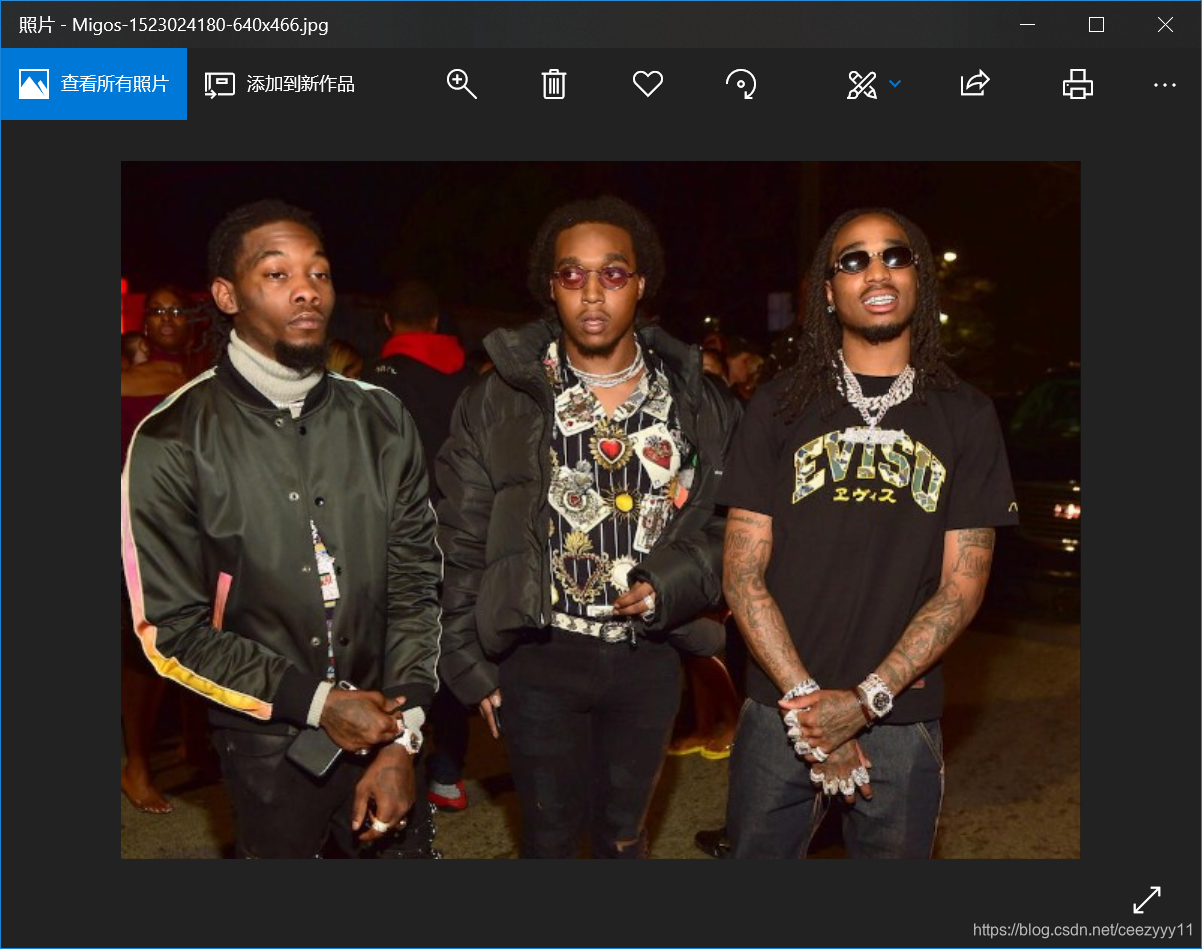
实例3:从网上爬取图片
从网上找一张自己喜欢的图片,右键复制图片地址。
利用Python爬取图片并保存到当地。
import requests
import os
url="http://thesource.com/wp-content/uploads/2018/04/Migos-1523024180-640x466.jpg"
root="D://pics//"
path=root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
注释:
-
os 模块提供了非常丰富的方法用来处理文件和目录
详情请看:
Python.docs
Python OS 文件/目录方法 -
检查某个路径(前提是你不关心其指向的是文件还是文件夹)是否存在的另一种方法,是使用os.path.exists
-
os.mkdir(root):创建一个目录
-
with…as…语法具体请看:
理解Python中的with…as…语法-CSDN -
open/文件操作
f=open(’/tmp/hello’,‘w’)
#open(路径+文件名,读写模式)
#读写模式:r只读,r+读写,w新建(会覆盖原有文件),a追加,b二进制文件.常用模式