使用朴素贝叶斯进行分类
一、朴素贝叶斯公式如下
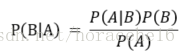
二、朴素贝叶斯分类的正式定义如下
1、设 x={a1,a2,...,am} 为一个待分类项,而每个a为x的一个特征属性。
2、现有已分类的类别集合 C={y1,y2,..,y3}。
3、计算 P(y1|x), P(y2|x), ...,P(yn|x)。(其中计算第3步是关键,详细算法见第四大点)
4、如果 P(yk|x)=max{P(y1|x), P(y2|x), ...,P(yn|x)},则x∈yk。
二、朴素贝叶斯分类实际应用举例
假如有两类水果,其名称及属性如下:
苹果(颜色、产地、价格、大小、销售旺季)
西瓜(颜色、产地、价格、大小、销售旺季)
以下各步分别对应第二大点的各个步骤,可以结合起来看
1、待分类项 x={红色、山东、3、小、12月}
2、现有已分类的类别集合 C={苹果、西瓜}
3、计算 P(苹果|{红色、山东、3、小、12月}) 和 P(西瓜|{红色、山东、3、小、12月})。
P(苹果|{红色、山东、3、小、12月})的意思是:
现有一种水果,它是红色的,产地在山东、零售价为3元、形状偏小、销售旺季在12月。
那么它是西瓜的概率为多少。
4、若P(苹果|{红色、山东、3、小、12月}) = max{P(苹果|{红色、山东、3、小、12月}),P(西瓜|{红色、山东、3、小、12月}) },
那么{红色、山东、3、小、12月}是苹果
四、分别计算P(y1|x),P(y2|x), ...,P(yn|x)
根据朴素贝叶斯有如下推理:

因为分母对于所有类别为常数,只需要将分子最大化:
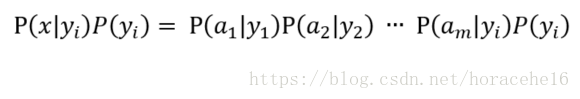
化简得如下公式:
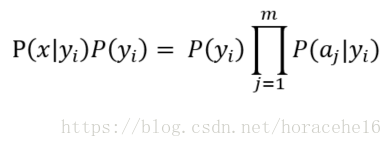
五、使用朴素贝叶斯分类的流程
1、训练数据生成训练样本集:TF-IDF。
2、对每个类别计算P(yi)。
3、对每个特征属性计算所有划分的条件概率。
4、对每个类别分别计算P(x|yi)p(yi)。
5、以P(x|yi)p(yi)的最大项作为x的所属类别。