一.windows平台下requests的安装
1.win+R,输入cmd,打开命令行窗口,输入命令:pip install requests ,即可自动安装库成功
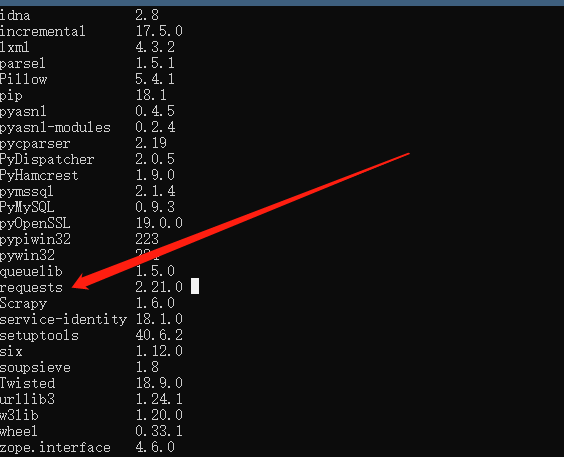
2.输入命令:pip list,即可查看所有已安装的模块,可以看到requests已成功安装
二.利用Requests写一个贴吧爬虫
1.首先导入模块:import requesets
2.写一个类,__init__方法需要一个参数tieba_name,来表示要爬取的贴吧名字,同时为该类的对象设置属性self.url_temp和self.hearders,他们分别表示,要爬取的贴吧网站和请求头
3.方法说明:
get_url_list(self):该方法生成要爬取的贴吧的每一页的网站列表,因为贴吧每增加一页,网页参数pn加50(第一页为0),因此用列表推导式
[self.url_temp.format(i * 50) for i in range(1000)]生成列表;
parse_url(self, url):传入一个要爬去的网页,获取其数据流并解码,使用requests.get()方法,该方法用于请求一个网页,这里传递给它两个参数,一个是要爬去的网站,另一个是请求头;
save_html(self, html_str, page_num):用于保存页面内容;
run(self):运行该爬虫对象;
扫描二维码关注公众号,回复:
5825244 查看本文章

4.测试:以下代码中 创建了一个 爬取Python吧的对象,并爬取页面内容。运行结果如下
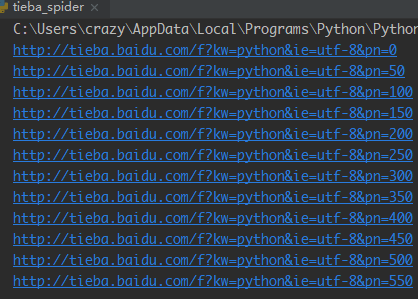
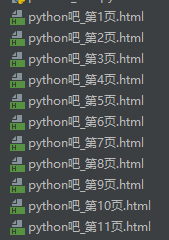
1 import requests 2 3 4 class Tiebaspider: 5 # 构造方法,需要一个参数tieba_name 6 def __init__(self, tieba_name): 7 self.tieba_name = tieba_name 8 self.url_temp = 'http://tieba.baidu.com/f?kw=' + tieba_name + '&ie=utf-8&pn={}' 9 self.hearders = { 10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} 11 12 # 构造url列表 13 def get_url_list(self): 14 return [self.url_temp.format(i * 50) for i in range(1000)] 15 16 # 发送请求,并返回请求的内容。decode()默认用utf-8解码 17 def parse_url(self, url): 18 print(url) 19 response = requests.get(url, headers=self.hearders) 20 return response.content.decode() 21 22 # 保存内容 23 def save_html(self, html_str, page_num): 24 file_path = '{}吧_第{}页.html'.format(self.tieba_name, page_num) 25 # 注意给encodeing传递编码参数,否则会产生无法编码的异常 26 with open(file_path, "w", encoding='utf-8') as f_obj: 27 f_obj.write(html_str) 28 29 # 30 def run(self): 31 # 1.构造url列表 32 url_list = self.get_url_list() 33 # 2.遍历,发送请求, 34 for url in url_list: 35 page_num = url_list.index(url) + 1 # 页码数 36 html_str = self.parse_url(url) # 发送请求,返回内容 37 self.save_html(html_str, page_num) # 保存内容 38 39 40 if __name__ == '__main__': 41 tieba_spider = Tiebaspider('python') 42 tieba_spider.run()