DCA(Decision Curve Analysis)临床决策曲线是一种用于评价诊断模型诊断准确性的方法,在2006年由AndrewVickers博士创建,我们通常判断一个疾病喜欢使用ROC曲线的AUC值来判定模型的准确性,但ROC曲线通常是通过特异度和敏感度来评价,实际临床中我们还应该考虑,假阳性和假阴性对病人带来的影响,因此在DCA曲线中引入了阈概率和净获益的概念。
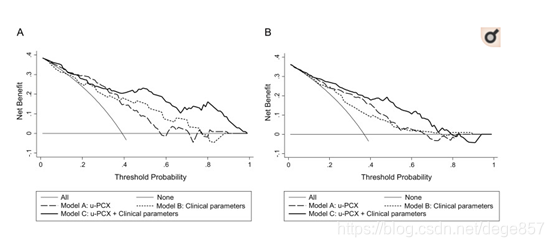
图片来源文章:Urinary Podocalyxin as a Biomarker to Diagnose Membranous Nephropath主要讲的是利用肾脏标志物uPCXμgg诊断膜性肾病的事。这幅图的横坐标为阈概率,纵坐标为净获益。当uPCXμgg达到某个值时,患者模型肾病的概率记为Pi;当Pi达某个阈值(记为Pt),就界定为阳性。
净获益的概念,净获益是指按此概率开展措施后,因操作而获益的比例+ 未获益的比例权重。决策曲线中净获益的算法如下:(表格来源:临床流行病学和循证医学)

下面我们通过一个具体的四格表来看一下决策曲线分析的基本计算,假设阈值概率为10%,得到如下四格表(表格来源:临床流行病学和循证医学):
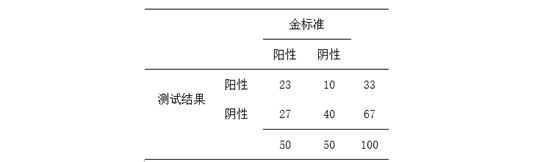
按照上面的10%的阈值去判断,我们判断对了23人,我们判断错了10人。这时候我们的净获益=(23/100)- [(10/100)(0.1/0.9)]=0.218。同样我们可以计算当阈值概率为11%时的净获益值,也可以计算12%时的净获益值。依此类推,我们便可以获得阈值概率和净获益值的一一对应关系,还可以将此关系画成一个线图,便是决策曲线。
下面我们来使用R语言进行DCA曲线制作
在Urinary Podocalyxin as a Biomarker to Diagnose Membranous Nephropath文章中附带有作者自己的数据,因此我们使用作者的数据来制作一个DCA曲线。目前使用R语言制作DCA曲线需要rmda包,先要下载好,网上一些教程的DecisionCurve包和stdca包已经被R官方下架了,正常途径下载不到了,rmda包的制作DCA曲线的代码和DecisionCurve包几乎是一样的。
我们先使用R语言导入数据看看
数据很多,这些只是其中一部分的数据,但是作者只用到了MN(膜性肾病)age(年龄)+eGFR(肾小球滤过率)+DM(糖尿病)+uPCXμgg(肾脏标志物)这几个指标
作者制作模型前把年龄和肾小球滤过率都除以10,这里我们也要处理一下
be$age1<-be$age/10
be$eGFR1<-be$eGFR/10
作者制作了3个模型uPCX(单用肾脏标志物),clinicalparameters(单用临床指标),all(标志物+临床指标)
我们也和他一样分别制作3个模型
uPCX<- decision_curve(MN~uPCXμgg,data = be,
family = binomial(link ='logit'),#模型类型,这里是二分类
thresholds= seq(0,1, by = 0.01),
confidence.intervals =0.95,#95可信区间
study.design = 'cohort')#研究类型,这里是队列研究
同理制作其他两个模型
clinicalparameters<- decision_curve(MN~age1+eGFR1+DM,data = be, family = binomial(link ='logit'),
thresholds= seq(0,1, by = 0.01),
confidence.intervals =0.95,study.design ='cohort')
all<- decision_curve(MN~age1+eGFR1+DM+uPCXμgg,data = be,
family = binomial(link='logit'),
thresholds= seq(0,1, by = 0.01),
confidence.intervals =0.95,study.design ='cohort')
使用LIST函数把3个模型连起来
List<-list(uPCX,clinicalparameters,all)
最后画图
plot_decision_curve(List,curve.names= c('uPCX','clinicalparameters','all'),
cost.benefit.axis =FALSE,col = c('red','blue','green'),
confidence.intervals =FALSE,standardize = FALSE)
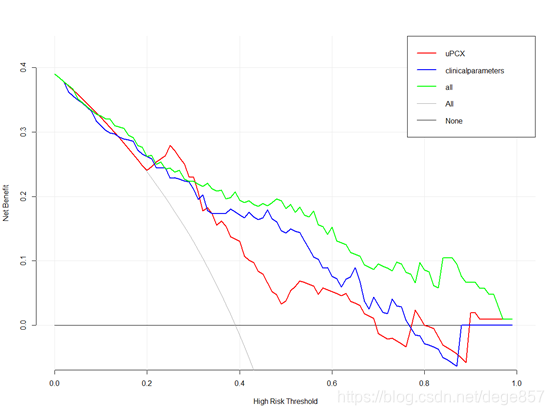
图形出来了,和作者制作的图一模一样,图中两条虚线,斜线那条代表全是阳性的情况,横的那条代表全是阴性的情况,我们的模型一定要高于全是阳性的斜线,否则就没什么意义了。我们可以看到在0.45-0.6的阈概率之间ALL模型的净获益明显高于其他两个模型。
其实很简单,您做出来了吗?需要零基础学习SPSS的朋友可以关注我们的科研教程
参考文献
- Imaizumi T, Nakatochi M, Akiyama S, et al. Urinary Podocalyxin as a Biomarker to Diagnose Membranous Nephropathy. PLoS One. 2016;11(9):e0163507. Published 2016 Sep 26. doi:10.1371/journal.pone.0163507
- ROC曲线老了,快来围观新晋小生DCA曲线https://mp.weixin.qq.com/s/Wb7OGteSrEJENVfeDFJ82g
- 决策曲线分析简介https://www.iikx.com/news/statistics/1622.html
