HashMap与HashTable同为Key-Value 键值对存储的集合对象。各有各的优点,各有各的缺点,今天就谈谈他们两者直接的区别。
区别如下:
- HashMap 线程不安全的 执行效率高,HashTable 线程安全的 执行效率低
- HashMap可以存放空的key ,HashTable 不能存放空的key
接下来就围绕这2点来探究一下。
1.HashMap 线程不安全的 执行效率高,HashTable 线程安全的 执行效率低
这一点是因为,HashMap底层的方法均没加锁,没有使用synchronized 来修饰 所以他的执行效率相对会快,而HashTable底层的方法使用synchronized 修饰了,所以他的执行效率相对慢点
HashMap几个关键方法的 代码如下:
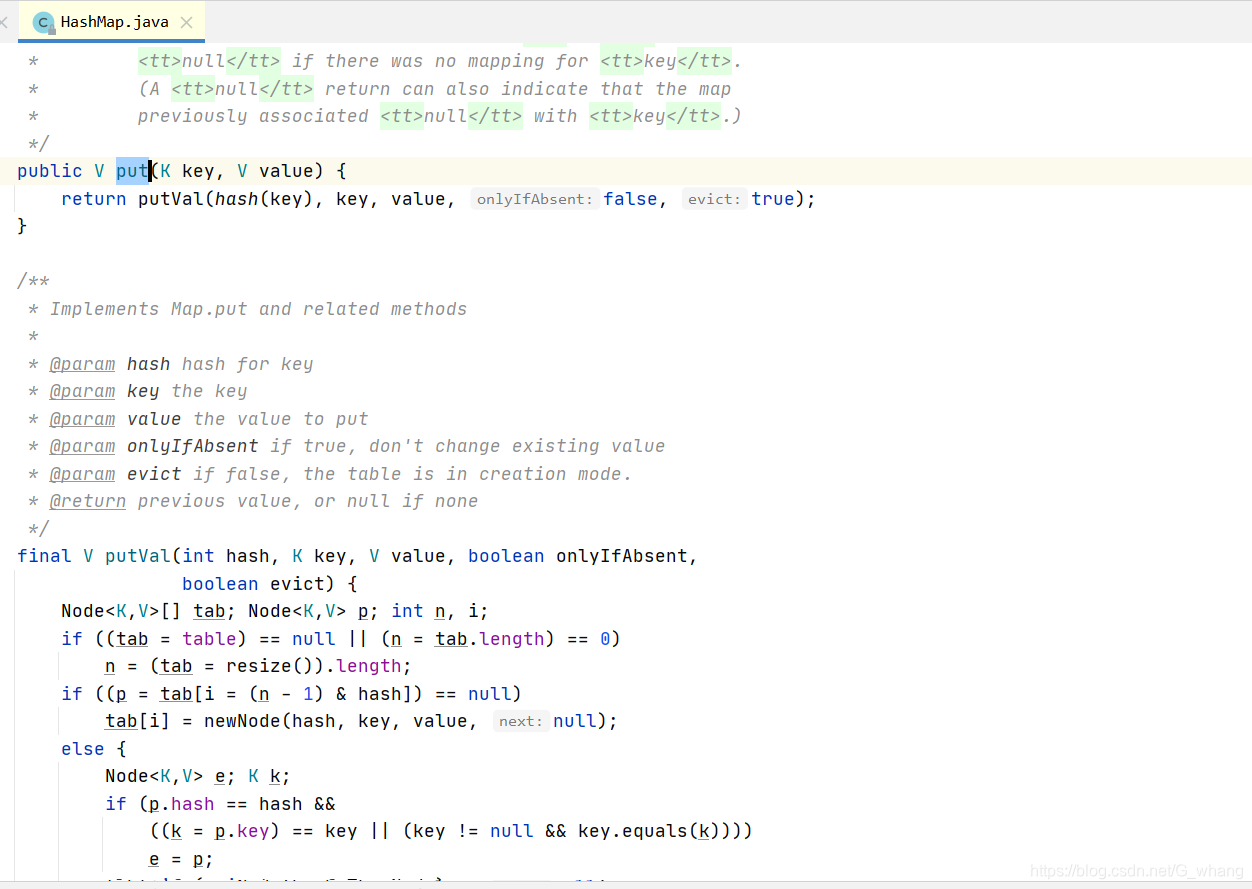
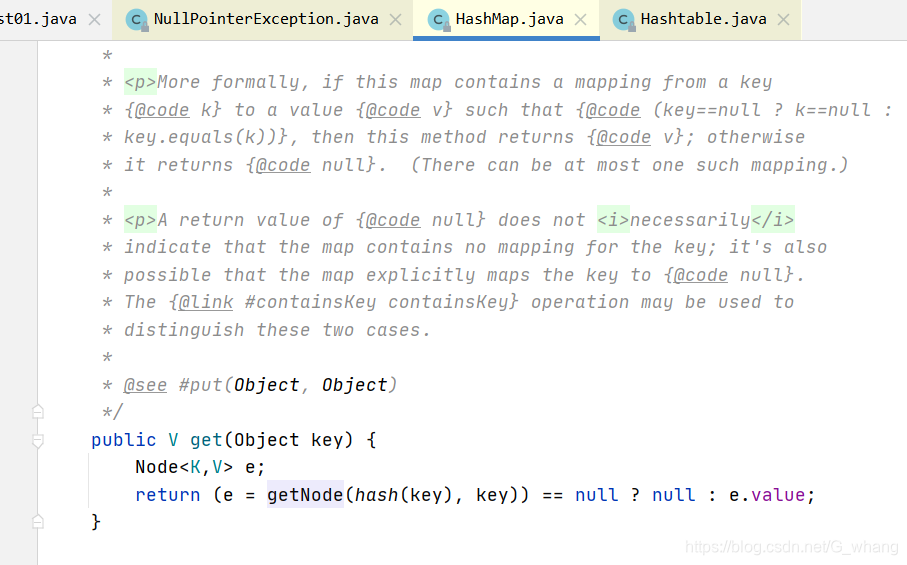


HashTable代码如下:
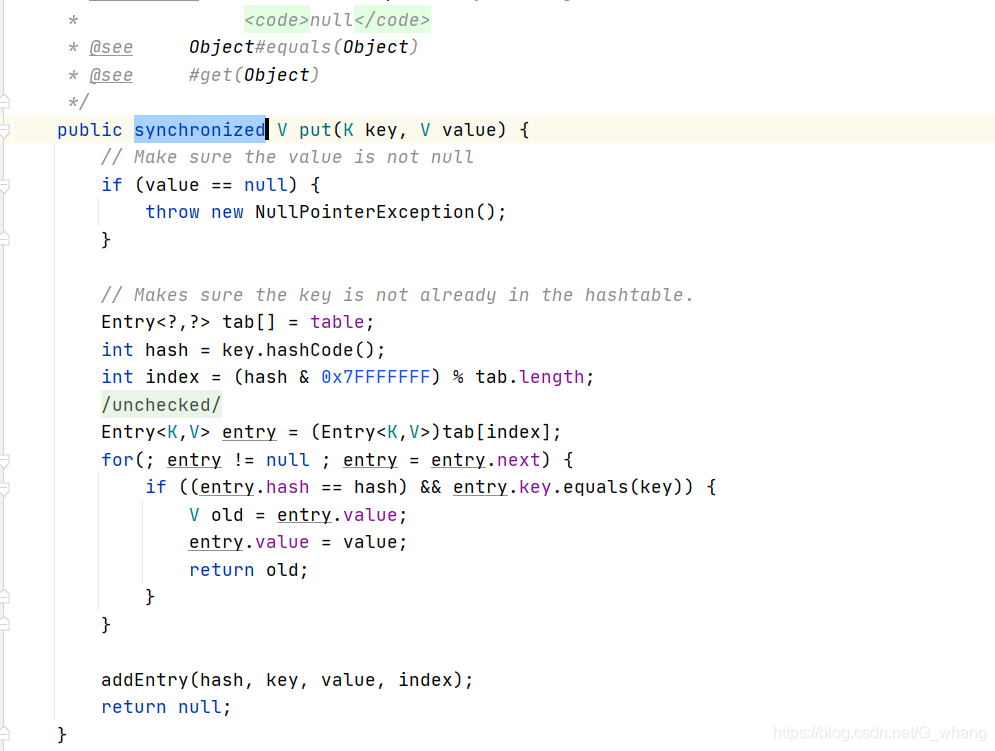

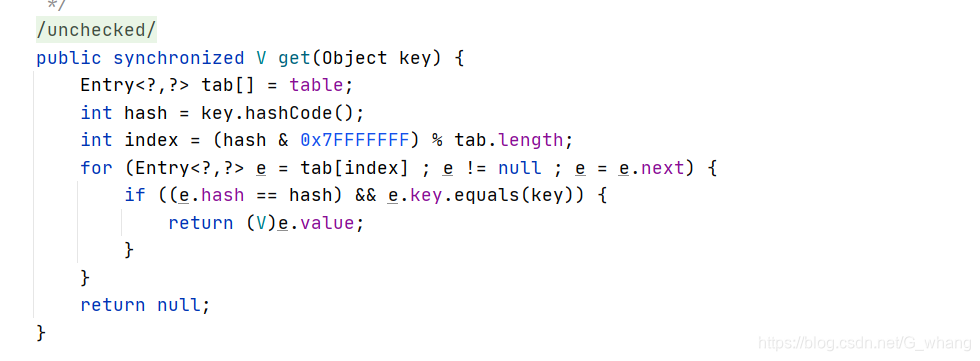
当多个线程同时共享同一个变量做写的操作的时候,就可能发生线程安全问题了,所以在高并发的情况下,HashMap并不是我们应该用的,同时HashTable也不是最优选择,最优的选择应该是ConcurrentHashMap 它主要采用的分段锁的原理 和 CAS无锁(乐观锁)
想深入理解的话可查看程序员小灰这篇博客
HashMap可以存放空的key ,HashTable 不能存放空的key
这个可查看JDK1.7的代码,因为JDK1.7比较容易看懂
先看HashMap的方法
// HashMap的put方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
// key为null调用putForNullKey(value)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
当HashMap的put方法,第二个判断就是key为null的判断后进入putForNullKey(V value)这个方法
可以看到,前面那个for循环,是在talbe[0]链表中查找key为null的元素,如果找到,则将value重新赋值给这个元素的value,并返回原来的value。
如果上面for循环没找到则将这个元素添加到talbe[0]链表的表头。
HashTable确没做这个处理,他是直接拿Key来计算hashCode值的,这个时候,如果没有拿到key则会报空指针的错误
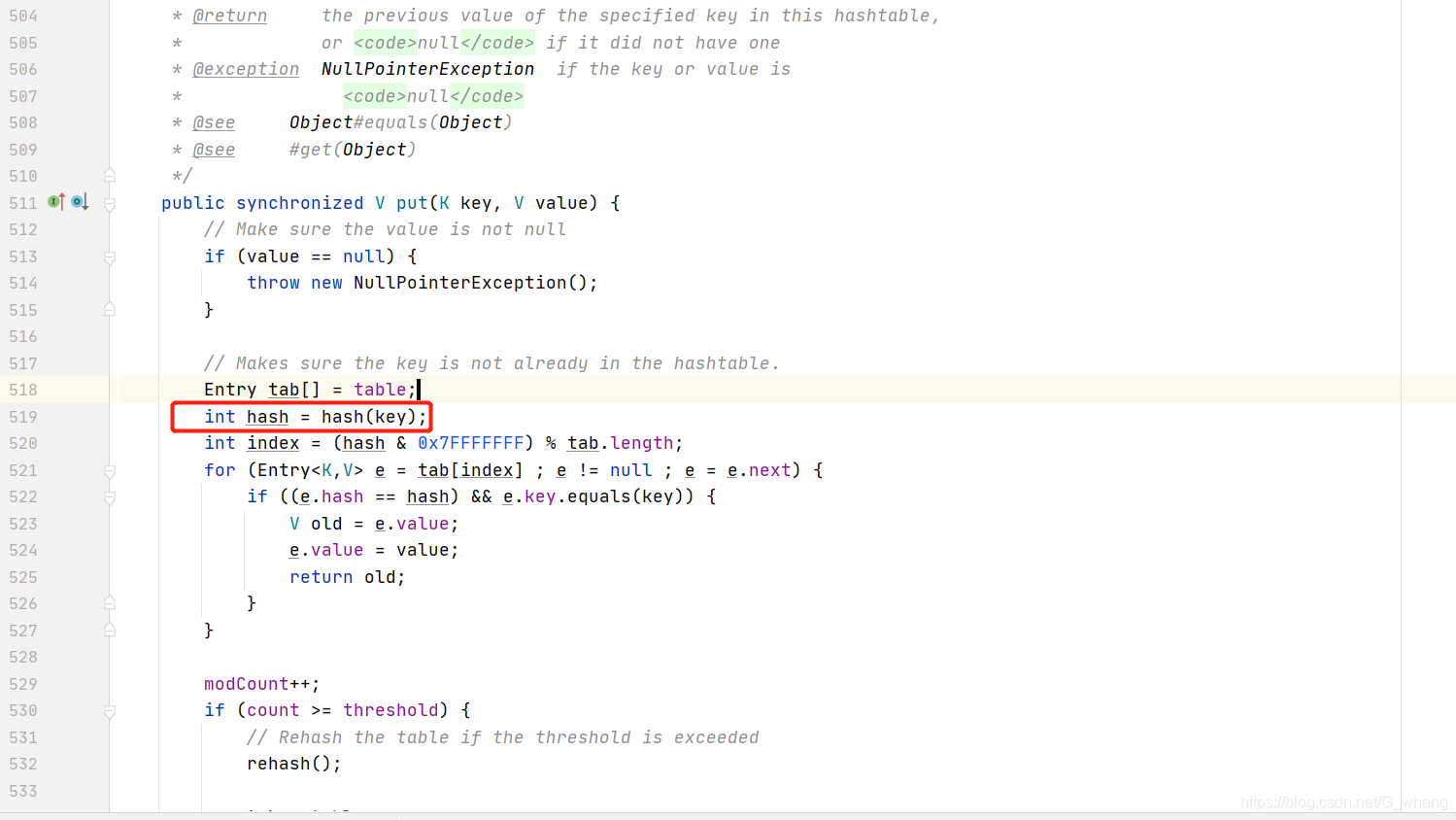
我们本地实际操作一下可以看到已经报了错误
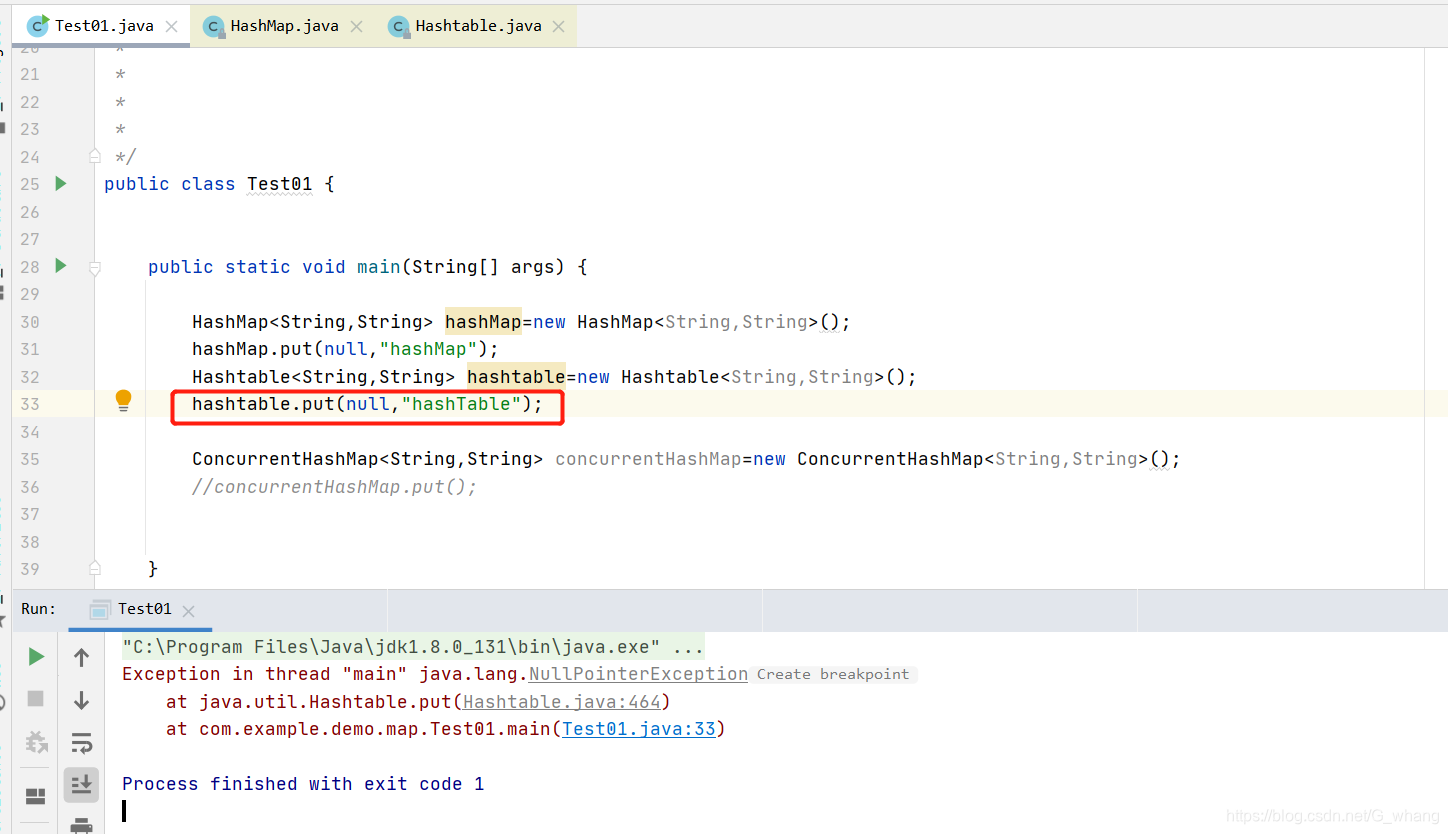
HashMap 如果key是空的,同时没有hashCode那么 值存放在什么位置呢 ?默认存放table[0] 从hashMap1.7的代码可以看出
HashMap 是否可以存放key 为对象?
这个答案也是可以的
因为我们平时使用的泛型String,Object等都是对象
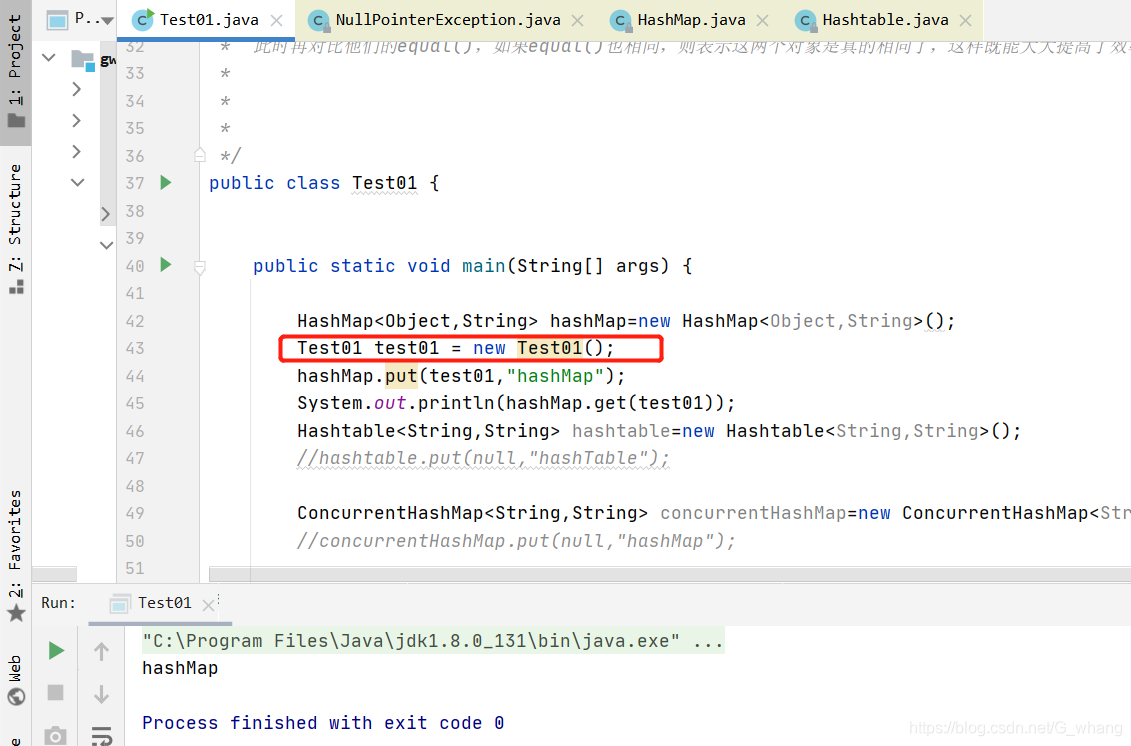
我们把当前类new了一个对象当作了HashMap的key,也正确的取到了value
扩展 hashcode 与equal()有什么区别
hashCode()方法和equal()方法的作用其实一样,在Java里都是用来对比两个对象是否相等一致,那么equal()既然已经能实现对比的功能了,为什么还要hashCode()呢?
因为重写的equal()里一般比较的比较全面比较复杂,这样效率就比较低,而利用hashCode()进行对比,则只要生成一个hash值进行比较就可以了,效率很高,那么hashCode()既然效率这么高为什么还要equal()呢?
因为hashCode()并不是完全可靠,有时候不同的对象他们生成的hashcode也会一样(生成hash值得公式可能存在的问题,类似于hashMap的hash碰撞数组转链表),所以hashCode()只能说是大部分时候可靠,并不是绝对可靠,所以我们可以得出:
-
1.equal()相等的两个对象他们的hashCode()肯定相等,也就是用equal()对比是绝对可靠的。
-
2.hashCode()相等的两个对象他们的equal()不一定相等,也就是hashCode()不是绝对可靠的。
所有对于需要大量并且快速的对比的话如果都用equal()去做显然效率太低,所以解决方式是,每当需要对比的时候,首先用hashCode()去对比,如果hashCode()不一样,则表示这两个对象肯定不相等(也就是不必再用equal()去再对比了),如果hashCode()相同,
此时再对比他们的equal(),如果equal()也相同,则表示这两个对象是真的相同了,这样既能大大提高了效率也保证了对比的绝对正确性!