在面试中HashMap和HashTable的区别是最经常被问到的,总结一下,以供分享学习。
HashMap和HashTable实现的功能基本相同。
1、先从数据结构了解
数据结构中有数组和链表来实现对数据的存储,但两者基本是个极端。
数组
数组存储空间是连续的,占用空间严重,所以空间复杂度比较大。但数组的二分查找时间复杂度小,为O(1)。故其特点:寻址容易,插入和删除困难。
链表
链表和数组相反,其存储是离散的,所以空间复杂度小,但时间复杂度大,为O(N)。故其特点:寻址困难,插入和删除容易。
哈希表
能否有一个数据结构整合它们的优点呢?哈希表出现了。哈希表(HashTable)有很多实现方法,这里解释最常用的方法--拉链法。我们可以理解为“链表的数组”,如图:
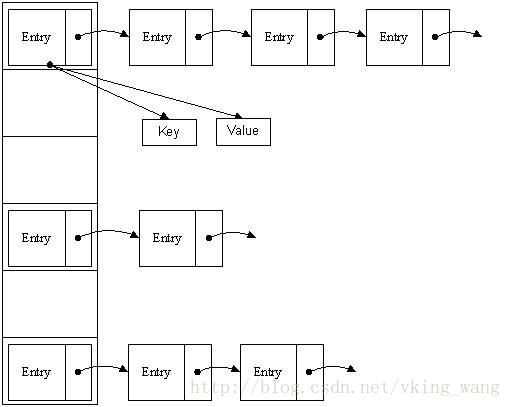
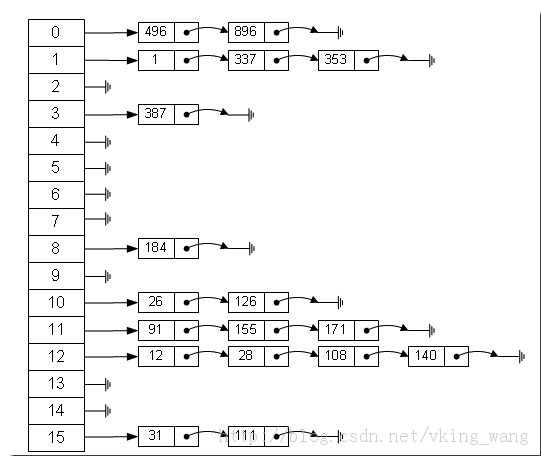
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
2、比较HashMap和HashTable
java为数据结构中的映射定义了一个接口java.util.Map,而HashMap Hashtable就是它的实现类。Map是将键映射到值的对象,一个映射不能包含重复的键;每个键最多只能映射一个值。
Hashtable 与 HashMap主要有3点不同:
1)继承关系不同。
public class Hashtable
extends Dictionary
implements Map, Cloneable, java.io.Serializablepublic class HashMap
extends AbstractMap
implements Map, Cloneable, Serializable由上面的代码可以看出Hashtable是继承陈旧的Dictionary类。在Java 1.2引入Map借口后,Hashtable也改进为可以实现 Map。HashMap是Map接口的一个实现,继承于较新的AbstractMap类。 Hashmap可以算作是Hashtable的升级版本,整体上Hashmap对Hashtable类优化了代码。
2)
在Hashmap中,null可以作为key,这样的key只有一个,但是key所对应的value可以有一个或多个为null。
而在 Hashtable中,null不可以作为key,也不可以作为value。否则会抛出java.lang.NullPointerException。
Hashtable的put方法的源代码如下:
public synchronized Object put(Object key, Object value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
Object old = e.value;
e.value = value;
return old;
}
}
}从这段代码可以看出,在调用Hashtable的put方法时,首先会对put的value是否为空进行判断,如果为空,则会抛出NullPointerException,处理终止。
而HashMap的put方法实现源码:
public Object put(Object key, Object value) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
if (e.hash == hash && eq(k, e.key)) {
Object oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, k, value, i);
return null;
}在put方法的开始,没有像Hashtable那样对value为空进行判断并抛出异常。另外还要注意一个问题,因为Hashmap可以存入null。所以当get()方法返回null值时,既可以表示 Hashmap中没有该key,也可以表示该key所对应的value为null。因此,在Hashmap中不能由get()方法来判断Hashmap中 是否存在某个key, 而应该用containsKey()方法来判断。
3)HashTable是线程同步的,HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力.
当既要同步又要可以让null作为键或者值的时候,一个简便的方法就是利用Collections类的静态的 synchronizedMap()方法,
Map synMap = Collections.synchronizedMap(map);
它创建一个线程安全的Map对象,并把它作为一个封装的对象来返回。
3、总结
有时候会问到为什么编程时都用HashMap而不用HashTable呢?那么综上所述:
Hashmap可以使用null作为key和value,而Hashtable不行。
Hashtable是同步的,Hashmap是异步的。但是,因为在 需要时,Hashmap可以利用Collections类的静态的 synchronizedMap()方法来实现同步。
其次Hashmap的功 能比Hashtable的功能更多,而且它不是基于一个陈旧的类的,所以才有人认为,在各种情况下,Hashmap都优先于Hashtable。