版权声明:关注微信公众号:摸鱼科技资讯,联系我们 https://blog.csdn.net/qq_36949176/article/details/83715574
python网络爬虫与信息提取
学习目录:
the website is the API
Requests:自动爬取HTML页面自动网络请求提交
robots.txt:网络爬虫排除标准
Beautiful Soup:解析HTML页面
正则表达式详解,提取页面关键信息Re
Scrapy*:网络爬虫原理介绍、专业爬虫框架介绍
python IDE工具
文本类:IDLE(自带、默认、常用、入门) 、Sublime Text(专门为程序员开发的第三方专用编程工具、专业编程推荐)
集成工具类IDE:Wing(专业、收费、调试功能、版本控制,多人同步开发)、VS&PTVS(微软)、Eclipse&PyDev(配置比较繁琐)、PyCharm(社区免费、简单、集成度高、好用)、Canopy、Anaconda & Spyder(科学计算)
Requests库
Requests库详细链接:http://www.python-requests.org/en/master/
win+R键进入运行窗口,输入cmd,然后在cmd命令提示符窗口输入
pip install Requests即可安装成功,如果出现网络问题安装失败,请参考摸鱼君之前的文章:https://blog.csdn.net/qq_36949176/article/details/82939676 ,pip不能安装,找不到指令,请参考python环境变量的配置:https://blog.csdn.net/qq_36949176/article/details/83715807
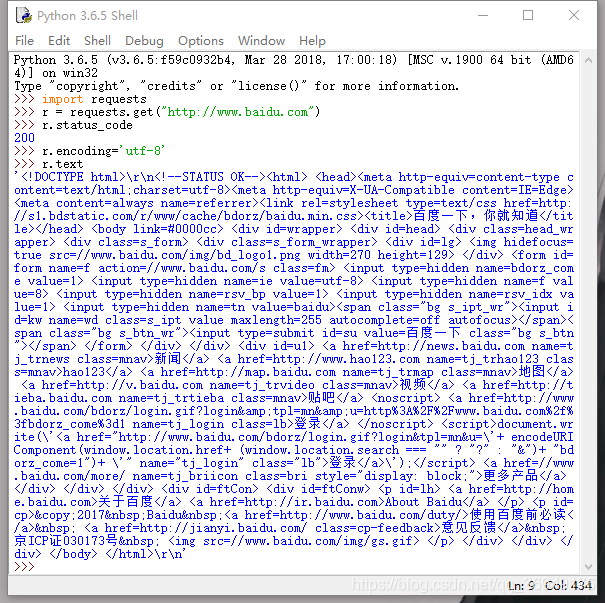
安装好requests包之后,现在我们打开python idle ,写个抓取百度网页程序,试一试requests库的使用,程序如下:
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.encoding='utf-8'
>>> r.text运行结果如图所示: